


Языковые эксперементы
7 постов
7 постов

23 поста
2 поста

3 поста
![Хайку код[т]](http://s15.pikabu.ru/images/series/2024/09/10/1725922956197399959.png)
7 постов
Предыдущая статья: Включения действий при разборе и итог пройденных тем в vk.com
Статья для повторения: От перепутья к перепутью, часть вторая: Разбор языка арифметики
В привычной нами записи выражения, знак операции (далее оператор) записываются между значениями (далее операндами):
а + б
Такая форма называется инфиксной (калька - вкрепной).
Так же используется префиксная (докрепная) запись, когда операторы пишутся до операндов:
+ а б
и постфиксная (закрепная) запись, когда операторы пишутся за операндами:
а б +
Ниже показаны ещё примеры:

Префиксная и постфиксная запись также именуются прямая и обратная польская нотация (далее ОПН), в честь её изобретателя польского логика Яна Лукасевича. Отличительная их черта, то что в них не используются скобки для обособления вычисления.
Используем рекурсивный спуск по рассмотренной нами грамматике, где в качестве чисел целые без знака:
Грамматика с унарным минусом и плюсом:
Г: В -> ДС
С -> ε | +ДС | -ДС
Д -> РП | -Д | +Д
П -> ε | *РП | /РП
Р -> ч | (В)
Звенья цепочки ОПН опишем набором трёх типов:
1. Операнд - целые числа.
2. Одноместный оператор - однооп, это унарный минус и плюс.
3. Двуместный оператор - двуоп, это минус, плюс, умножить, делить.
Ниже представлено полное описание звена ОПН:

Соберём звенья в список, который будет представлять нашу ОПН. Для этого отметим 3 действия на отделах рисунка порядка:
Д1 - Создать хрон. Переменная хранящая звено до момента добавления в список.
Д2 - Запомнить. Помещаем встреченное звено в хрон.
Д3 - Добавить. Записываем в список ОПН.
Ниже показаны отделы и процедуры со встроенными действиями в разбор:
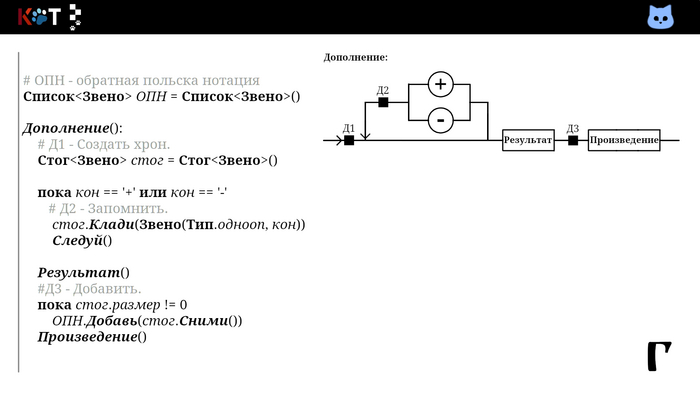
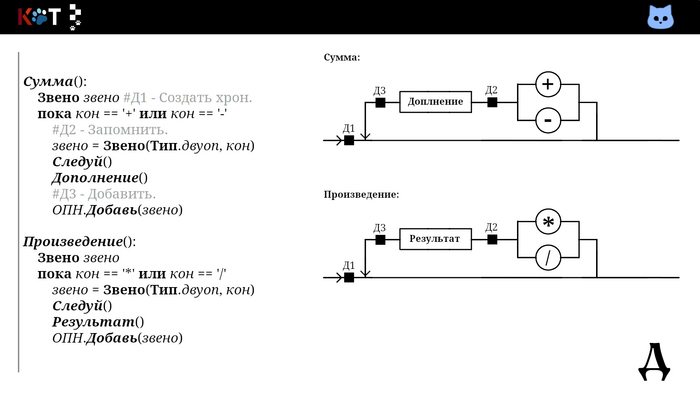
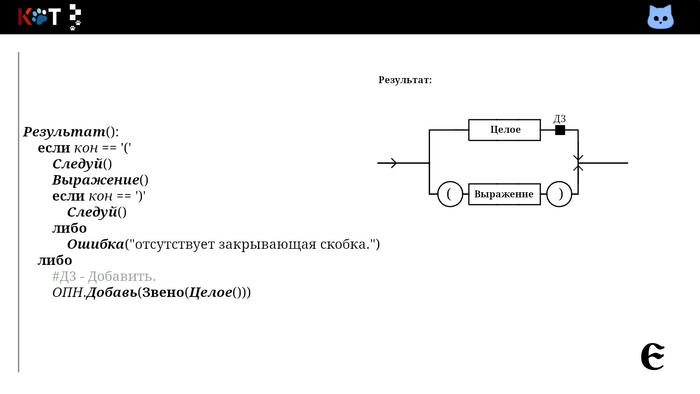
Так мы добавляем в первую очередь операнды, затем операторы в порядке их приоритетов. Всмотритесь в процедуру «Дополнениее». В качестве хрона используется стог (англ. stack), так как запоминаются несколько знаков сразу, их следует вспомнить в обратном порядке.
