2. Направление- аниме,дорамы,сериалы. 3. Нагрузка- 1-2 серии в неделю. 4. TO Bamboo - озвучка и перевод 5. Панды общий сбор.
В нашу команду нужны ребята которые хотят заниматся фандаббом и привносить что то свое.
Кого мы ищем?
Дабберы(Дикторы)( парни и девушки) Таймеры-звукари(Очень сильно их ищем и нуждаемся) Переводчки Релизеры на сайт Дизайнеров
Что нужно? ПК или ноут для всех Возраст от 18 лет для всех Свободное время для всех Дабберам(Дикторы) конденсаторный микрофон, программы Reaper и Aegisubs Таймерам-звукарям владение плагинами и программа Reaper Переводчики программа Aegisubs и владением языком от B1-2 Релизерам свободное место на ЖД или ССД и скоростной интернет Дизайнерам программа Photoshop или аналог, графический планшет(опционально)
Проект некомерческий.
Все анкеты можно присылать либо в лс группы TO Bamboo - озвучка и перевод либо в обсуждении группы в спецтеме. vk.com/bambooteam Пусть Бамбук приведет нас к лучшему. Всем Бу.
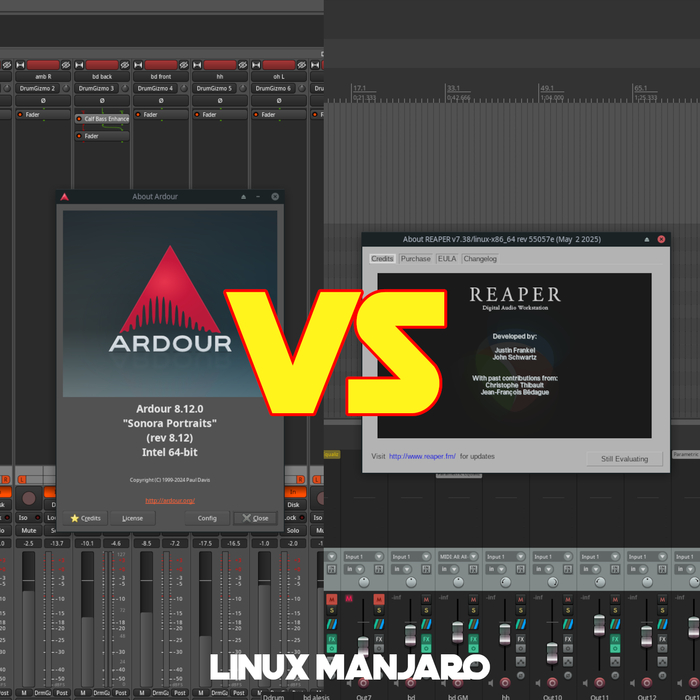
Для интересующихся #Linux 'ом и #DAW для него. В общем так: Ardour - 1 серьёзный вылет с потерей проекта + мелкие, но не периодические косяки. Опыт около 10 лет. От обновления к обновлению ошибки и вылеты уменьшаются. Reaper - регулярные вылеты, не все плагины для Linux поддерживаются. Но ни одного проекта не потеряно (стоит оговориться, что в нём была только 1 серьёзная работа - Москва 2078). Опыт в линухе - около полугода. От обновления к обновлению качество работы не меняется. По удобству интерфейса секвенсоры для меня ± одинаковые. Ardour, наверное, в итоге выигрывает. Спасибоу за внимание.
которым я делаю из записей плохого качества чёткое звучание.
Для ЛЛ: компрессор/лимитер + добавление высоких частот + вырезание лишних звуков.
Итак, погнали.
Я это делаю в программе Audacity 3.4.2. Но вы можете использовать любую другую на ваш выбор.
Примечание: если запись сделана издалека, если на фоне много шума, если в микрофон попадает воздух - это вам не поможет. Это применимо для относительно чистых записей.
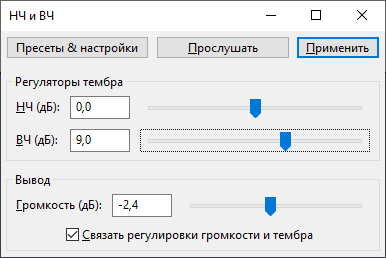
1. Открываем какую-нибудь запись в аудио редакторе, можете для примера взять голосовое сообщение из Telegram или VK. 2. Меню Эффекты, НЧ/ВЧ. 3. Добавляем ВЧ на 15 - 25 % (по вкусу) и уже получаем намного бОльшую чёткость.
