

Языковые эксперементы
7 постов
7 постов
2 поста

3 поста

23 поста
![Хайку код[т]](http://s15.pikabu.ru/images/series/2024/09/10/1725922956197399959.png)
7 постов
Предыдущая статья: Включения действий при разборе и итог пройденных тем в vk.com
Статья для повторения: От перепутья к перепутью, часть вторая: Разбор языка арифметики
В привычной нами записи выражения, знак операции (далее оператор) записываются между значениями (далее операндами):
а + б
Такая форма называется инфиксной (калька - вкрепной).
Так же используется префиксная (докрепная) запись, когда операторы пишутся до операндов:
+ а б
и постфиксная (закрепная) запись, когда операторы пишутся за операндами:
а б +
Ниже показаны ещё примеры:

Префиксная и постфиксная запись также именуются прямая и обратная польская нотация (далее ОПН), в честь её изобретателя польского логика Яна Лукасевича. Отличительная их черта, то что в них не используются скобки для обособления вычисления.
Используем рекурсивный спуск по рассмотренной нами грамматике, где в качестве чисел целые без знака:
Грамматика с унарным минусом и плюсом:
Г: В -> ДС
С -> ε | +ДС | -ДС
Д -> РП | -Д | +Д
П -> ε | *РП | /РП
Р -> ч | (В)
Звенья цепочки ОПН опишем набором трёх типов:
1. Операнд - целые числа.
2. Одноместный оператор - однооп, это унарный минус и плюс.
3. Двуместный оператор - двуоп, это минус, плюс, умножить, делить.
Ниже представлено полное описание звена ОПН:

Соберём звенья в список, который будет представлять нашу ОПН. Для этого отметим 3 действия на отделах рисунка порядка:
Д1 - Создать хрон. Переменная хранящая звено до момента добавления в список.
Д2 - Запомнить. Помещаем встреченное звено в хрон.
Д3 - Добавить. Записываем в список ОПН.
Ниже показаны отделы и процедуры со встроенными действиями в разбор:
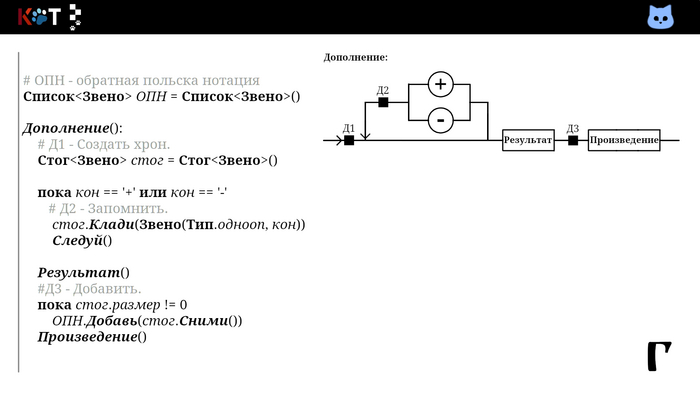
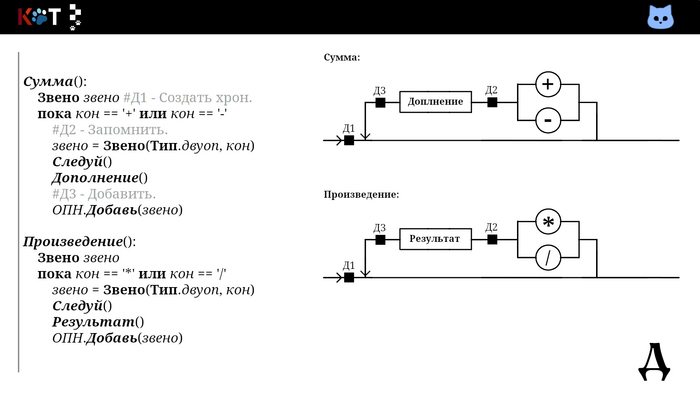
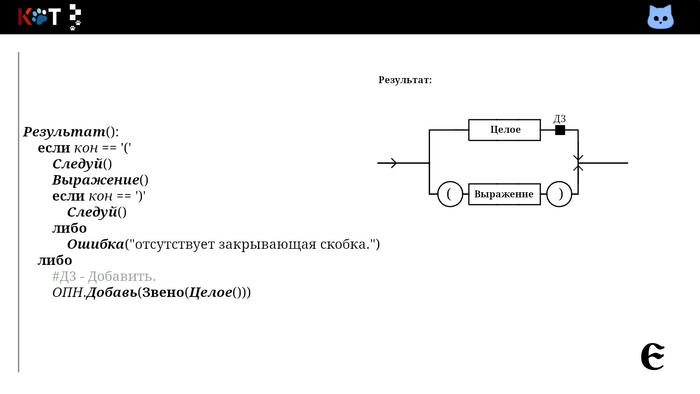
Так мы добавляем в первую очередь операнды, затем операторы в порядке их приоритетов. Всмотритесь в процедуру «Дополнениее». В качестве хрона используется стог (англ. stack), так как запоминаются несколько знаков сразу, их следует вспомнить в обратном порядке.
Осмыслим следующее: рекурсивный разборщик выступает теперь не только в качестве распознавателя, но и переводчика. Ведь мы получили цепочку принадлежащую другому формальному языку, который можно описать так:
Грамматика обратной польской нотации:
Г:В -> ч | П`П
П`-> чПО
П -> ВОП | ε
где:
В - ВЫРАЖЕНИЕ
О - ОПЕРАТОР
П - ПРАВОЕ_ПОДВЫРАЖЕНИЕ
П`- ПОДВЫРАЖЕНИЕ
ч - ЧИСЛО
Остановитесь на минутку, осмыслите.
Ниже изображена схема устройства вычисления ОПН - Стог-машина (Stack machine), а на следующем её описание. Для примера использована ОПН:
1 2 3 * + 4 -
Которая получена из инфиксной записи:
1 + 2 * 3 - 4