Осмыслим следующее: рекурсивный разборщик выступает теперь не только в качестве распознавателя, но и переводчика. Ведь мы получили цепочку принадлежащую другому формальному языку, который можно описать так:
Грамматика обратной польской нотации:
Г:В -> ч | П`П
П`-> чПО
П -> ВОП | ε
где:
В - ВЫРАЖЕНИЕ
О - ОПЕРАТОР
П - ПРАВОЕ_ПОДВЫРАЖЕНИЕ
П`- ПОДВЫРАЖЕНИЕ
ч - ЧИСЛО
Остановитесь на минутку, осмыслите.
Ниже изображена схема устройства вычисления ОПН - Стог-машина (Stack machine), а на следующем её описание. Для примера использована ОПН:
1 2 3 * + 4 -
Которая получена из инфиксной записи:
1 + 2 * 3 - 4


Стог-машина состоит из:
Стога - в котором хранятся промежуточные значения.
Набора двухместных и одноместных операций.
Движка - который читает ОПН, управляет стогом и обращается к набору операций.
ОПН обладает свойством: действия применяются последовательно при её чтении, на чём и основана работа стог-машины:
Если звено операнд, то кладём число в стог.
Если звено однооп, снимаем верхнее число обрабатываем, итог кладём в стог.
Если звено двуоп, снимаем два верхних числа и применяем операцию. Причём первое значение операции - второе верхнее, а второе - первое верхнее. Итог кладём в стог.
По окончанию чтения ОПН, итог вычисления оказывается на дне стога, одним.
Не стоит думать, что рассмотренный способ единственный для получения ОПН. Есть так же алгоритм Дейкстры перевода выражения в ОПН, но я не знаю стоит ли его разобрать или сразу перейти к обсуждению включения действий в «Провидца», ранее нами рассматриваемого.
Поэтому решение будет зависить от вас:

Ну на это всё, быть добру, хорошего настроения. Подписывайся. =)
Точно! Для любознательных и внимательных читателей, ещё одна не позиционная система счисления.
Флексить - устроить движ, хвастаться.
Тейк - аргумент.
Митап - встреча (в узком смысле, встреча по интересам)
Скил - способность.
Чекинить - регистрировать, фиксировать, отметить.
Изи -легко.
Фейлить - лажать, ошибаться.
Какие вы сегодня услышали?
![Почему нужно записывать [А-яЁё], но не [А-я]? Программирование, Регулярные выражения, Юмор, Печаль, Загадка, Русский язык](https://cs15.pikabu.ru/post_img/2024/09/10/0/1725917092184629795.jpg)
Почему буквы расположены в таком порядке? Почему в Unicode, не создали отдельно по упорядоченному алфавиту, для каждого же языка места хватает? Это такая шутка?
Рофл - Шутка, смех**чка.
Кринж - стыд,
Абьюз - использование.
Шейм - осуждение.
Коворкинг - сотрудничество.
Коливинг - сожительство.
Кейс - случай, пример.
Коллабарация - предательство, собрание.
Тим-лид - князь глава, лидер команды (Лидком? Ладно, это вопрос рофл.)
Поридж - овсянка.
Спик - мова, язык.
Скейлить - масштабировать, увеличивать.
Ротейтить - поворачивать, вертеть.
Рандомный - произвольный, случайный.
Юзать - использовать.
Апдейтить - обновлять.
Чек-лист - сверка по списку.
Что ещё добавить? Пишите.
UPD:
Тред - нить.
Вотэбаутизм - какнасчётизм.
Вдруг кому пригодится для объяснения другу, коллеге или ещё кому.
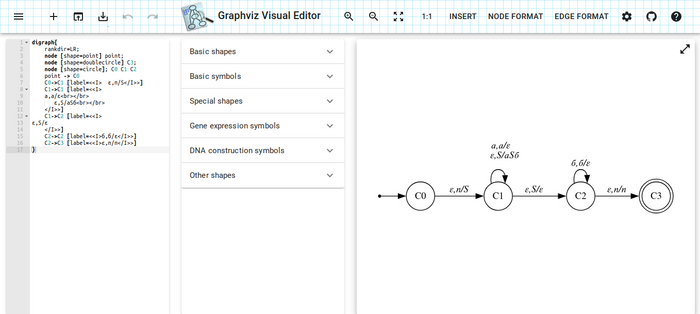
Вот такой полезный web-инструмент. Изображение можно выгружать в формате SVG.
