


Synthwave Neuro Arts
8 постов
8 постов
2 поста
Друзья, всем привет, сегодня хочу рассказать, как создавать симпатичные аниме арты прямо в браузере, используя онлайн сервис работающий на нейросети Stable Diffusion.
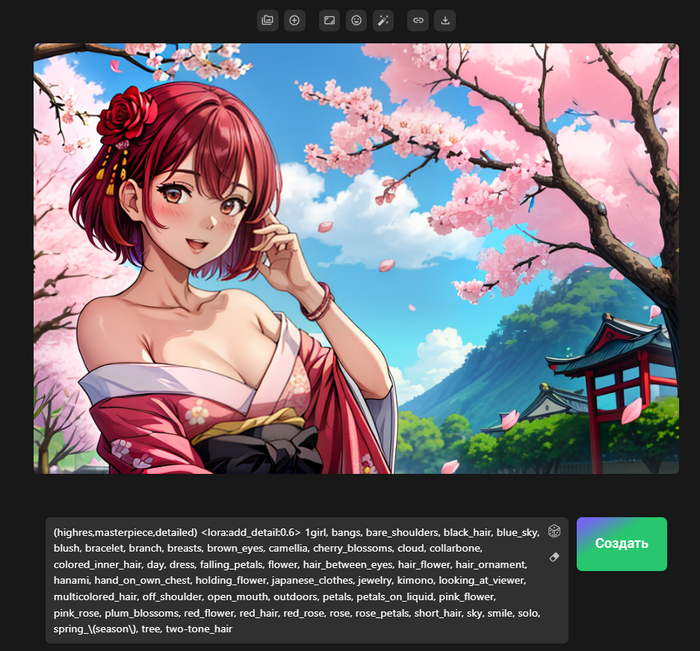
Теперь вам не нужно иметь мощную видеокарту, достаточно написать запрос, можно даже на русском, и в течении минуты получите изображение. Но как создавать изображения именно в Аниме стиле? Обо всем по порядку.
Сначала регистрируемся на ArtGeneration.me - ссылка реферальная, зарегистрировавшись по ней вы получите 7 дней PRO, вместо 3 и 200 дополнительных генераций, вместо 100 на баланс, так что решайте сами 😁. На сайте вам ежедневно будет начисляться 50 генераций, а если оформите подписку PRO, то 300, жду шутку про тракториста в комментарии.
С регистрацией никаких проблем не возникнет, можно авторизоваться с помощью Яндекса или Гугла, и сразу попадаем в галерею изображений.
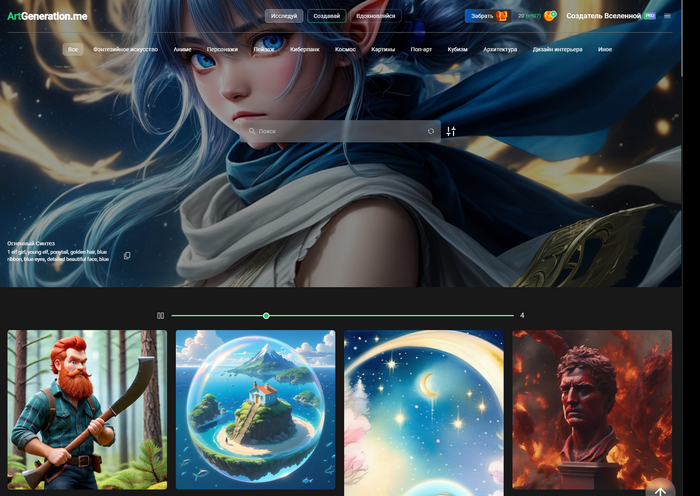
Картинки на главной выбираются автоматически из самых популярных, там может быть и ваша
В галерее можно увидеть что сейчас создают пользователи и сразу сделать свою версию. По клику на любую картинку вы сможете увидеть по какому запросу она была создана.

То что получится на изображении описывается с помощью запроса и негативного запроса, так нейросеть понимает, что рисовать, а что не рисовать. Запросы можно писать на русском, они будут автоматически переводится. Но мы будем писать на английском, потому что примеры, которые мы будем находить на сайте где размещают модели тоже будут на английском.

Тут я поменял в запросе только цвет волос с красных на голубые
Самый просто способ сделать красиво, это найти что-то, что вам нравится нажать на кнопку Создать свою версию, так вы откроете изображение с теми же настройками с которыми оно было создано. Останется поменять несколько слов в запросе и получить то что хочется именно вам. Изучим основные настройки.

По клику на иконку рядом с названием модели откроется страница со всеми созданными на этой модели картинками
Настройки генерации скрыты в правом баре, если у вас маленький экран, то он может быть скрыт по умолчанию, нажмите на стрелочку, чтобы развернуть.
Самое важное это модель, от модели зависит буквально все, ниже я расскажу какие модели лучше всего подходят для Аниме стилистики.
Разрешение, на моделях 1.5 (те, где в названии нет XL), важно не выходить за разрешение 512х768 или 768х512, но есть и хитрость, можно пропорционально увеличить разрешение до 960х640 или обратно, так качество изображений будет выше. На XL моделях можно смело делать разрешение больше.