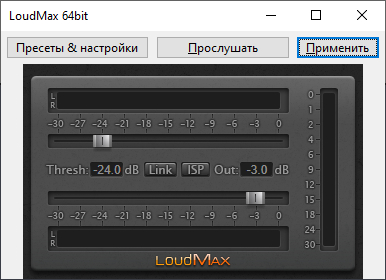
Отлично, с этим разобрались. Что делать, если запись звучит тихо, а обычное усиление или компрессор не дают желаемого результата? Раньше это было огромной проблемой. Но сейчас... Появился такой VST плагин, под названием LoudMax. Это находка, меняющая всю жизнь! Итак. Качаем его отсюда выбирайте свою ОС, скорее всего Windows). Кладите DLL-ку в вашу папку, где находятся VST. Обычно это одно из: - "C:\Program Files\Vstplugins" - "C:\Program Files\Common Files\VST3" Если таких папок нет - значит ни одного плагина в системе не установлено. Можете или создать такую папку, положить туда DLL-ку, затем вручную в настройках редактора указать путь, где искать, ведь записей в реестре не будет об этом, либо положить сразу в папку plugin самого редактора, например: "C:\Program Files\Audacity\Plug-Ins"
.
Надеюсь, с установкой разобрались. Ну тогда открываем нашу запись, выделяем всё и включаем этот эффект. Порог около 25, выход около -3, подбирайте сами.
Теперь, что делать с дыханием и лишними звуками?
До компрессии, в самом начале Можете воспользоваться шлюзом шума (noise gate), в Audacity он встроен, а если вы пользуйтесь чем-то другим, то возьмите, например, отсюда. Но он может съедать тихие окончания, например, однажды я так сделал и из слова "eyes" он вырезал букву "s", получилось "eye". И эти вырезки могут быть резкими.
Я выделяю вручную. Аккуратно по милли секундам (если что, поменяйте масштаб в меню Вид) выделяем промежутки тишины между словами и в меню Правка нажимаем пункт "Заменить тишиной". Сочетание CTRL+L. Если тишина не нужна, то удалить звук CTRL+K. Тогда будет сдвиг по времени. Важно, если сводите инструментал с вокалом. Чтобы сдвига по времени не было используйте "Заменить тишиной".
Можете комбинировать нойс гейт + ручная вырезка.
По краям можете добавить фейды, чтобы было мягче.
И всё, готово. Получите, распишитесь, вы сделали почти студийную запись.
P.S. Я не профессионал, ни где этому не учился, ни на каких курсах, чисто сам, лично один до этого дошёл. У вас может быть другое мнение, я лишь написал, как делаю сам и это нравится тем, кому я делаю.
Здравствуйте, дамы и господа, моя проблема может показаться для кого-то банальной, но все же хотелось услышать ваши советы по решению вопроса, не так давно я записал несколько видео с прохождением одной игры (Devour если кому интересно) и хотел бы из всего записанного материала сделать нарезку, но столкнулся с одной проблемой, а именно рассинхронизация аудио и видео дорожек.
В чем дело я понял, причиной этого стало то, что видеоряд имеет не постоянный ФПС, который бывал варьировался в разных диапазонах, что можно наглядно увидеть в свойствах самих видео.
Для решения этой проблемы я использовал конвертер, чтобы задать постоянный ФПС своему видео, но столкнулся со следующей проблемой - потеря качества видеоряда.
Видео до конвертации. Все хорошо, черный цвет имеет плавный переход, а картинка четкая.
Видео после конвертации. Видны резкие переходы черного цвета, а сама картинка стала слегка размытым.
Теперь стоит вопрос, какой конвертер лучше использовать? Я перепробовал HandBrake, Convertilla, Movavi (самое лучшее из списка, но сейчас в триале ставится водяной знак) и Adobe Media Encoder. Может конечно, всем дело во мне и я не разобрался в настройках, поэтому и получается на выходе такая каша, но все же, хотелось слушать ваши варианты.
По возможности, чтобы в программе можно было бы конвертировать видео с разделенными аудио дорожками.
Озвучка диалогов из текста может сильно упростить и ускорить работу во многих ситуациях: подкасты, аудиокниги, обучающие материалы, рекламные ролики, создание игр, reels и даже фильмов.
Часто записать аудио крайне трудно: нет доступа к микрофону, шумная обстановка или ограниченные временные рамки. Или просто лень.
Поэтому сегодня на обзоре нейросеть Fishspeech, которая реалистично озвучит текст, сохраняя интонации и эмоциональную окраску. Так ещё можно добавлять свои голоса или использовать уже готовые 50+ голосов от сообщества Нейро-Софт. Вообще сказка! Давайте к обзору.
❯ Основные особенности FishSpeech🐠
Fish Speech Dialogue — современный инструмент для озвучивания диалогов и реплик с использованием разнообразных голосов.
Благодаря портативной версии не нужна установка базового Fish Speech MOD, а функциональность доступна «из коробки»:
Поддержка до 10 говорящих. Идеально для одиночных реплик и сложных диалогов.
Автоматическое распределение голосов. Экономит время, подбирая подходящие голоса для каждого персонажа.