Предыдущая статья: Ещё раз об однозначности грамматики, о дереве вывода, а так же о главном признаке КС-грамматики в vk.com
Статья для повторения:Задача разбора, для чего она нужна? Или что такое parsing? в vk.com
Вспомним о характере разбора цепочки. Стоит ли кость на своём месте при её постановке? Если постоянно да, то наш алгоритм предопределённый, в противном случае нам следует делать возвраты и пробовать подставить иную кость. Возможно узнать принадлежность цепочки заданной длинны, хотя бы из тех соображений, что можно построить все предложения (сентенции) грамматики совпадающие по длине с этой цепочкой.
Такой алгоритм работает по принципу полного перебора, для организации перебора используют стэк (англ. stack - рус. стог) - структуру данных по принципу «последним вошёл, первым ушёл». Полный перебор крайне неэффективен и на практике, как правило, не применяется.
Но! Есть широкий подкласс КС-грамматик, для которых накладывается ряд ограничений, что позволяет нам обходится без полного перебора и использовать эффективные алгоритмы распознавания, которые мы будем рассматривать в следующих уроках.
Если для автоматных грамматик в качестве распознавателя используется конечный автомат, то для КС-грамматик используется автомат с магазинной памятью.
Здесь нужно остановится на понятии «магазинная память», которое использовано крайне не удачно. По идее у вас должна быть выстроена ассоциация с магазином АК-47 (или другого оружия), где пуля заряженная последней, выстреливается первой. Но дело в том, что само слово магазин обозначает просто склад и он не обязательно должен выстроен по вышеуказанному принципу, лично я вовсе подумал о продуктовом. Поэтому используем термин стог-память или просто стог, так как если из стога вытащить что-то не сверху он превратится в кучу.
Перед тем как дать формальное описание, мы сперва построим простой стог-автомат. Отобразим общее представление об автомате:
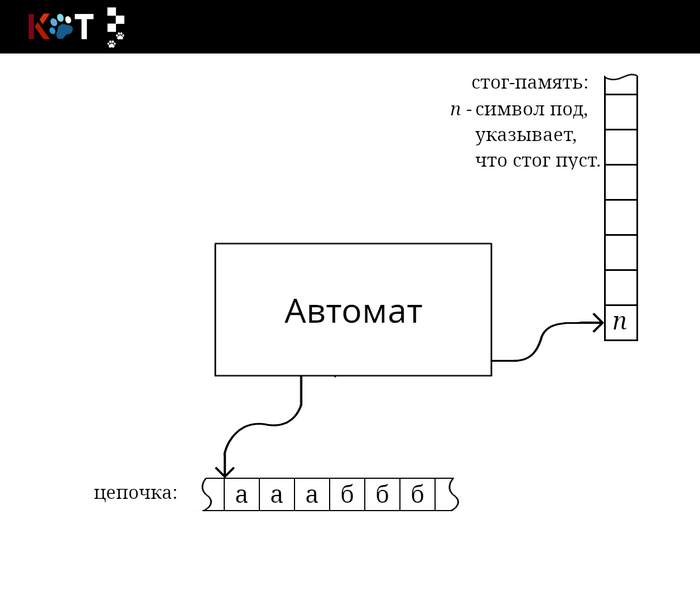
Общее представление стог-автомата.
Мы видим, что автомат обращается за чтением цепочки и за чтением из стог-памяти, в стог вложен отдельный символом п обозначающий под или дно. Внутреннее устройство автомата можно представить в виде направленного графа как и конечный автомат (далее КА), только для перехода из состояния в новое состояние направленное ребро помечается по мимо принимающего символа, верхней цепочкой символов стога, которая будет заменена на новую цепочку символов в обратном порядке по очереди («первым вошёл, первым ушёл»), также входит в метку:
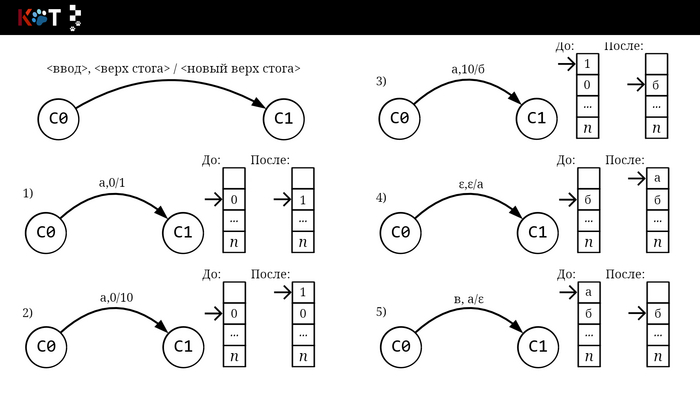
Переходы и стог.
