


Новая задача по SQL
Всем привет! Очередная задача с моего Телеграм канала про SQL и базы данных!
Показать полностью
1
Всем привет! Очередная задача с моего Телеграм канала про SQL и базы данных!
Всем привет! Ещё один интересный вопрос с нашего Телеграм-канала про SQL и базы данных. Спасибо, что делитесь вопросами с собеседований!

▌ Возможности применения рекомендаций нейронных сетей для повышения производительности СУБД PostgreSQL
В последние годы широкое распространение получили методы машинного обучения, применяемые для решения задач анализа данных и автоматизации процессов принятия решений. В частности, одним из перспективных направлений является использование нейронных сетей (НС) для автоматического поиска оптимальных настроек параметров баз данных с целью улучшения их производительности.
СУБД PostgreSQL обладает большим количеством настраиваемых параметров, от правильного выбора которых зависит эффективность работы системы. Традиционные подходы предполагают проведение экспериментов или применение эмпирических правил («best practices»), что требует значительных временных затрат и высокой квалификации специалистов.
Нейронные сети позволяют автоматически выявлять взаимосвязи между параметрами базы данных и показателями ее производительности. Для этого необходимо собрать достаточный объем обучающих данных, включающий различные комбинации значений параметров и соответствующие им показатели времени выполнения запросов, загрузки процессора, объема потребляемой памяти и т.д.
После обучения НС способна генерировать рекомендации по настройке параметров PostgreSQL, минимизируя при этом время отклика и максимизируя пропускную способность системы. Однако следует учитывать ряд ограничений данного подхода:
- зависимость результатов от качества исходных данных;
- сложность интерпретации полученных рекомендаций;
- необходимость регулярного обновления модели вследствие изменения структуры и нагрузки на базу данных.
Таким образом, хотя нейронные сети представляют собой мощный инструмент для оптимизации производительности PostgreSQL, они не могут полностью заменить опыт экспертов и требуют осторожного использования совместно с традиционными методами настройки баз данных.
-------
💫 Создано с помощью GigaChat
Взято с основного технического канала Postgres DBA (возможны правки в исходной статье).

Общие принципы работы одинаковы, но размер имеет значение.
Проанализировать влияние размера и ресурсов СУБД на изменение производительности СУБД при агрессивной настройке autovacuum.
CPU = 2
RAM = 2GB
Размер тестовой БД = 10GB
Тестовая таблица ~60 000 000 строк
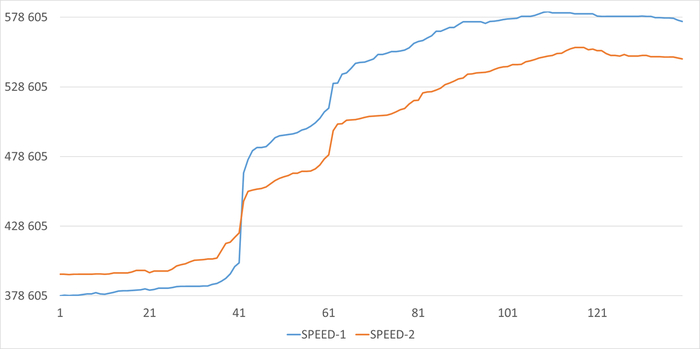
Ось X - точка наблюдения .Ось Y - операционная скорость
Средняя относительная разница операционной скорости в экспериментах 1 и 2 составила : -3%
Средняя относительная разница операционной скорости в экспериментах 1 и 2 составила : 4%
Средняя относительная разница операционной скорости в экспериментах 1 и 2 составила : -6%
CPU = 200
RAM = 1TB
Размер тестовой БД = 10TB
Тестовая таблица ~70 000 000 000 строк
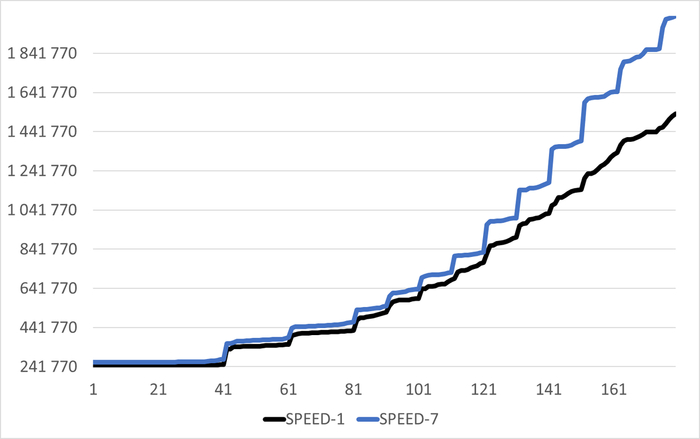
Ось X - точка наблюдения. Ось Y - операционная скорость
Средний прирост производительности в эксперименте-7 по сравнению с экспериментом-1 составил 13.30%
Максимальный прирост производительности в эксперименте-7 по сравнению с экспериментом-1 составил 35.83%
Для обеспечения эффективного обслуживания и повышения производительности СУБД необходимо запланировать ресурсы - в частности на выполнение регулярных операций autovacuum.