Чтобы открыть описание стиля нажмите на иконку i
Стили это маленькие предустановленные кусочки запросов, они добавляются к запросу который пишите вы, стили очень удобно использовать с простым запросом в 1 - 2 предложения, если копируем откуда-то промпт, то стиль использовать не стоит.
В Избегать пишется негативный запрос, то, чего не должно быть на изображении, лучше всего его взять из готовых примеров, или на сайте где размещают модели. Остальные настройки можно в принципе не менять, по умолчанию они работают хорошо.

Промпт даже не менял, просто загрузил изображение Уэнсдей
Свое изображение позволяет загрузить любое фото или картинку из интернета и получить генерацию которая будет очень похожа на то, что вы загрузите, степень изменения загруженной фотки можно регулировать ползунком.
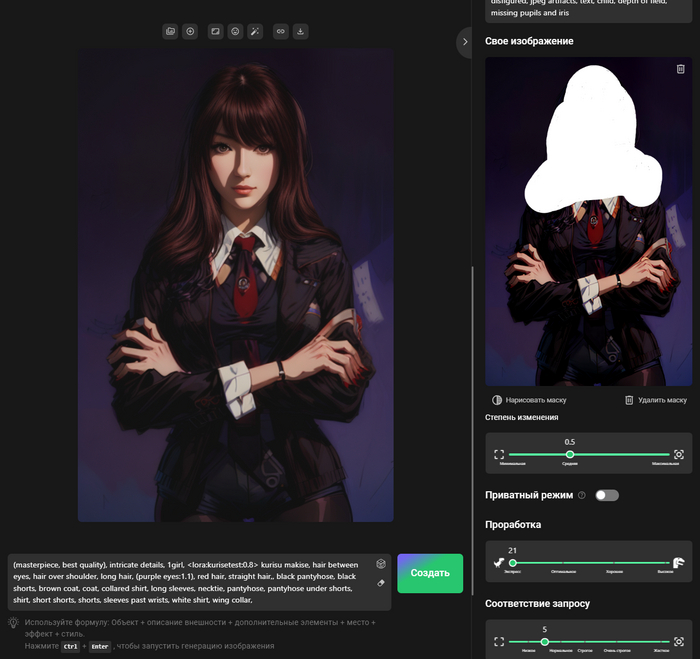
Над картинкой расположены кнопочки, первая отправляет генерацию в Свое изображение
Сюда же можно отправить вашу генерацию, например, чтобы сделать что-то похожее, но с другим запросом. А если не нравится только одна часть, её можно закрасить маской и тогда закрашенная часть будет пере генерирована. Так например можно улучшить лицо.
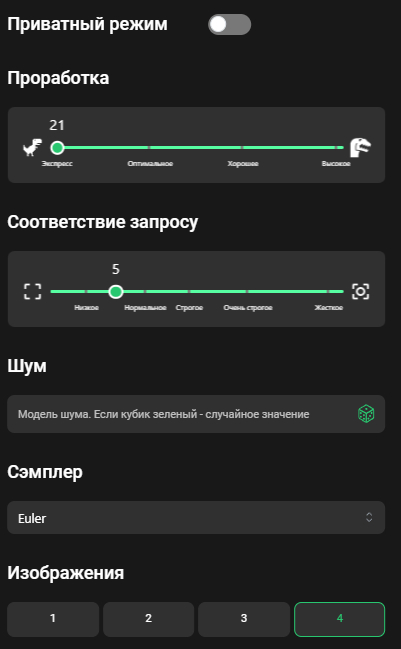
На самом деле большинство настроек можно не трогать они по умолчанию работают хорошо
Если не хотите чтобы ваши изображения попадали в общую галерею, можно включить приватный режим.
Проработка отвечает за то, сколько раз нейросеть попробует очистить картинку от шума, оптимально 30-40.
Соответствие запросу оставляете в районе 5-7, эта настройка отвечает за следование запросу, но если превысить, то получите просто некрасивое изображение.
Все генерации создаются путем очистки изображения от шума, он похож на помехи в телике, номер конкретного шума позволяет создать еще раз такую же или очень похожую картинку по тому же запросу. Обычно используется случайный шум - зеленый кубик.
Сэмплер это математический алгоритм для визуализации, мои любимые DPM++ 2M Karras, Euler и UniPC, они самые универсальные.
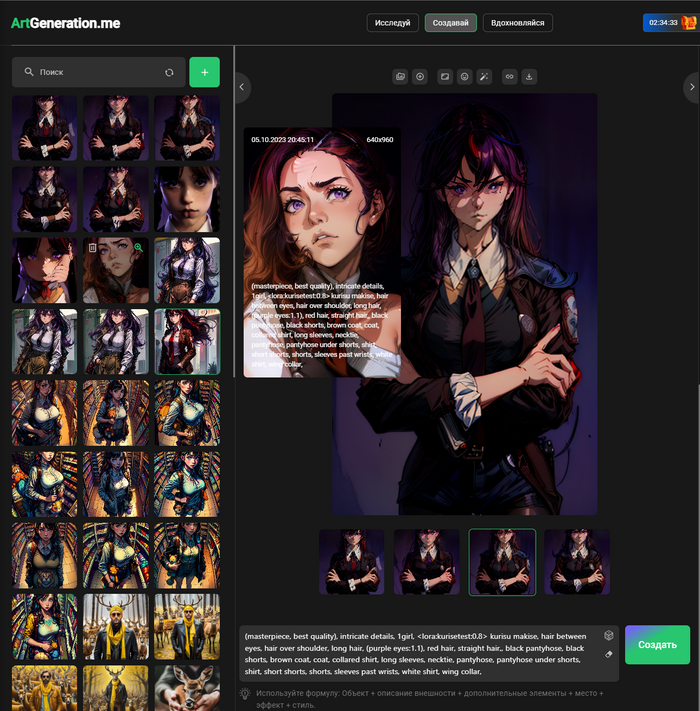
Слева расположен бар с созданными вами изображениями, можно быстро перейти к настройкам любого созданного ранее изображения просто кликнув на него. Там же удаление и быстрый предпросмотр изображений, чтобы было удобно быстро находить нужную картинку.
Далеко не все модели хорошо подходят для аниме стилистики. Я сделал небольшой топ, лучших на мой взгляд моделей из доступных на ArtGeneration.me.
У каждой модели я написал название, оставил ссылку на все изображения созданные на этой модели и ссылку на Civitai, где можно скопировать хорошие запросы и негативные запросы именно для этой модели, про это еще расскажу ниже.