Выше приведены примеры переходов с отображением операций над стогом. Первых три примера прозрачны, считали символ и поменяли цепочки. В 4 и 5 используется пустая цепочка ε и здесь нужно пояснение. Между любыми двумя символами всегда лежит пустая цепочка , что является причинной почему КА с ε-переходами недетерминирован. Проверьте, зайдите https://regex101.com/, введите любой текст и регуляр (), вы получите кучу совпадений. В стог-автомате ε используется в целях внутренней работы без считывания символа принимаемой цепочки, выталкивания и помещения символов из/в стог(-а), ведь пустота означает, что нечего брать или класть.
Изобразим граф стог-автомата принимающего язык:
Я = {аⁿбⁿ | n >= 0}, где в цепочках символы а и б повторяются в равном количестве, примеры { аб, аабб, аааббб, …}.
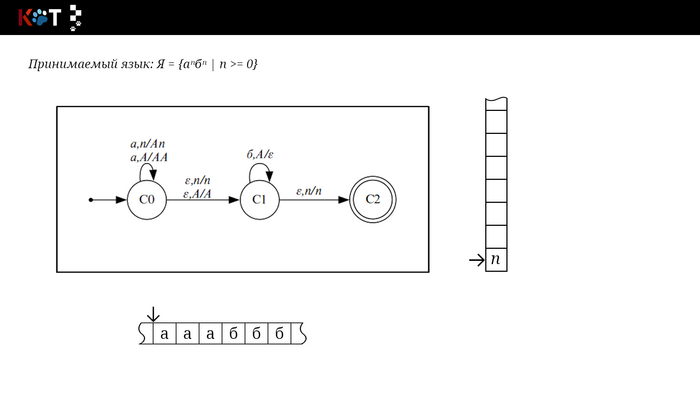
Стог-автомат.
Так же как в КА конечное состояние автомата обозначаем узлом с двойным кружком, а начальное просто стрелкой. Для того, чтобы не изображать лишних рёбер правила переходов записывают друг над другом. Формально данный стог-автомат записывается так:
М = ({С0, С1, С2},{а,б}, {А. п}, δ, С0, п, {C2})
Теперь мы готовы к общему формальному описанию, приступим:
M = {Q, Σ, Γ, δ, q0, Ζ, F}
F - множество конечных (принимающих) состояний автомата, наше {C2}.
Ζ - символ конца стога, наш п - символ под.
q0 - начальное состояние автомата, наше С0.
δ - функция переходов автомата δ: ( Q × (Σ ∪ {ε}) × Γ) → (Q × Γ*).
Γ - алфавит стога, наше {А, п}.
Σ - входной алфавит, наше {а,б}.
Q - множество состояний автомата, наше {С0, С1, С2}.
Остановимся на функции переходов δ: ( Q × (Σ ∪ {ε}) × Γ) → (Q × Γ*), она нам говорит о том, что переход зависит от текущего состояния Q, от принимаемого символа Σ с возможностью его оставить в покое ε и от верха стога Γ, в замен мы получаем новое состояние Q и новое содержимое стога Γ*. Γ* - звездочка обозначает, что наше множество разрастаемое, то есть стог заполняется символами.