Стог-машина состоит из:
Стога - в котором хранятся промежуточные значения.
Набора двухместных и одноместных операций.
Движка - который читает ОПН, управляет стогом и обращается к набору операций.
ОПН обладает свойством: действия применяются последовательно при её чтении, на чём и основана работа стог-машины:
Если звено операнд, то кладём число в стог.
Если звено однооп, снимаем верхнее число обрабатываем, итог кладём в стог.
Если звено двуоп, снимаем два верхних числа и применяем операцию. Причём первое значение операции - второе верхнее, а второе - первое верхнее. Итог кладём в стог.
По окончанию чтения ОПН, итог вычисления оказывается на дне стога, одним.
Не стоит думать, что рассмотренный способ единственный для получения ОПН. Есть так же алгоритм Дейкстры перевода выражения в ОПН, но я не знаю стоит ли его разобрать или сразу перейти к обсуждению включения действий в «Провидца», ранее нами рассматриваемого.
Поэтому решение будет зависить от вас:

Ну на это всё, быть добру, хорошего настроения. Подписывайся. =)
Точно! Для любознательных и внимательных читателей, ещё одна не позиционная система счисления.
Предыдущая статья: Грамматика языка и порождающие грамматики. Сказ о «правильных» скобочках.
Напомню как выглядит формула порождающей грамматики: G = { T, N, P, S }
И чтобы проще было запомнить Grammar = { Terminal, Nonteminal, Production rule, Starting nonterminal} или как это выглядело бы на русском по определениям из прошлой статьи Грамматика = { Основные, Вспомогательные, Правила вывода, Начальный вспомогательный } или Г = { О, В, П, Н } или буквальный перевод Грамматика = { Конечные, Неконечные, Правила производства, Стартовый неконечный}, тогда Г = {К, Н, П, С}. Какой бы вариант вы выбрали? Можете оставить в комментариях.
Центральная идея об иерархиях заключается в том, какими правилами вывода мы пользуемся для описания языка, и вот на какие типы разделил Хомски :
Произвольные грамматики вида a → b , где a и b цепочки из основных и и/или вспомогательных (терминалов и/или нетерминалов) символов, причем цепочка а не должна быть пустой, более никаких ограничений не накладывается.
Контекстно-зависимые грамматики (КЗ-грамматика) вида aAb → ayb , где a, b, y — цепочки основных и/или вспомогательных символов. A — вспомогательный символ. Это правило гласит, что вспомогательный символ A, может быть заменен на цепочку y, только в контексте образуемом цепочками a и b.
Контекстно-свободные грамматики (КС-грамматика) вида A → y , где A вспомогательный символ, а y цепочка вспомогательный и/или основных символов. Основная особенно, то что в левой части правила, всегда только один вспомогательный символ.
Автоматные грамматики. Все правила такой грамматики имеют одну из трех форм: A → aB, A → a, A → ε , напомню что ε - это пустая цепочка.
Если вы достаточно внимательны, то можете заметить, что автоматные грамматики частный случай КС-грамматик, КС-грамматики частный случай КЗ-грамматик, КЗ-грамматики частный случай произвольных и когда говорят к примеру о КС-грамматике, говорят о грамматике не являющиеся автоматной. Фух…
Сейчас вам могут показаться эти определения абсолютно бесполезными, но они нам помогут понять конечный автомат, и в основном я буду писать о КС-грамматиках и автоматных, так как в основном они имеют практический интерес. Но перед обсуждением КА нам понадобится разобрать 2 темы, дерево вывода и задачи разбора (да, да парсинг), для чего они нужны что они такое.
З. Ы. Какому типу грамматик относится G = ( {(, )}, {S}, {S → (S), S →SS, S → ε}, S)?
Всем здоровья и улыбайтесь по чаще.
Предыдущая статья: Что такое язык программирования? Не спешим отвечать, знакомимся с определением формальных языков.
Небольшое добавление к предыдущей статье. Запись языка над алфавитом Σ принято записывать так:
L(Σ) = { α, …}