Очень симпатичная аниме модель, запросы лучше писать ключевыми словами.
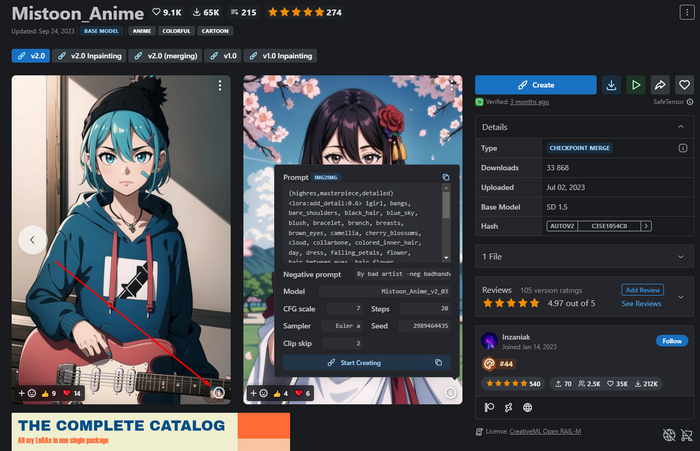
И сразу расскажу зачем нам ссылка на Civitai, заходим по ней и видим изображения созданные автором модели, у каждого изображения в правом нижнем углу есть иконка i, жмите на неё и увидите запрос который лучше всего подходит именно для этой модели.
А ниже еще изображения созданные сообществом, там тоже можно найти много всего интересного, и примеры промптов и новые идеи для артов, обязательно посмотрите.
Проще всего сделать красивое изображение если скопировать удачный запрос, а потом понемногу изменять его.

Очень популярная 2.5d модель со своим необычным ярким стилем. В качестве запросов нормально работают и обычные базовые запросы.

Модель больше ориентирована на 3д в стиле пиксара или диснея, но и аниме стиль удается хорошо, особенно если подобрать интересный запрос как в случае с этим примером.

Не совсем про аниме, скорее стиль комиксов, но тоже очень классная 2д модель.

Яркая модель со своим особенным стилем, скорее тоже в мультипликацию, но крутая.

Классический анимешный микс моделей, похожий на все и сразу.

Модель создает безумно милые изображения с классическими большими головами и глазами у персонажей.

Очень классная SDXL модель, которая заточена под арт и в т.ч. аниме, отлично следует промпту, идеальна для работы со стилями и промптов на русском.

На этот раз без 2.5, но тоже очень классный, в стиле классического аниме.

Уже достаточно старая, но все еще очень популярная аниме модель.