Для дальнейшего объяснения предоставляю работу автомата того же языка, но построенный по его грамматике:
G: S → aSб | ε
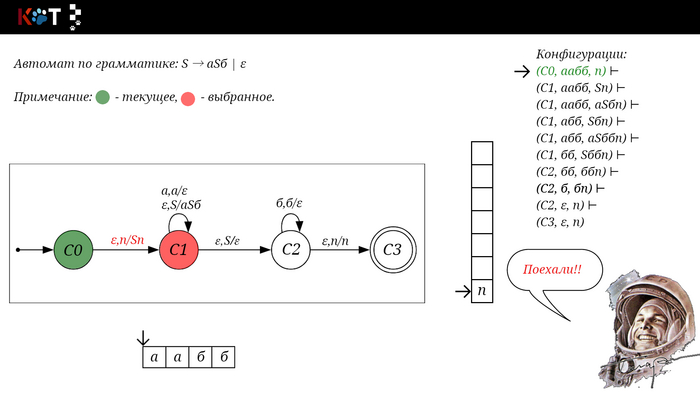
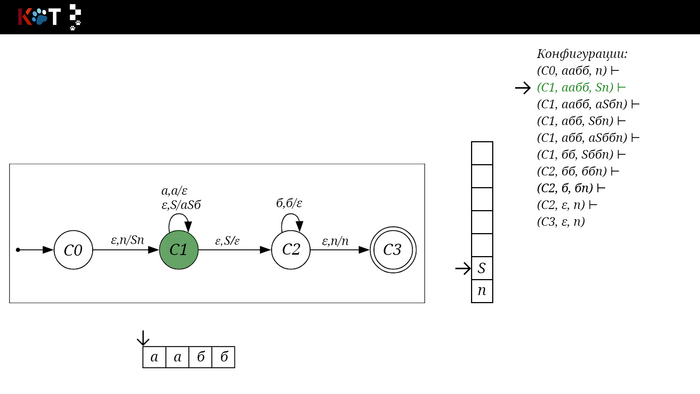
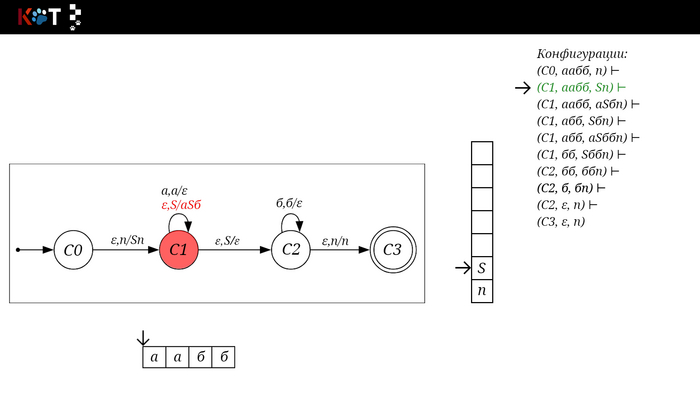
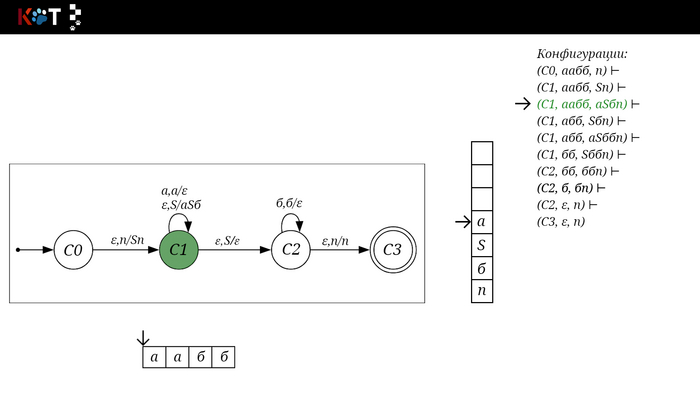
