"Яндекс" в партнерстве с девелопером MR Group запускает пилотный проект в жилом комплексе Slava в Москве, где голосовой помощник "Алиса" не просто включает музыку, а управляет домофоном, видеонаблюдением, шлагбаумом и выдает гостевые пропуска.
По сути, "Алиса" становится цифровым консьержем. Отличный пример сокращения низкопроизводительных рабочих мест! Проект реализуется через платформу Ujin, а цель амбициозная – занять до трети рынка цифровых решений в новостройках уже к 2030 году. Рынок немаленький – порядка 20 млрд рублей. И это только начало: в июне стартует отдельный проект по интеграции в дома вторичного жилья – через платформу "Наш дом" и оператора домофонов "Спутник".
Что это значит? Это значит, что цифровизация – больше не абстрактный лозунг, а реальность повседневной жизни. Интеграция голосовых помощников и цифровых платформ в жилую инфраструктуру – это шаг к технологически зрелой экономике, где рутинные функции, вроде выдачи пропусков или контроля доступа, переходят в ведение умных систем.
Это не только повышает уровень комфорта для жителей, но и оптимизирует ресурсы, высвобождая человеческий труд для более сложных и квалифицированных задач. Умные дома становятся не роскошью, а стандартом нового уклада, где ИТ-индустрия напрямую влияет на качество городской среды. Снижается зависимость от низкопроизводительных рабочих мест, а экономика делает ставку на автоматизацию, безопасность и высокотехнологичное развитие.
Еще больше интересных материалов в моем telegram-канале "Константин Двинский"
Не забываем ставить лайк :) Подписывайтесь, чтобы ничего не пропустить!
На всех конференциях - стандартный вопрос, по окончании практически любого доклада о очередном инструменте анализа производительности СУБД :
А как это влияет на производительность СУБД ?
С методологической точки зрения, вариантов использования сбора и анализа метрик производительности всего 2 :
Не использовать сбор и мониторинг метрик производительности СУБД и не иметь никакой достоверной информации о причинах изменения производительности СУБД. Зато - никакого влияния.
Использовать сбор метрик производительности СУБД, иметь информацию о причинах изменения производительности и учитывать влияние сбора метрик .
Или проще говоря
в первом случае: меньше знаешь - крепче спишь ,
во-втором : за все надо платить.
С точки зрения физики - СУБД не является исключением и эффект наблюдателя , конечно же имеет место и да, любой сбор метрик производительности СУБД - влияет на производительность СУБД .
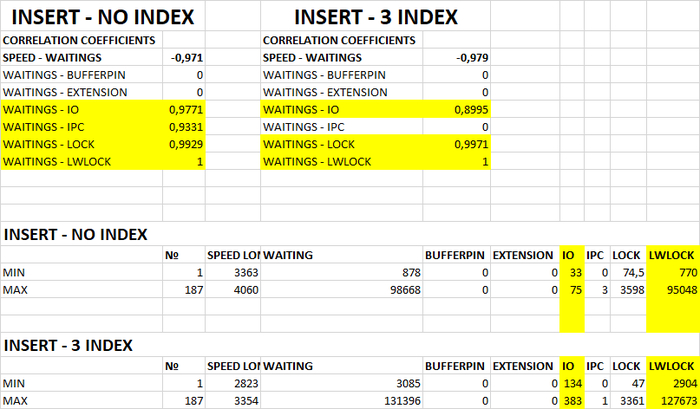
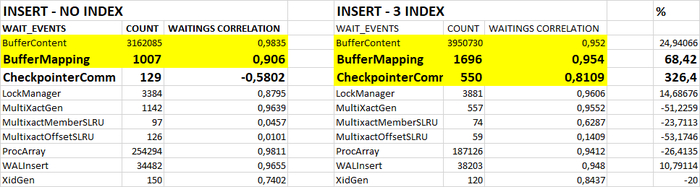
И это влияние можно оценить не только качественно но и количественно и обязательно нужно учитывать при анализе производительности СУБД:
Для лучшей скорости необходима настройка под конкретные условия трассы .
Задача
Определить качественное и количественное влияние на производительность тестовой СУБД изменения параметра checkpoint_timeout для сценария нагрузки "Mix".
checkpoint_timeout (integer)
Максимальное время между автоматическими контрольными точками в WAL. Если это значение задаётся без единиц измерения, оно считается заданным в секундах. Допускаются значения от 30 секунд до одного дня. Значение по умолчанию — пять минут (5min).
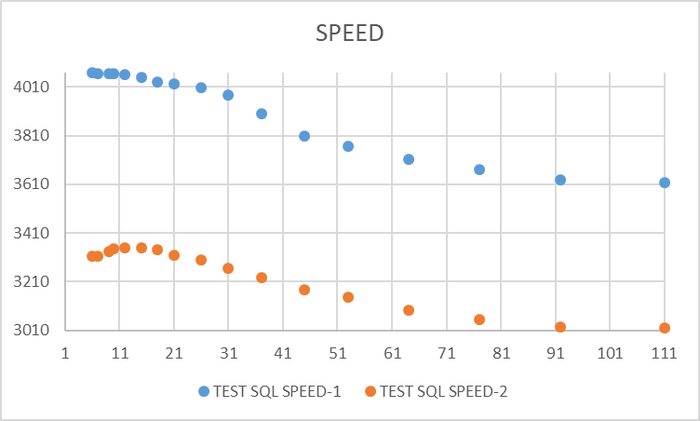
Ось X - общая нагрузка на СУБД. Ось Y - апроксимированные значения операционной скорости.