Модель от создателя знаменитой Deliberate, не самая интересная аниме модель, на мой взгляд, но у неё хватает поклонников.
SDXL Niji Special Edition

Еще одна отличная SDXL модель заточенная под арт и иллюстрации, но отлично справляется и с аниме и хорошо понимает запросы как и все XL модели.
Рассказать о найденных багах, поделиться созданными изображениями или пообщаться с разработчиками можно в сообществе сервиса в телеграм.
Теперь вы знаете как создать арт с помощью нейросети ArtGeneration.me используя только браузер. Знаете как пользоваться сервисом и сможете найти отличные запросы на сайте размещающем модели. Ну и подобрать модель по душе из этой подборки тоже сможет каждый. Попробуйте повторить любое изображение из подборки самостоятельно.
Друзья, поддержите пост плюсиком, в нашей стране сейчас совсем не много таких проектов создается.
А на этом у меня все, делитесь вашими изображениями в комментариях и удачных генераций.
Доброго времени суток, друзья!
Я регулярно выбираю себе различные вещи и всегда стремлюсь добиться наилучшего сочетания цена/качество. Началась теплая пора, прогулки стали длиннее, а у моего нового Redmi 13 Pro+ 5G, как назло, нет выхода под наушники. Значит, настало время наконец-то купить себе TWS.

Как аудиофил со стажем, имеющий плеер FiiO M11 и наушники FiiO FH5, я всегда избегал беспроводных наушников. Когда-то, лет 5-10 назад, я пробовал ранние модели TWS и, честно говоря, обплевался — качество звука было отвратительным. С тех пор я не верил беспроводной связи вообще, предпочитая проводные решения.
Но время идет, технологии развиваются, и современные модели, судя по отзывам, весьма неплохие. Меня зовут Илья, я основатель онлайн-нейросети для создания изображений ArtGeneration.me, техноблогер и нейро-евангелист, поэтому подхожу к выбору техники довольно дотошно.
Целью этого обзора является дать вам общее представление о рынке TWS-наушников с самым качественным звуком. Детальные обзоры на каждую конкретную модель вы сможете посмотреть на YouTube — я вставил в статью обзоры, которые YouTube считает хорошими, думаю они дадут вам полное представление о моделях.
Чтобы найти лучшую модель, я погрузился в глубокое исследование рынка актуальных TWS-наушников. Если вы, как и я, любите музыку и выбираете наушники, возможно, это исследование будет вам полезно.
S-Tier (Премиум без компромиссов):
Sony WF-1000XM5 (19 990 - 27 990 ₽)
Technics EAH-AZ100 (30 000 - 50 000 ₽)
A-Tier (Отличный баланс):
Sennheiser Momentum True Wireless 4 (от 17 000 ₽)
Creative Aurvana Ace 2 (от 12 000 ₽)
Denon PerL Pro (25 000 - 40 000 ₽)
B-Tier (Хорошие варианты с нюансами):
Bowers & Wilkins Pi8 (38 000 - 50 000 ₽)
Edifier NeoBuds Pro 2 (8 000 - 15 000 ₽)
Nothing Ear (a) (от 8 000 ₽)
Для создания объективного рейтинга я проанализировал множество источников: от англоязычных и русскоязычных форумов Reddit до профессиональных обзорных сайтов и специализированных аудио-блогов. Особое внимание уделил реальным отзывам пользователей на российских площадках: Озон, Яндекс.Маркет, ДНС и других интернет-магазинах с актуальными ценами на май 2025 года.
Основные критерии оценки:
Качество звука (детализация, звуковая сцена, баланс частот)
Активное шумоподавление (ANC)
Время автономной работы
Удобство посадки и комфорт
Надежность и качество сборки
Соотношение цена/качество
Доступность в России и цены
Для тех, кто не в курсе: TWS (True Wireless Stereo) — это полностью беспроводные наушники без каких-либо проводов между левым и правым наушником. Они подключаются к устройству по Bluetooth и обычно поставляются с компактным зарядным кейсом, который не только защищает наушники, но и подзаряжает их в дороге.
Большинство современных TWS-наушников оснащено активным шумоподавлением (ANC — Active Noise Cancellation). Эта технология использует встроенные микрофоны для анализа окружающих звуков и создает "противофазные" звуковые волны, которые гасят внешний шум. Проще говоря, наушники "слушают" что происходит вокруг и генерируют звук, который нейтрализует нежелательные звуки — гул самолета, шум кондиционера или городской трафик. Это позволяет слушать музыку на меньшей громкости и лучше сосредоточиться.
Наверняка многие ожидают увидеть в обзоре Apple AirPods Pro, но их здесь нет по нескольким причинам. Во-первых, хоть AirPods и действительно хороши, они далеко не лучшие в плане качества звука для воспроизведения музыки. Во-вторых, они не универсальны — если у вас Android (как у меня с Redmi 13 Pro+ 5G), покупать AirPods по меньшей мере глупо, так как вы потеряете значительную часть функционала. AirPods заточены под экосистему Apple и максимально раскрываются только с iPhone и другими устройствами Apple.
🏆 S-Tier: Премиум без компромиссов
Цена в России: 19 990 - 27 990 ₽