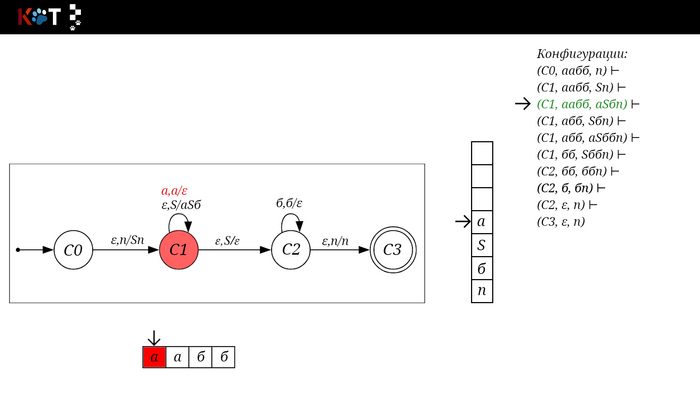
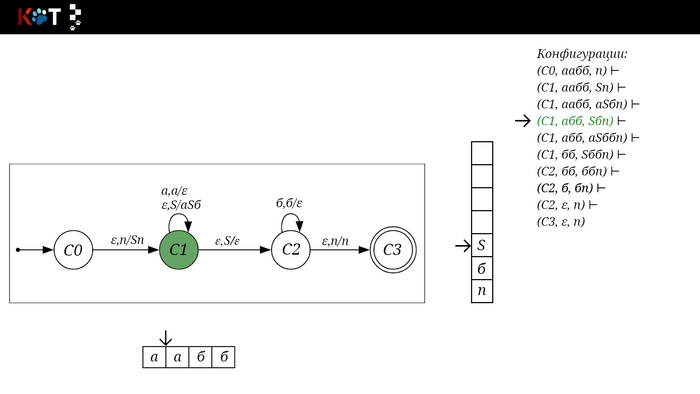
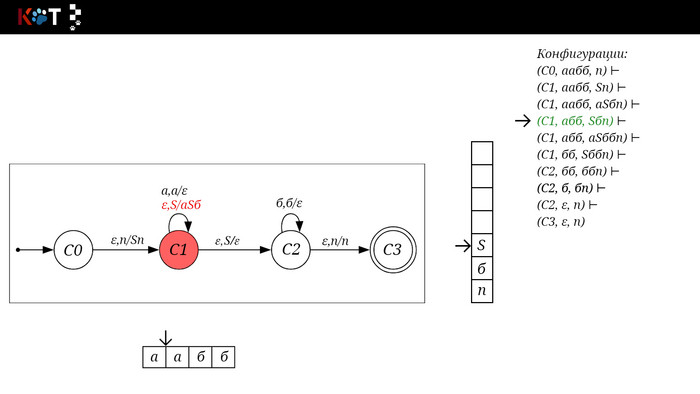
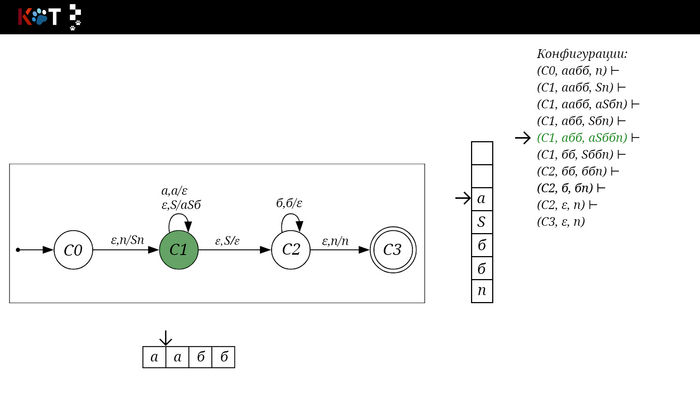
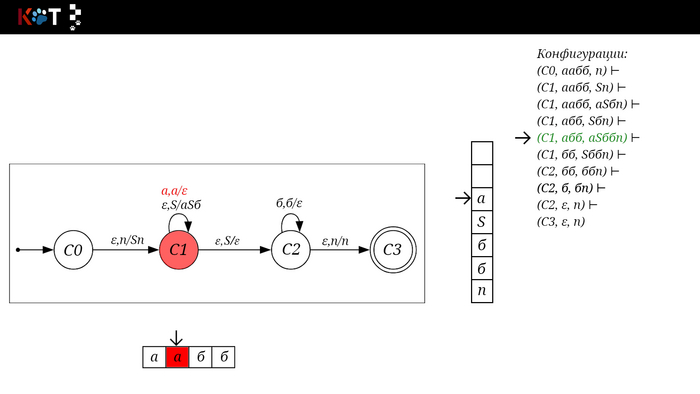
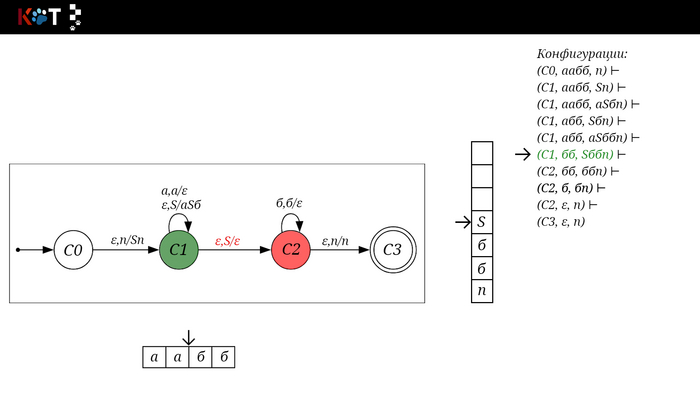