Может быть когда ни будь в будущем, нейросети и смогут реально помогать в экспериментах , пока лучше не доверять их ответам.
К вопросу о том, что нейросеть в обозримом будущем не может заменить инженера , обладающего данными экспериментов .
У нейросети просто нет экспериментальных данных, но проблема не в этом. Глобальная проблема нейросетей — выдача ответа в условиях недостатка данных.
Сказано уже 100500 раз — ВСЕ ОТВЕТЫ НЕЙРОСЕТИ НУЖНО ПРОВЕРЯТЬ ЭКСПЕРЕМЕНТАЛЬНО, НИКАКОЙ ИНФОРМИИ НЕЙРОСЕТЕЙ ДОВЕРЯТЬ НЕЛЬЗЯ .
Статистически обработать огромные массивы информации — да, тут нейросеть поможет. Но, сделать исследования нового — тут нейросеть принципиально бессильна, у нее просто нет данных. А результат она выдает.
Оценить влияние кардинального снижения параметра хранения таблиц fillfactor c базового значения 100 до 50, при агрессивной настройке autovacuum.
Допустим какой-то продвинутый DBA ,

следующий в русле новых тенденций решил не тратить время и задал вопрос нейросети DeepSeek:
Как повлияет уменьшение параметра fillfactor c 100 до 50 для таблицы с количеством строк примерно 60000000 на количество и время работы autovacuum для СУБД PostgreSQL c ресурсами CPU=2 , RAM=2GB при интенсивных операциях SELECT + UPDATE примерно в среднем 1000 транзакций в секунду, при нагрузке от 5 до 48 одновременных сессиях, при агрессивных настройках autovacuum для тестовой таблицы : autovacuum_vacuum_scale_factor=0 и autovacuum_vacuum_threshold=1000 ?
Уменьшение параметра fillfactor с 100 до 50 для таблицы с 60 млн строк в PostgreSQL при указанных условиях существенно повлияет на работу autovacuum, преимущественно негативно. Вот анализ последствий:
1. Увеличение размера таблицы и фрагментации
Физический рост таблицы:
При fillfactor=50 каждая страница таблицы заполняется только на 50%, что удваивает её физический размер (с ~60 млн строк до эффективных ~120 млн страниц). Это увеличит I/O-нагрузку и объём данных для обработки autovacuum.
Рост индексов:
Индексы также увеличатся, так как новые версии строк (от UPDATE) будут чаще размещаться в новых страницах (из-за нехватки места в исходных), что дополнительно нагрузит autovacuum.
2. Частота запуска autovacuum
Агрессивные настройки:
autovacuum_vacuum_threshold=1000 и autovacuum_vacuum_scale_factor=0 означают, что autovacuum запускается после каждых 1000 изменений (UPDATE/DELETE).
Интенсивность UPDATE:
При 1000 транзакций/сек (часть из которых — UPDATE) порог в 1000 изменений будет достигаться каждую секунду. Это приведёт к почти непрерывной работе autovacuum.
3. Время работы autovacuum
Увеличение длительности циклов:
Autovacuum должен сканировать вдвое больше страниц (из-за fillfactor=50), что резко увеличит время каждого запуска. Например:
При fillfactor=100: сканирование 1 млн страниц.
При fillfactor=50: сканирование ~2 млн страниц.
Ресурсные ограничения:
Слабые ресурсы (2 CPU, 2 GB RAM) не позволят autovacuum справляться с возросшим объёмом. Нехватка памяти вызовет активное использование диска (I/O), замедляя процесс.
4. Проблемы из-за нехватки ресурсов
Конкуренция за I/O:
Autovacuum будет постоянно читать/писать данные на диск, конкурируя с пользовательскими запросами (SELECT/UPDATE). Это увеличит задержку транзакций.
Нехватка памяти:
Буферный кэш (shared_buffers) ограничен ~512 MB (25% от 2 GB RAM). Таблица размером > 2x не поместится в кэш, что вызовет чтение с диска и замедлит все операции.
Риск блокировок:
Длительные циклы autovacuum могут конфликтовать с пользовательскими транзакциями, особенно при 48 одновременных сессиях.
5. HOT-обновления: частичное смягчение
Преимущество fillfactor=50:
Свободное место в страницах может повысить долю HOT-обновлений (когда новые версии строк помещаются в ту же страницу). Это уменьшит фрагментацию и нагрузку на индексы.
Ограниченная польза:
На фоне удвоенного объёма таблицы и слабых ресурсов этот эффект не компенсирует общее снижение производительности.
6. Риск накопления dead tuples
Autovacuum может не успевать:
При такой частоте UPDATE и нехватке ресурсов autovacuum будет отставать от нагрузки. Это вызовет:
Рост dead tuples.
Увеличение I/O (из-за чтения "мертвых" строк).
Замедление SELECT (из-за необходимости фильтрации мёртвых версий).
Блот (bloat) таблицы и индексов.
Рекомендации
Не снижать fillfactor до 50 на такой конфигурации. Оптимально: fillfactor=80–90 (если требуются HOT-обновления).
Увеличить порог autovacuum:
Например, autovacuum_vacuum_threshold = 10000 (вместо 1000), чтобы сократить частоту запусков.
Вывод: Уменьшение fillfactor до 50 на маломощном сервере с агрессивным autovacuum вызовет хроническую нехватку ресурсов, рост времени вакуумирования и общее снижение производительности. Без увеличения RAM/CPU это изменение не рекомендуется.
«Вот оно как» — подумает продвинутый DBA , следующий в русле новых тенденций и не будет менять параметр fillfactor.
Другой инженер, якудза старой школы