Флагман от Sony, который многие считают эталоном среди TWS-наушников. Обеспечивают лучшую в классе детализацию и музыкальность звучания. ANC здесь очень эффективное — в наушниках можно комфортно находиться даже в метро или самолете.
Плюсы:
Превосходное качество звука с поддержкой LDAC
Очень эффективное активное шумоподавление
8 часов работы + 16 часов с кейсом
Легкий вес и комфортная посадка для большинства
Отличная работа с тяжелой музыкой
Минусы:
Проблемы с посадкой у пользователей с маленькими ушами
Чрезвычайно чувствительные сенсорные панели (из отзывов 2025)
Возможные сбои при использовании LDAC
Глянцевые поверхности собирают отпечатки
Отзывы пользователей: "Опыт использования пол года. С силиконовыми амбушюрами тест на подбор насадок стал проходить с первого раза, шумоподавление стало работать ещё лучше."
Цена в России: 30 000 - 50 000 ₽

Японское инженерное чудо с уникальными магнитными жидкостными драйверами. Предлагают исключительную звуковую сцену среди всех TWS-наушников, но имеют свои особенности.
Плюсы:
Революционная технология магнитных жидкостных драйверов
Исключительная звуковая сцена и детализация
Тройное подключение устройств
Поддержка Dolby Atmos и LDAC
Улучшенный комфорт по сравнению с AZ80
10-12 часов автономной работы
Минусы:
Звук заметно ухудшается при выключенном ANC
Слабоватые магниты для крышки кейса
Специфичные отношения с тяжелой музыкой
Высокая цена
Отзывы экспертов: "AZ100 - это хорошо продуманные, удобные беспроводные наушники премиум-класса, которые впечатляют. Sony и Bose стоит задуматься!"
🥇 A-Tier: Отличный баланс
Цена в России: от 17 000 ₽

Немецкое качество в мире TWS. Отличаются мощными басами и функцией персонализации звука, которая адаптирует звучание под особенности вашего слуха.
Плюсы:
Фирменное звучание Sennheiser с мощными басами
Персонализация звука через приложение
Поддержка aptX Lossless и LE Audio
Надежное ANC без влияния на звук
Отличное управление и приложение
Минусы:
Относительно громоздкие
Посредственное качество микрофона
Сообщения о проблемах с надежностью
Может быть слишком басовитым для некоторых
Отзывы пользователей: "Первые затычки в которых Slipknot реально хорошо звучит. Звук практически во всех жанрах потрясающий. Приложение и управление шикарно."
Цена в России: от 12 000 ₽

Первые в мире TWS-наушники с технологией xMEMS — твердотельными драйверами. Настоящий прорыв в аудиоиндустрии по разумной цене.
Плюсы:
Революционная технология xMEMS драйверов
Выдающиеся высокие частоты и детализация
Поддержка aptX Lossless
Инновационный подход к звукоизвлечению
Привлекательный полупрозрачный дизайн
Минусы:
Проблемное ANC с "белым шумом"
Нет автопаузы при снятии наушника
Стандартный эквалайзер сбрасывается
Средний корпус кейса
Недостаток громкости на максимуме
Отзывы пользователей: "xMEMS-драйверы сделаны из кремния и работают за счёт подачи напряжения. Результат — максимально точная проработка высоких частот."
Цена в России: 25 000 - 40 000 ₽

Японские наушники с уникальной технологией AAT (Adaptive Acoustic Technology), которая персонализирует звук под особенности вашего слуха.
Плюсы:
Уникальная технология AAT для персонализированного звука
Хорошее качество звука после настройки
Поддержка aptX Lossless
Комфортны для стационарного использования
Эквалайзер поверх коррекции AAT
Минусы:
AAT может быть нестабильной и сильно зависящей от насадок
ANC просто приемлемое, не лучшее
Сообщения о проблемах с надежностью и контролем качества
Посадка может быть неоднозначной
Качество микрофона не очень хорошее
Отзывы пользователей: "Звук после акустической настройки феноменальный и действительно забавный. Могут быть одними из лучших звучащих наушников на рынке."
🥈 B-Tier: Хорошие варианты с нюансами
Цена в России: 38 000 - 50 000 ₽

Британский премиум с углеродными драйверами и уникальной функцией кейса-передатчика.
Плюсы:
Высшая звуковая чистота
Углеродные конусные драйверы
Кейс может работать как передатчик для проводных источников
Превосходная детализация
Эффективное ANC
Минусы:
Очень высокая цена
Некоторые проблемы с подключением
Качество звонков не на высоте
Отсутствие тестов посадки
Цена в России: 8 000 - 15 000 ₽

Китайский бренд с впечатляющим соотношением цена/качество и поддержкой Hi-Res кодеков.
Плюсы:
Отличная звуковая сцена для своей цены
Поддержка LDAC и LHDC 5.0
Эффективное шумоподавление
Доступная цена
7 пар амбушюр в комплекте
Минусы:
Слабые средние частоты
Китайское приложение с ограниченной локализацией
Среднее время автономной работы (4-5.5 часов)
V-образная звуковая сигнатура
Цена в России: от 8 000 ₽