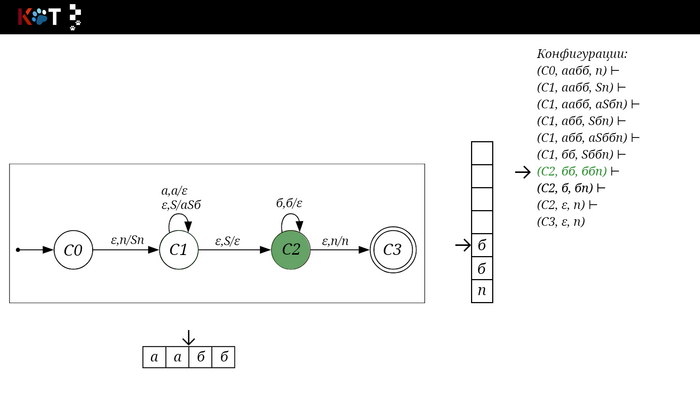
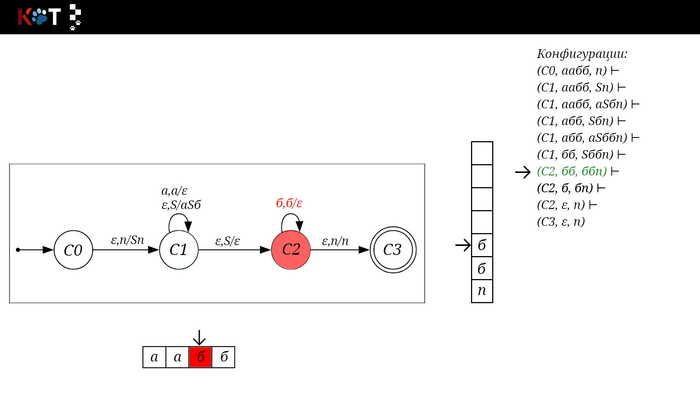
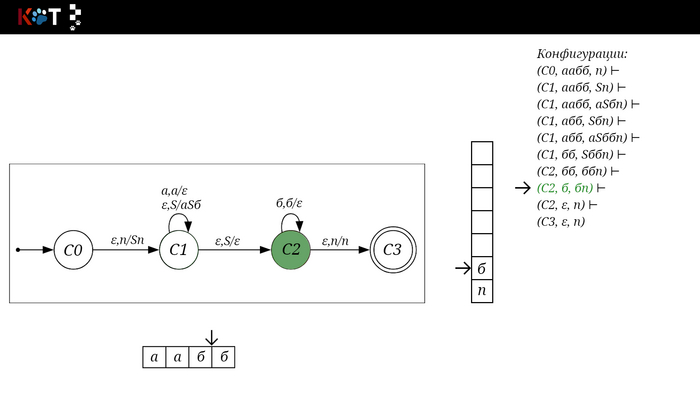
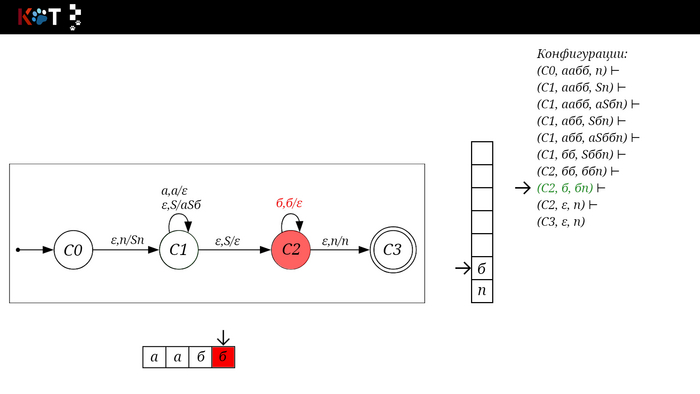
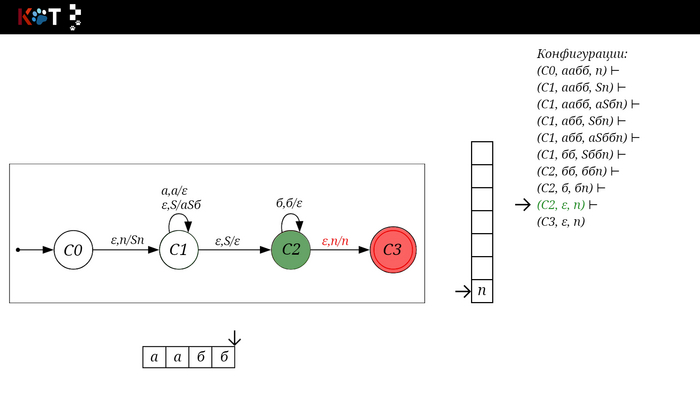
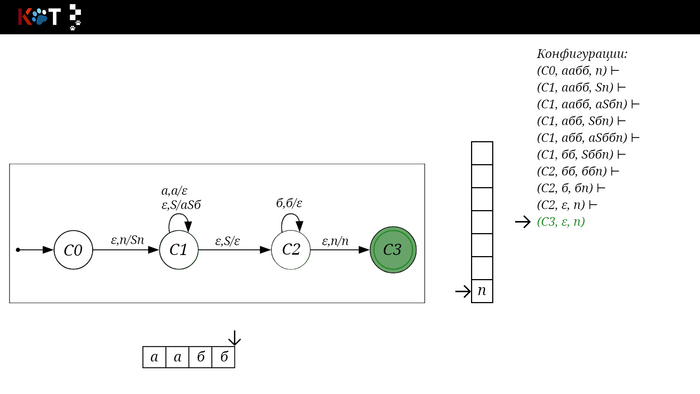
Поехали!! Листай!