не верит бездушным алгоритмам и решает проверить всё лично.
И приходит к очень интересным, и прямо противоположным результатам.
Для данной СУБД и данного сценария нагрузки , уменьшение параметра хранения таблиц на 50% c 100 до 50 , повысило эффективность работы autovacuum:
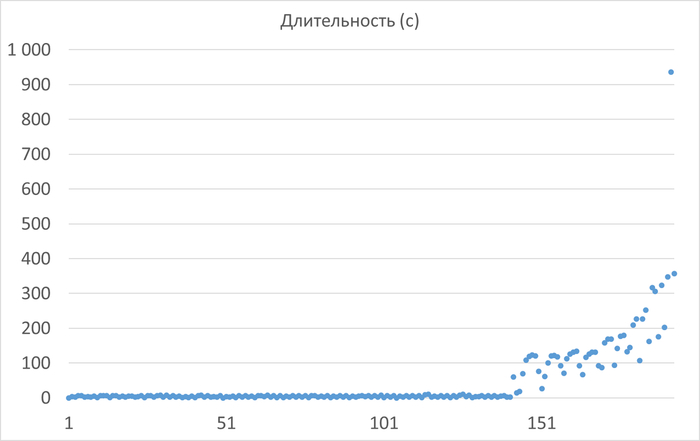
Количество запусков autovacuum увеличилось на 261% c 193 до 697
Максимальное время работы autovacuum уменьшилось на 29% с 936 сек. до 663 сек.
Среднее время работы autovacuum уменьшилось на 73% с 46 сек. до 12 сек.
Предельная нагрузка на autovacuum увеличивалась на 50% с 8 до 12 соединений.
Молодой DBA, следующий в русле новых тенденций и доверяющий математическим алгоритмам статистической обработки текстов — потерял шанс сильно улучшить работу одного из ключевых механизмов СУБД PostgreSQL — autovacuum.
Старый, тертый жизнью и не доверяющий новым веяниям DBA — получил конкретный полезный результат и запланировал новые эксперименты по оптимизации и настройке СУБД.
Взято с основного технического канала Postgres DBA (возможны правки в исходной статье).

Регулярная уборка это правильно .
Оценить влияние кардинального снижения параметра хранения таблиц fillfactor c базового значения 100 до 50, при агрессивной настройке autovacuum.
CPU = 2
RAM = 2GB
Версия СУБД:
Postgres Pro (enterprise certified) 15.8.1 on x86_64-pc-linux-gnu, compiled by gcc (AstraLinuxSE 8.3.0-6) 8.3.0, 64-bit
Размер тестовой БД = 10GB
Тестовая таблица ~60 000 000 строк
autovacuum_analyze_scale_factor 0.1
autovacuum_analyze_threshold 50
autovacuum_vacuum_cost_delay 2 ms
autovacuum_vacuum_cost_limit -1
autovacuum_vacuum_insert_scale_factor 0.2
autovacuum_vacuum_insert_threshold 1000
autovacuum_vacuum_scale_factor 0.2
autovacuum_vacuum_threshold 50
vacuum_cost_limit 2000
autovacuum_vacuum_scale_factor 0
autovacuum_vacuum_threshold 1000
autovacuum_analyze_scale_factor 0
autovacuum_analyze_threshold 1000
autovacuum_vacuum_insert_scale_factor 0
autovacuum_vacuum_insert_threshold 1000
autovacuum_vacuum_cost_delay 1
autovacuum_vacuum_cost_limit 2000