Стильные наушники от бывшего основателя OnePlus с хорошим функционалом за разумные деньги.
Плюсы:
Привлекательный дизайн
Хорошее ANC для своей цены
Поддержка LDAC
Интеграция с ChatGPT (на устройствах Nothing)
Отличное соотношение цена/качество
Минусы:
Нет беспроводной зарядки
Среднее время автономной работы
Ограниченные настройки звука
Отсутствие персонализированного звукового профиля
⚠️ Осторожно: подделки!
При выборе TWS-наушников в России особое внимание стоит уделить оригинальности товара. Рынок наводнен подделками, особенно популярных моделей Sony и Apple. Я видел предложения Sony WF-1000XM5 с доставкой из-за рубежа по цене от 2 000 рублей — это очевидные подделки.
Как избежать подделок:
Покупайте у официальных дилеров
Избегайте подозрительно низких цен
Проверяйте наличие гарантии
Остерегайтесь товаров "из-за рубежа" по бросовым ценам
Рекомендуемые магазины:
Озон (выбирать продавца "Озон" и оригинальный товар)
Яндекс.Маркет с проверенными продавцами
ДНС — крупная сеть с гарантией оригинальности
М.Видео — официальный ритейлер

После всего исследования я остановился на Sony WF-1000XM5 и заказал их на Озоне за 22 000 рублей, выбрав продавцом сам Озон для гарантии оригинальности. Не забудьте кликнуть на "попросить скидку" это действительно работает, скидка не большая, но приятная.
Почему именно Sony?
Эти наушники я выбрал по большому счету из-за того, что в технических обзорах, которые я изучал, прямым текстом было сказано, что у Technics AZ100 есть довольно специфические отношения с тяжелой музыкой. А я очень люблю тяжелую музыку — слушаю симфонический метал, различные направления мелодик дэт-метала. Мне очень хотелось, чтобы гитары работали хорошо, дисторшн был качественным, и вообще весь спектр тяжелых жанров звучал максимально достойно.
Плюс, Sony — действительно старый и уважаемый бренд. Одно время я был фанатом Sony, пока они не начали делать откровенно плохие телефоны, а потом не перестали делать их вообще. Но с тех пор уже много воды утекло, и в области аудио они по-прежнему остаются в топе.
Sony WF-1000XM5 предлагают:
Идеальный баланс всех характеристик
Очень эффективное ANC
Отличную работу с тяжелой музыкой
Разумную цену для флагманского уровня
Широкую доступность в России
Проблемы с подключением: реальный опыт
Однако, после нескольких часов использования я столкнулся с серьезными проблемами подключения. Наушники теряли связь и «залипали» на доли секунды бесчисленное количество раз. Вопреки первоначальным ожиданиям, всё оказалось не так гладко. Прогулявшись с наушниками вечером, я обнаружил, что они сильно теряют связь. Эта проблема не редкая, и многие пользователи часто с ней сталкиваются
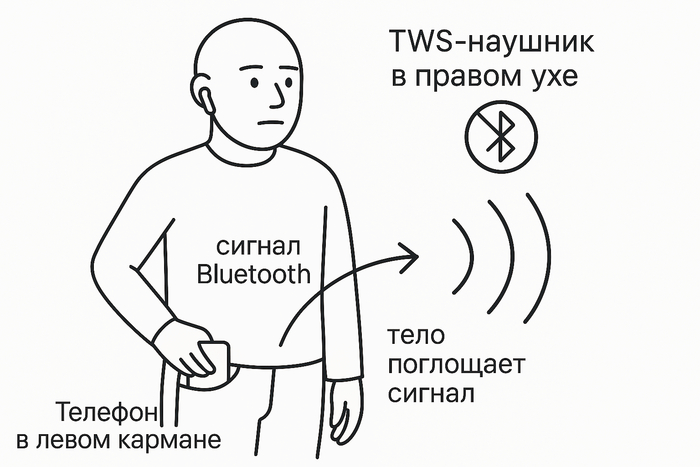
Если телефон находится в руках или на столе, звук прекрасен и на высшем уровне. Но стоит положить телефон в левый карман штанов, где я обычно его ношу, и наушники перестают ловить. Менять привычки ношения телефона я не собирался, особенно при покупке такого устройства. Это происходило даже при включенном приоритете качества соединения, поскольку на приоритете качества музыки ситуация была еще хуже. Прежде чем решить сдавать наушники обратно, я занялся поиском решений в сети, оказалось, что они есть.