Библиотека из 50+ голосов от сообщества. От Жириновского до Яндекс Алисы.
Форматирование диалогов. Автоматическое оформление в формате «Говорящий: текст».
Различные форматы сохранения. Поддерживаются WAV, MP3 и FLAC.
Мультиязычный интерфейс. Доступны русский и английский.
Автообновления и интеграция с GitHub.
❯ Обзор интерфейса
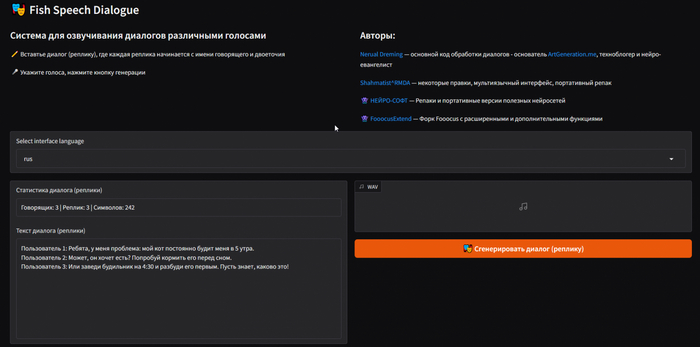
Интерфейс FishSpeech Dialogue
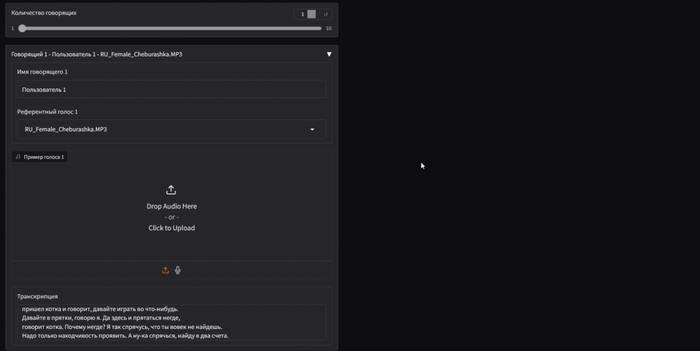
Нас встречает такой интерфейс. В самой верхней строке можно выбрать язык интерфейса, изначально будет английский.
Левое окно «Статистика диалога» — основное рабочее поле. В верхней части окна отображается количество говорящих,число реплик и общее количество символов. Нижняя часть содержит текст диалога.
Диалоги необходимо оформлять так: каждая реплика должна начинаться с имени говорящего и двоеточия. Пример видно на скриншоте выше.
В правой части интерфейса находится блок с итоговым результатом и кнопка «Сгенерировать диалог».
Плавно спускаемся ниже.
Количество говорящих — это автоматический параметр, который определяется системой в зависимости от структуры диалога.
Для каждого говорящего доступна отдельная панель настроек. Здесь можно:
Указать имя говорящего, которое должно совпадать с именем в тексте диалога.
Выбрать референсный голос из доступных вариантов.
Загрузить собственную аудиодорожку и использовать голос из неё. Также необходимо подписать транскрипцию. В этом случае нейросеть будет использовать загруженный голос для генерации диалога. Транскрипцию пишем сплошным текстом.
Последняя функция очень полезна. Когда ваш профессиональный диктор заболел, можно чуть схитрить и продолжить процесс записи и озвучки :D
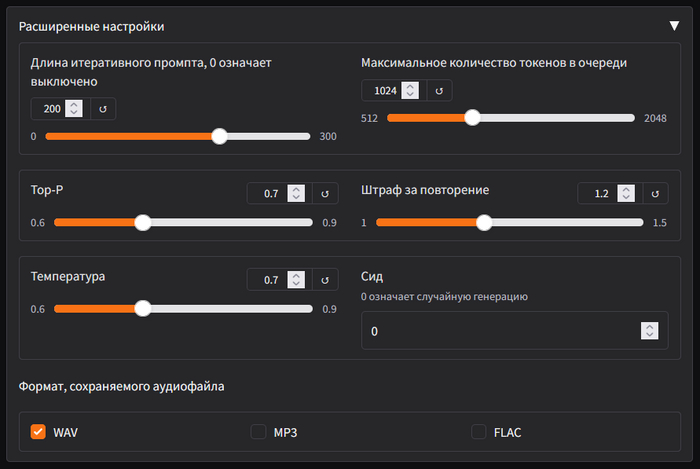
В самом низу находятся расширенные настройки:
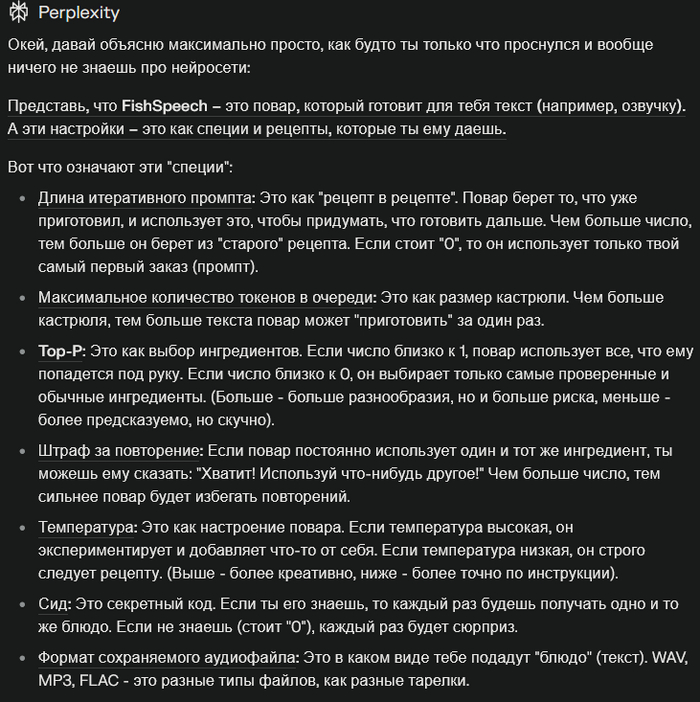
Честно, расширенные параметры я не щупал, меня интересовал лишь принцип работы и результаты. Но я попросил ассистента Perplexity пояснить, что это, кому интересно, вот выжимка:
В общем, всё до безумия просто. Пишем или генерируем диалог, выбираем голоса и получаем озвучку. Давайте посмотрим на неё в деле.
❯ Примеры и возможности
Начнём с простого — рассуждения Винни-Пуха.
Давайте усложним и представим миниатюру: бытовой диалог Джонни Сильверхенда и Яндекс Алисы.
Сгенерируем диалог с тремя участниками - Шерлок Холмс, Сергей Дружко и Кот Матроскин. Такого вы ещё не слышали.
Далее я решил попробовать сгенерировать что-нибудь на английском с голосом Матроскина. И вышло очень даже неплохо и похоже.