Ось X - итерация теста. Ось Y - количество одновременных сессий pgbench
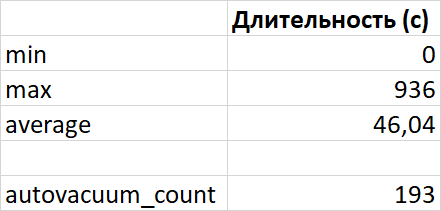
Ось X - точка завершения autovacuum. Ось Y - время выполнения autovacuum.
Нагрузка начала роста времени работы autovacuum = 8

Ось X - точка завершения autovacuum. Ось Y - время выполнения autovacuum.
Нагрузка начала роста времени работы autovacuum = 12
Для данной СУБД и данного сценария нагрузки , уменьшение параметра хранения таблиц на 50% c 100 до 50 , повысило эффективность работы autovacuum:
Количество запусков autovacuum увеличилось на 261% c 193 до 697
Максимальное время работы autovacuum уменьшилось на 29% с 936 сек. до 663 сек.
Среднее время работы autovacuum уменьшилось на 73% с 46 сек. до 12 сек.
Предельная нагрузка на autovacuum увеличивалась на 50% с 8 до 12 соединений.

Зри в корень (с)
Изменение параметров приводит к росту производительности СУБД
Рост производительности СУБД означает большее количество операций UPDATE в ходе нагрузочного тестирования
Принципиальное ограничение - производительность процесса autovacuum ограничена пропускной способности дисковой подсистемы.
Мертвые строки накапливаются быстрее, чем autovacuum успевает очищать
В случае стандартного режима работы , единственный выход - добавить регулярную очистку мертвых строк в период наименьшей нагрузки на СУБД.
В случае режима работы 24/7 - только архитектурное решение - не допускать роста таблиц до огромных размеров , для которых используется очень большое количество операций INSERT/UPDATE.
Взято с основного технического канала Postgres DBA (возможны правки в исходной статье).

Разобраться в работе сложного механизма - это очень интересно.
Проанализировать количественное влияние на производительность СУБД повышения агрессивности настройки autovacuum для очень большой таблицы .
CPU = 200
RAM = 1TB
DB Size = 10TB
Количество строк тестовой таблицы ~7 000 000 000
Сценарий нагрузки - смешанный ("Select only" + "Select + Update" + "Insert only")
Минимальная нагрузка = 5 сессий
Максимальная нагрузка = 115 сессии
ALTER TABLE pgbench_accounts SET (autovacuum_vacuum_scale_factor = 0);
ALTER TABLE pgbench_accounts SET (autovacuum_vacuum_threshold = 10000);
ALTER TABLE pgbench_accounts SET (autovacuum_analyze_scale_factor = 0);
ALTER TABLE pgbench_accounts SET (autovacuum_analyze_threshold = 10000);
ALTER TABLE pgbench_accounts SET (autovacuum_vacuum_insert_scale_factor = 0);
ALTER TABLE pgbench_accounts SET (autovacuum_vacuum_threshold = 10000);
ALTER TABLE pgbench_accounts SET (autovacuum_vacuum_cost_delay = 0);
Снижение граничного условия в 10 раз.
ALTER TABLE pgbench_accounts SET (autovacuum_vacuum_threshold = 1000);
ALTER TABLE pgbench_accounts SET (autovacuum_analyze_threshold = 1000);
ALTER TABLE pgbench_accounts SET (autovacuum_vacuum_threshold = 1000);

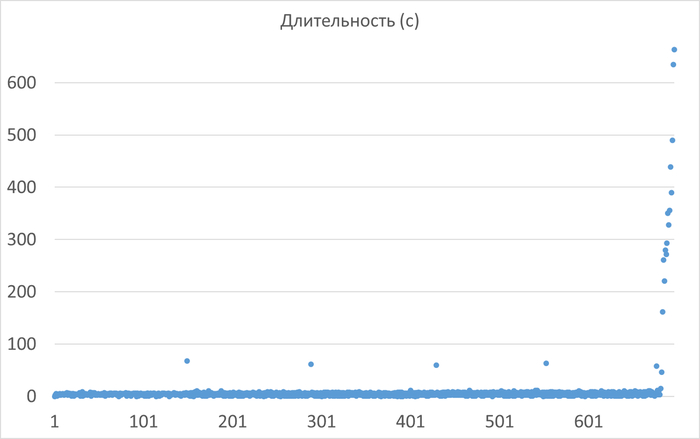
Ось X - точка наблюдения. Ось Y - операционная скорость