Что помогло решить эту проблему?
Переключение на кодек AAC в настройках вместо LDAC значительно стабилизировало связь. Удивительно, но при использовании кодека LDAC связь обрывалась даже при простом проведении рукой рядом с телефоном. С кодеком AAC всё в порядке, и, учитывая, что я слушаю музыку через Spotify, разница в качестве звука для меня не так заметна, зато стабильность подключения значительно улучшилась.
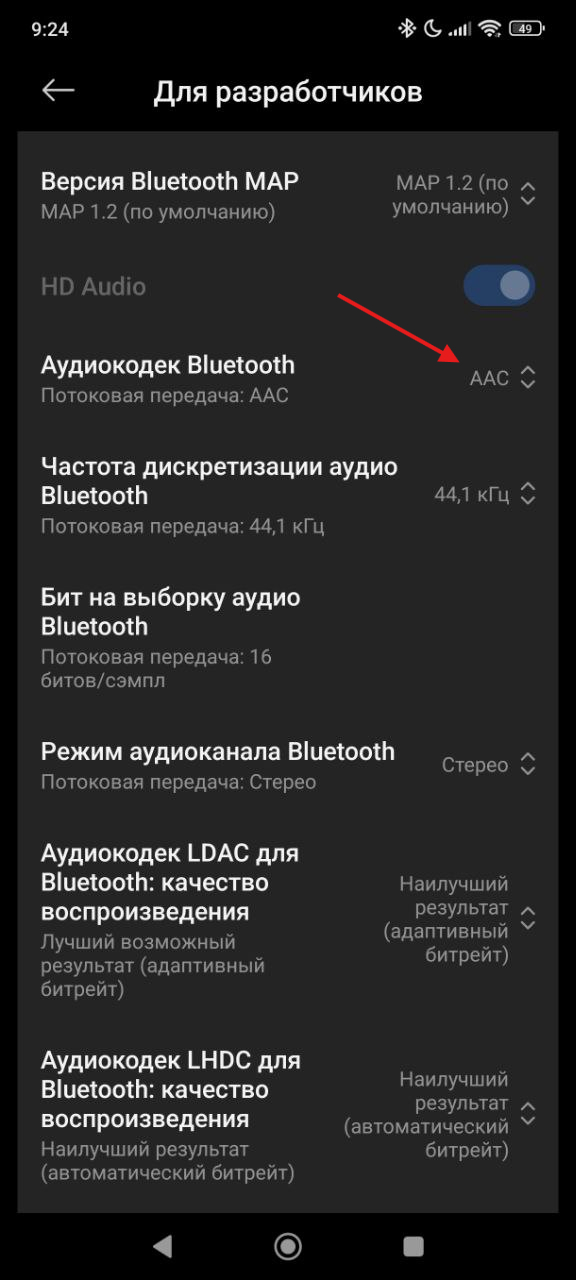
Как включить (на примере MIUI, может отличаться в других версиях Android):
Настройки → О телефоне → 7 раз тапните по версии MIUI (в моем случае).
Настройки → Расширенные → Параметры разработчика.
Найдите "Аудиокодек Bluetooth" → переключите на AAC (если не поможет - на SBC).
Это была не единственная проблема. На моём плеере FiiO M11 я не смог скачать официальное приложение для наушников, так как M11 работает на старой версии Android (седьмой), и новые приложения на ней не устанавливаются. К счастью, плеер и так работает с наушниками, и его лучшая антенна обеспечивает стабильную связь в режиме LDAC, даже когда плеер находится в том же кармане. Очень странные дела. Плеер FiiO работал хорошо, и его LDAC нормально ловил, но стоило переключиться в приоритет качества музыки, и тоже начинались проблемы. В итоге, я оставил оба устройства на приоритет качества соединения: на телефоне на AAC, а на FiiO на LDAC.
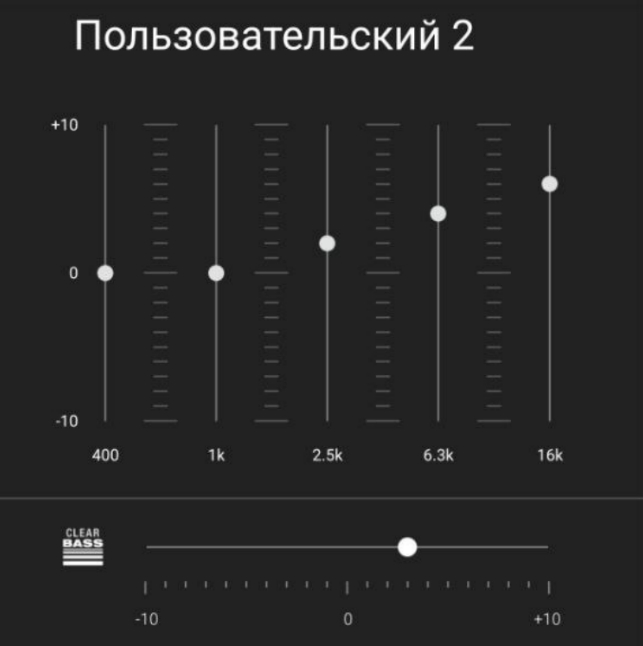
На слух настроил эквалайзер, по итогу получилось что просто выкрутил высокие и добавил басов.
Что касается удобства, наушники комфортно сидят в ушах, и я сразу отключил все автоматические функции, предпочитая управлять ими вручную. Сравнится ли качество звука с моими FiiO FH5? Конечно, нет. Качество сцены хуже. Басов меньше. Гитары хуже. И, несмотря на настройку эквалайзера, всё равно не хватает высоких частот, и присутствует некоторый "песочек".
Насколько они хуже моих проводных, если субъективно, то на 15-20%, но только в сравнении с FLAC источниками. Если слушать онлайн (и у вас не Tidal), то разницы вы не услышите. Я не слышу. Так же не слышу разницу в LDAC и AAC на разных устройствах при воспроизведении музыки из Spotify. Но в целом, наушники меня действительно устраивают, а ведь чуть было не сдал обратно.
Безусловно, например Noble Audio FoKus Rex5. На момент написания этого текста на Озоне есть всего одна позиция за 65 000 рублей, и они зелёные. Я уверен, что они будут лучше, потому что это можно назвать вершиной TWS-технологий. Noble Audio FoKus Rex5 оснащены гибридной конфигурацией из пяти драйверов (1 динамический, 1 планарный, 3 арматурных) и поддерживают Bluetooth 5.4 с кодеками SBC, AAC, aptX Adaptive и LDAC. Они также предлагают персонализированную настройку звука Audiodo, что позволяет адаптировать звучание под индивидуальные особенности слуха.