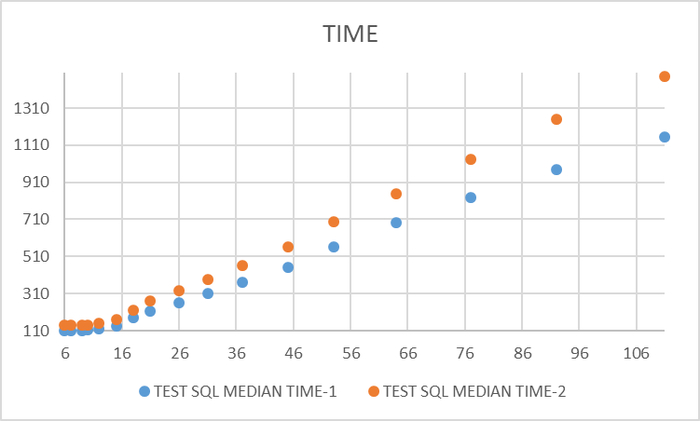
Ось X - общая нагрузка на СУБД. Ось Y - операционная скорость.
Итог:
Для данной СУБД в сценарии смешанной нагрузки "Mix":
Максимальная скорость СУБД достигается при значении параметра checkpoint_timeout = 60 при общей нагрузке 18 соединений.
Максимальная нагрузка , после которой скорость СУБД начинает снижаться достигается при значении параметра checkpoint_timeout = 300 при общей нагрузке 26 соединений.
При предельной общей нагрузке 111 соединений наибольшая скорость СУБД достигается при значении параметра checkpoint_timeout = 900.
Стало интересно - а как сейчас с материалами по статистическому анализу производительности СУБД ? Год назад - практически ничего, кроме пары статей 5ти летней давности по мат.статистике на Хабре, не было . По PostgreSQL - вообще ничего не было.
Пусть нейросеть поищет и проанализирует.
И ведь нашла и проанализировала и выдала осмысленный результат:
Как тут не вспомнить классику
Из 4х ключевых источников : 3 ссылки на мои статьи , а одна это вообще основная тема в течении прошедшего года. Скоро будет доклад на конференциях по данной тематике.
Тем, кто будет после меня заниматься темой статистического анализа производительности СУБД PostgreSQL , будет проще - материалы и фундамент для исследований и развития уже есть. И это хорошо. Надо развивать DBA из ремесла и алхимии в науку и инженерию.
Всем привет, работаю java разработчиком больше 10 лет. У написанного кода есть разные характеристики: производительность, читаемость, покрытие тестами, стоимость строки итд. Команды разработки могут управлять этими характеристиками в некоторых пределах. В этом посте хотел бы осветить вопрос оптимизации производительности.
Как мыть руки перед едой, программисту не приходится задумываться над небольшими оптимизациями, которые хорошо ложатся на модель данных, при этом имеют меньшую алгоритмическую сложность. Например, посетителей страницы соцсети представлять как множество, а не как список, потому что поиск по множеству происходит быстрее:
Иногда требуется подготовить данные, переложить их один раз, чтобы дальнейший поиск происходил быстрее - не сложный со стороны модели код, но требующий внимательности.
Сложнее обстоит дело с индексами в БД - есть инструменты чтобы выбрать правильные индексы, но этот вопрос нужно решать на месте. Не добавил индекс - будет медленное чтение, добавил индекс - медленная запись и повышенное потребление диска. Потребовалось добавить индекс на большом размере данных - нужно останавливать сервис.
Еще сложнее обстоит вопрос с настройкой ресурсов - какой размер пула потоков установить? Кто съел все коннекты к бд, почему повышенное потребление памяти? На этом этапе приходится подключать средства профилирования. Для получения воспроизводимого результата нужно иметь процедуру нагрузочного тестирования. Как будем мерять производительность - по пропускному потоку или по задержке?
Оптимизация производительности обычно бьет по читаемости кода, ведет к усложнению эксплуатации и внесении доработок. Идти на этот компромисс нужно, когда взвешены плюсы и минусы технического решения. В случае производительности - это фактические или предсказанные боттлнеки.
Начинающие разработчики зачастую пытаются необоснованно улучшать производительность за счёт других параметров, этот подход называется преждевременной оптимизацией. При этом они упускают из виду фактическую необходимость изменений, не понимают как будут измерять результат. Примеры таких решений:
перенести всю логику из java в sql (код админки, нагрузка ~100 запросов в день)
ускорить расчет закрытия предыдущего дня (при том что расчет не нуждался в ускорении)
использовать параллелизацию (что ломает компоненты, ориентированные на thread per request подход)
Общая рекомендация здесь такая - если вы не знаете, что делаете - лучше не делать ничего. Сделайте по-простому, и потом улучшайте там где вылезают самые острые проблемы. Желаю всем интересных задач и достойной оплаты!