Ось X - точка наблюдения. Ось Y - относительная разница между скорости в эксперименте-10K и эксперименте-1K
Средний прирост производительности СУБД в эксперименте-1K = 9.5%

Сводная таблица предельных значений и корреляции ожиданий СУБД.

Ось X - точка наблюдения. Ось Y - ожидания СУБД

Ось X - точка наблюдения. Ось Y - относительная разница между количеством ожиданий в эксперименте-10K и эксперименте-1K
Среднее снижение количества ожиданий СУБД в эксперименте-1K = -4.51%
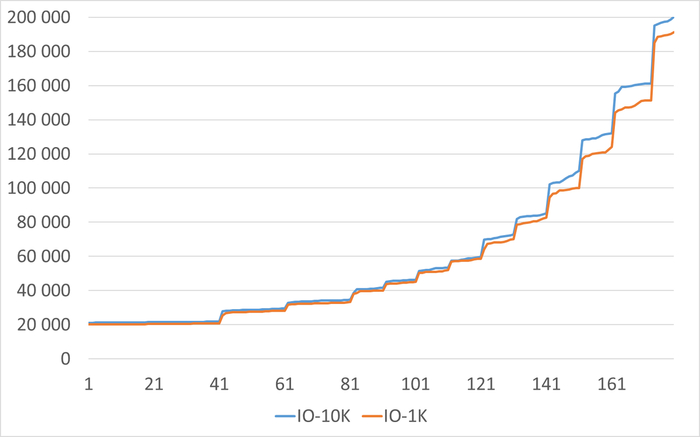
Ось X - точка наблюдения. Ось Y - ожидания СУБД типа IO

Ось X - точка наблюдения. Ось Y - относительная разница между количеством ожиданий в эксперименте-10K и эксперименте-1K
Среднее снижение количества ожиданий СУБД типа IO в эксперименте-1K = -4.51%

Ось X - точка наблюдения. Ось Y - ожидания СУБД типа IPC

Ось X - точка наблюдения. Ось Y - относительная разница между количеством ожиданий в эксперименте-10K и эксперименте-1K
Превышение ожиданий IPC в эксперименте-1K при нагрузке близкой к максимальной.
Среднее снижение количества ожиданий СУБД типа IPC в эксперименте-1K = -37.44%

Ось X - точка наблюдения. Ось Y - ожидания СУБД типа Lock
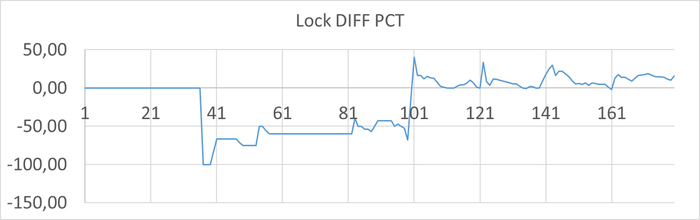
Ось X - точка наблюдения. Ось Y - относительная разница между количеством ожиданий в эксперименте-10K и эксперименте-1K
С ростом нагрузки ожидания Lock в эксперименте-1К начинают превышать ожидания в эксперименте-10K.
Среднее снижение количества ожиданий СУБД типа Lock в эксперименте-1K = -17.00%

Ось X - точка наблюдения. Ось Y - ожидания СУБД типа LWLock

Ось X - точка наблюдения. Ось Y - относительная разница между количеством ожиданий в эксперименте-10K и эксперименте-1K
В целом ожидания Lock в эксперименте-1К превышают ожидания в эксперименте-10K.
Среднее повышение количества ожиданий СУБД типа Lock в эксперименте-1K = 13.46%
Для данной СУБД и данного сценария синтетической нагрузки. При нагрузке на СУБД с 5 до 115 одновременных соединений :
Снижение граничного условия старта autovacuum с 10 000 до 1 000 мёртвых строк , приводит к повышению производительности в среднем до 9.5%.
Mаксимальный прирост производительности достигает 31%.
Корреляционный анализ ожиданий по тестовым сценариям, будет подготовлен позже.