Поставим задачу описать язык «правильных» скобочек, то есть множество всех цепочек, где наши любимые рунетом цепочки символов ))))))))) без открывающих скобочек не входит в этот язык, эх … (((((((((, ну и закрывающих. Но мы то знаем какие «правильные»?
Ваши предложения? Не спешите читать дальше, подумайте, как бы вы это записали? Вот как раз на этот вопрос и отвечает грамматика, потому как она и есть способ описания формального языка, чтобы не путаться с ребятами из другого факультета, говорят о формальной грамматике, но мы опустим этот момент.
Давайте знакомится с формулой порождающей грамматики:
G = (T, N, P, S) - теперь по порядку, что есть что.
Т и N - это алфавиты, Т - основных символов их ещё называют терминалами, а N - вспомогательных символов, нетерминалы.
Немного о значении слова терминал, от лат. terminus — предел, конец.
P - конечное множество правил вывода (переходов), вида: α → β, где α и β цепочки из символов алфавитов Т и N.
S - начальный нетерминал, с чего начинаются все выводы цепочек языка.
Уже появились мысли, как записать язык «правильных» скобочек?
Не мучайтесь, вот ответ: G = ( {(, )}, {S}, {S → (S), S →SS, S → ε}, S)
Пример вывода:
S => (S) => (SS) => ((S)(S)) => (()())
Результат вывода называют сентенцией (от sentence — предложение), то что может предложить наша грамматика.
Итого, таким образом с помощью нашей Gрамматики, мы можем вывести некое множество цепочек (предложений, сентенций) над алфавитом Т, которое составляет наш язык L(T).
А вот о типах грамматик, о тех что Хомски рассказывает, мы поговорим чуть позже. Чтожъ, мои милые братцы и сестрицы, а на том пока.
Что мы используем для записи языка? Верно буквы! Но мы воспользуемся более широким определением символ и под символом мы будем иметь в виду экземпляр из всего множества записей, такие как цифры, иероглифы и даже можем рассматривать отдельное служебное слово как символ, например int из языка C. Символ это некая неделимая запись изображения, звука и прочего.
Из набора конечного количества символов составляется алфавит и обозначают его заглавной греческой буквой Σ (сигма).
Примеры алфавитов:
Σ₁ = {0, 1}
Σ₂ = {а, б, в}
Σ₃ = {А, Б, В, …, Я, а, б, в, …, я, 0, 1, …, 9, +, -, пока, …, если}
Алфавит это множество и как принято в математике множество записывается в фигурных скобках. Алфавит Σ₁ имеет два символа, Σ₂ -три, Σ₃ - алфавит некоторого языка программирования которые использует служебные слова из русского языка.
Но ведь язык не заканчивается просто алфавитом? Для более точного понимания вводится понятие цепочки. Так же вы можете встретить понятие слово в других источниках, что в прочем будет тождественно цепочки, в данном контексте.
Цепочка над алфавитом Σ это произвольная конечная последовательность символов из Σ.
Цепочки обозначим греческими буквами. Примеры цепочек над алфавитом Σ₂:
α = аббва
β = аб
γ = ба
δ = в
Пустая цепочка — цепочка, не содержащая символов, ни одного символа. Обозначаем буквой ε.
Теперь воспользуемся нашей буквой Σ, но уже для обозначения множества цепочек.
Σ = {α, αγ, β, δ, δ⁴, ε}
Запись αγ обозначает склеивание (конкатенацию), добавление символов цепочки γ к символам цепочки α справа.
Степень в записи δ⁴ означает кол-во повторений символов цепочки δ, т. е δ⁴ = вввв.
Теперь мы можем дать определение формальному языку:
Формальным языком над алфавитом Σ называется произвольное множество цепочек, составленных из символов Σ.
Затем делаем запрос в поисковой системе находим определение языка программирования:
Язы́к программи́рования — формальный язык, предназначенный для записи компьютерных программ. Язык программирования определяет набор лексических, синтаксических и семантических правил, определяющих внешний вид программы и действия, которые выполнит исполнитель (обычно — ЭВМ) под её управлением.
Ну хоть с первым предложением разобрались. А дальше я пока всё, буду узнавать что такое порождающая грамматика Хомски (Чомски, Chomsky).