На рисунке отображено, ещё не рассмотренное нами понятие конфигурации. Конфигурация представляет из себя набор (q, ω, γ), где q - текущее состояние, ω - цепочка ещё не рассмотренных символов, γ - содержимое стога. Символом ⊢ обозначают такт автомата, то есть переход из одной конфигурации в другую. Обозначим символом ⊢* последовательность ноль и более тактов, теперь мы можем описать условие принятия цепочки или допускаемый язык автомата:
L(M) = {ω ∈ Σ* и (q0, ω, Z) ⊢* (q, ε, Z), где q ∈ F} - то, есть когда наш стог опустошился до пода, завершился в конечном состоянии, а так же вся входная цепочка прочитана полностью. Лично у меня остался вопрос, почему везде записывают принятие по пустому стогу так:
L(M) = {ω ∈ Σ* и (q0, ω, Z) ⊢* (q, ε, ε,) где q ∈ F} - ведь никто не извлекает Z?
Так же существует соглашение условия принятия:
L(M) = {ω ∈ Σ* и (q0, ω, Z) ⊢* (q, ε, γ), где q ∈ F, γ ∈ Γ*} - то, есть когда наша цепочка полностью прочитана и мы достигли конечного состояния, а в стоге остались символы. Если мы уберём состояние С3, а С2 сделаем конечным, то становится понятно почему, такое соглашение есть.
Так же автомат можно описать таблицей, вот наш случай:
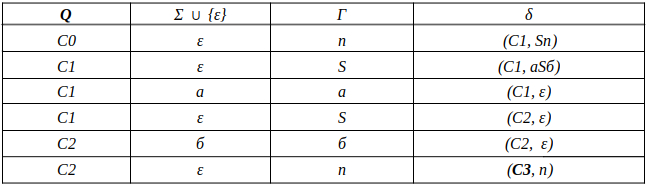
Таблица автомата.
В заключении следует сказать:
Для произвольной КС-грамматики можно построить недетерминированный автомат с магазинной памятью (стог-памятью), принимающий язык, порождаемый этой грамматикой.
Возможно построить и детерминированный, как отмечалось раньше, для этого грамматикам накладываются некоторые ограничения, о которых будет рассказано в других уроках.
Постскриптум: Очень сильно надеюсь, что изложил тему доступным языком. Будьте мне здоровы, подписывайтесь.
https://www.baeldung.com/cs/virtual-memory-vs-swap-space - вот здесь можете почитать подробнее.
Виртуальная память - это это так называемое виртуальное адресное пространство и оно может быть осуществлено и без swap-раздела (Linux) или swap-файла (Windows), так как в действительности многим процессам не требуется занимать полностью всю физическую память то, что ты назвал оперативной памятью, что в принципе так и есть, только физическое её воплощение.
Благодаря виртуальной памяти ты всегда получаешь дамп-памяти процесса в случае ошибки с одними и теми же адресами, они относительны для выполняемого процесса. Операционная система симулирует её для процессов, выделяя каждому сегменты Hello "segmentation fault" (страницы) физической памяти и пересчитывает их относительные адреса в физические для доступа к значениям, когда тем выделяется отрезок (квант) времени выполнения. Таким образом каждый процесс считает, что ему принадлежит вся физическая память и даже больше.
Вопрос же возникает, что делать, когда вся физическая оперативная память израсходована? Ничего не остаётся, кроме как выгружать страницы на жёсткий (или какие там сейчас появились?) диск, вот для этого и нужен swap-раздел(файл). Хотя есть ещё некоторые функции у него, знатоки могут написать в комментариях.
Виртуальная память существует и без внешнего накопителя, жёсткого диска.
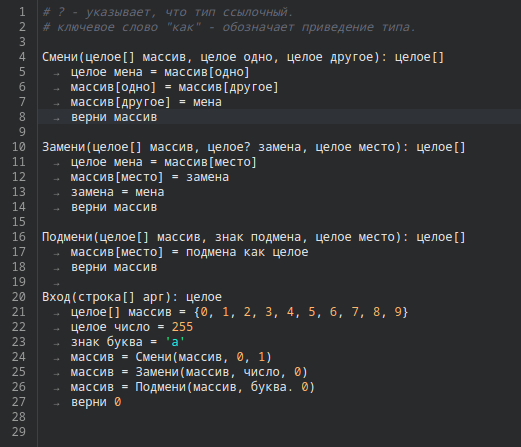
В чём ошибка?


