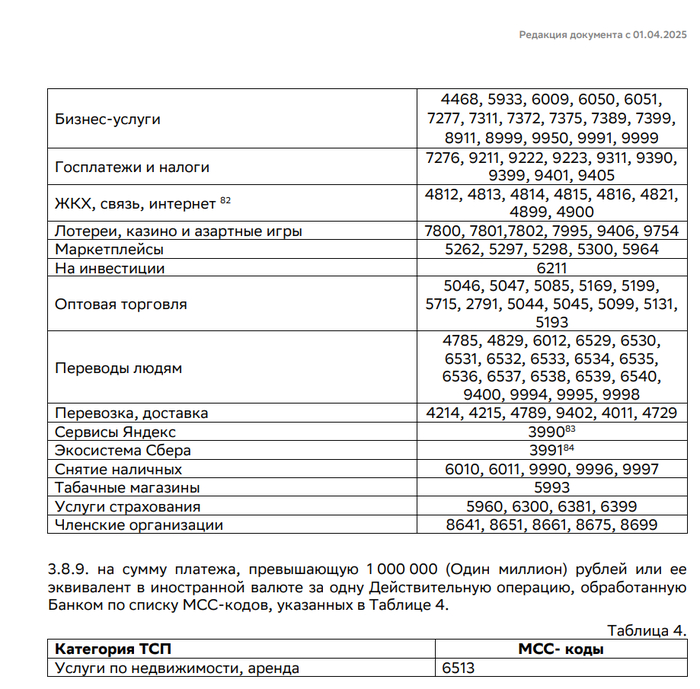
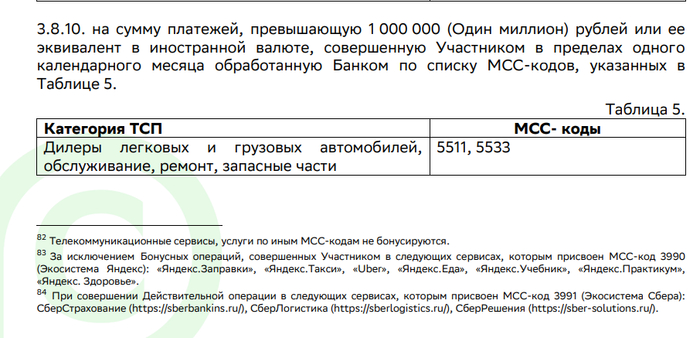
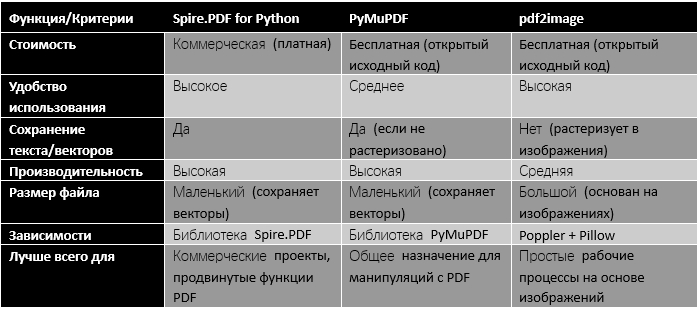
using System.IO;
using System.Text;
using Spire.Pdf;
using Spire.Pdf.Utilities;
namespace ExtractPdfTable
{
class Program
{
static void Main(string[] args)
{
// Создаем объект PdfDocument
PdfDocument doc = new PdfDocument();
// Загружаем образец PDF-файла
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\input.pdf");
// Создаем объект StringBuilder
StringBuilder builder = new StringBuilder();
// Инициализируем экземпляр класса PdfTableExtractor
PdfTableExtractor extractor = new PdfTableExtractor(doc);
// Объявляем массив PdfTable
PdfTable[] tableList = null;
// Извлекаем таблицы с конкретной страницы
tableList = extractor.ExtractTable(0);
// Проверяем, не является ли список таблиц нулевым
if (tableList != null && tableList.Length > 0)
{
// Перебираем таблицы в списке
foreach (PdfTable table in tableList)
{
// Получаем количество строк и столбцов определенной таблицы
int row = table.GetRowCount();
int column = table.GetColumnCount();
// Перебираем строки и столбцы
for (int i = 0; i < row; i++)
{
for (int j = 0; j < column; j++)
{
// Получаем текст из конкретной ячейки
string text = table.GetText(i, j);
// Добавляем текст в StringBuilder
builder.Append(text + " ");
}
builder.Append("\r\n");
}
}
}
// Записываем в .txt файл
File.WriteAllText("Table.txt", builder.ToString());
}
}
}