

Behavior-Driven Development отживает свое? Почему все отказываются от Cucumber
Когда-то Behavior-Driven Development задумывался как классная штука. Предполагалось, что с его помощью бизнес будет описывать, как должен работать продукт, тестировщики — добавлять корнер-кейсы («а что будет, если сделать шаг влево или вправо?»), а разработчики — писать код автотестов и делать продукты, которые эти тесты проходят.
Главный инструмент BDD — Cucumber — позволил автоматизировать тесты, описывая их на языке Gherkin и связывая эти описания с исполняемым кодом. В итоге должен был получаться результат, который устраивает и бизнес, и QA.
Но что-то пошло не так. Сегодня в адрес Cucumber все чаще можно услышать критику. Его создатель Аслак Хэллисей признал, что: «Большинство используют Cucumber не для BDD, а просто как инструмент тестирования. Если так, то он ничем не лучше других фреймворков».
Кто в этом виноват и что делать? Попробуем разобраться.

Что пошло не так
В идеальном Behavior-Driven Development-мире бизнес берет латте, садится рядом с тобой и вы долго и счастливо пишете сценарии вместе. В реальности же он тебя просто отшивает: «У нас нет времени разбираться в этих Given-When-Then. Главное, чтобы работало. А как — это ваши проблемы». В итоге вся фишка BDD — описание требований на общем языке — теряется.
Разработчики тоже не в восторге: Gherkin для них — это лишняя абстракция, которая только мешает. Каждый шаг в Gherkin требует реализации в коде. Вместо упрощения получается дополнительный слой — step definitions нужно писать, поддерживать и постоянно рефакторить. В итоге мы имеем 10 сценариев → 100 шагов → 500 строк кода, где 80% — это повторяющиеся вызовы.
Если команда тупо перекладывает готовые тест-кейсы в Gherkin, это лишняя работа, которая не имеет смысла.
Почему Cucumber не так хорош
Он тормозит. Высокоуровневые сценарии, особенно в UI-тестах, превращают CI/CD в ад. Каждый прогон ты сидишь и ждешь, когда же он доползет до конца.
Это темный лес. В реальных проектах сценарии не более информативны, чем код на незнакомом ЯП.
Это больно. Любое изменение в логике — и приходится переписывать шаги, а потом чинить тесты. А если у тебя несколько команд работают с одними и теми же сценариями — жди конфликтов.
Он хрупкий и жестко завязан на структуру. Нужно привыкать к нему и следить за реализацией «названий» шагов, чтобы правильно вызывать их в feature-файлах. Одно неосторожное движение — и все, тесты посыпались как карточный домик. Перефразировали текст в требованиях? Надо бегом править все фичи. Изменили селектор на фронте? Готовимся к падениям.
Он все усложняет. Он приносит еще один уровень абстракции, с которым нужно считаться при дебаге.

VLM все меняет
Можно ли сохранить удобство написания тест-кейсов в свободной форме, но при этом избавиться от жестких синтаксических правил? Похоже, что да. И ключом к этому решению должны стать vision-language модели (VLM) — мультимодальные нейросети, которые могут одновременно обрабатывать изображения и текстовые описания. Они принимают на вход скриншот интерфейса и описание не в жестко структурированной нотации и подготовленных фразах, а в естественных формулировках, понимают контекст и определяют, какой именно элемент соответствует этой инструкции.
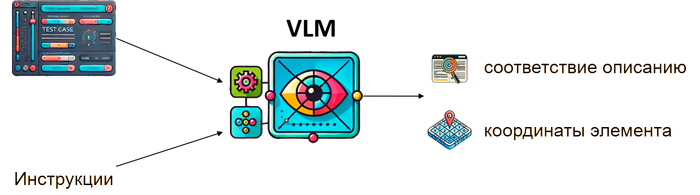
Недавно команда BugBuster внедрила этот подход, запустив ИИ-систему для управления тестированием.
Вот как это работает:
Описываешь действия за 5 минут. Просто пишешь тест-кейс на человеческом языке.
Запускаешь тест в один клик. Больше не нужно каждый день править селекторы из-за того, что фронтендер решил рефакторнуть верстку.
Получаешь результат через минуту. Пока ты идешь за кофе, система сама проверяет, что в корзину все добавилось, кнопки нажались, а формы отправились.
Хочешь попробовать? Бесплатный тест-драйв тут.