Дмитрий Нагиев и Чебурашка:
Ну и напоследок я попросил свою знакомую записать пару голосовых для теста. Дальше скачал их в формате .ogg, конвертировал в .mp3 и загрузил в нейросеть. Для транскрипции я использую крутую нейронку Whisper, скачать её можно на GitHub. Там всё интуитивно понятно, думаю, разберётесь. Вот что получилось.
Ещё пара примеров:
Как итог, FishSpeech — удобный инструмент, который помогает озвучивать тексты даже в ситуациях, когда запись голоса невозможна. Простота и гибкость делают его отличным решением для создания игр, подкастов, аудиокниг и других проектов, где важна качественная озвучка.
Скачать портативную версию FishSpeech с установкой в один клик для самых ленивых вы можете тут.
Подписывайтесь на 👾Нейро-Софт, канал с портативными версиями ваших любимых нейросетей!
🎵 Друзья, вы готовы к настоящей революции в мире аудио? В этом видео я покажу вам три невероятные нейросети, которые перевернут ваше представление о работе со звуком! MM-Audio создаст потрясающие звуковые эффекты для ваших видео и игр всего за пару кликов, Fish Speech поразит вас качеством клонирования голоса по минутному образцу, а LatentSync идеально синхронизирует сгенерированную речь с любым видео.
Я покажу все хитрости настройки, поделюсь личным опытом и научу пользоваться каждым инструментом. А самое крутое - все они доступны в удобных портативных версиях! 🚀
Много лет назад в интернете прогремело разоблачение: за Варум пел Агутин. Простыми настройками в звуковом редакторе голос Варум превращался в голос Агутина и наоборот. Я проверял, это правда.
У Агутина есть песня, которую, зная о ситуации с Варум, иначе как "признанием" не назвать. Вдумчиво посмотрите и послушайте.
Youtube:
Rutube:
Леонид Агутин и Анжелика Варум – "Королева".
В клипе Варум - голограмма, персонаж Агутина управляет ей пультом. Текст:
"Но, никто, никто не увидит! Но, никто, никто не узнает Кто? Кто её тайна? Кто?
Будет так всегда, что никто и никогда Не сумеет разгадать её эту тайну".
"Молча унесёт бог и господин
Только с ним она – королева".
В клипе обыгрывается создание виртуального образа Варум-певицы, "звезды эстрады", который создан человеком за звуковым пультом.
Он ей управляет, он её создатель, "бог и господин".
Как это сделано:
Все ли песни пел Агутин? В своё время я проверял репертуар Варум масштабно. Агутин там до самой глубокой древности. Он у истоков проекта. Однако я находил несколько песен, предположительно, с настоящим голосом Варум или другого исполнителя. Не подскажу названия.