Эти наушники получили множество положительных отзывов за детальное и захватывающее звучание, а также за эффективное активное шумоподавление. Но 65+ тысяч за TWS наушники, это уже за пределами моего бюджета и, возможно, здравого смысла. И при этом они зеленые.
Рынок TWS-наушников в 2025 году предлагает отличные варианты во всех ценовых категориях. Если ваш бюджет ограничен — смотрите на Nothing Ear (a) или Edifier NeoBuds Pro 2. Если хотите попробовать новые технологии — Creative Aurvana Ace 2 с xMEMS драйверами. Если нужен абсолютный звуковой максимум и деньги не проблема — Technics EAH-AZ100 или Bowers & Wilkins Pi8.
Но для подавляющего большинства пользователей оптимальным выбором остаются Sony WF-1000XM5 — они не проваливаются ни в одной категории, оставаясь в топ-3 по каждому параметру при разумной цене и отличной доступности в России. Хоть и не без минусов.

Время TWS-наушников действительно пришло. Хотя они врядли заменят проводные решения для серьезных аудиофилов, они уже не так отвратительны, как 10 лет назад, и вполне пригодны для повседневного использования — конечно, если речь идет о моделях за адекватный ценник.
А есть ли у вас какие-то из этих наушников или быть может вы слушали что-то из обзора и имеете свое мнение — пишите его в комментариях!
Всем привет! Наверняка у каждого, кто увлекается технологиями, бывают моменты, когда хочется быстро проверить какую-то идею или «поиграться» с новым API, не погружаясь в сложную разработку. Сегодня я хочу рассказать как раз о таком эксперименте выходного дня, который начался с простого желания пощупать возможности одного сервиса, а в итоге вылился в небольшой, но забавный пет-проект – GPT Arena.

Меня зовут Илья, я основатель онлайн-нейросети для создания изображений ArtGeneration.me, техноблогер и нейро-евангелист. Идея GPT Arena зародилась у меня давно, еще во времена появления кастомных GPTs от OpenAI. Тогда я даже сделал небольшой прототип: игра предлагала создать героя, генерировала его изображение и весело описывала его бой с другим таким же созданным героем, учитывая их абилки и способности. С учетом того, что в ChatGPT была озвучка сообщений – получалось прикольно. Однако тот прототип был сыроват и я надолго его забросил.
Недавно я решил вернуться к этой концепции, когда познакомился с API от Pollinations. Как человек, который не является программистом в классическом смысле, а скорее энтузиастом, исследующим возможности AI и предпочитающим генерировать код с помощью нейросетей, а не писать его с нуля, мне было особенно интересно проверить эту идею в деле, используя новый инструментарий.
Что меня сразу зацепило в Pollinations.ai – это их невероятная доступность. Для экспериментов и пет-проектов это просто находка: API для генерации изображений, текста и аудио работает вообще без регистрации, абсолютно бесплатно и отдает результат почти мгновенно. Это был решающий фактор, позволивший быстро перейти от идеи к реализации.
Прежде чем погружаться в разработку самой игры, я решил создать небольшой инструмент для тестирования API. С помощью нейросети Cloude, которая помогла мне с кодом, я просто скормил документацию от Pollinations и свою задачу, Клод в итоге создал простую HTML-страницу. Этот «пульт управления» позволял мне прямо из браузера отправлять запросы к Pollinations и смотреть, что получается.
В этом инструменте было три ключевые функции, соответствующие API: генерация изображений, текста и голосовых ответов. Весь JavaScript, управлявший этим тестером, по сути, формировал GET-запросы к API Pollinations. Вот так, например, выглядела функция для формирования URL для генерации изображения:
// Формирование URL для запроса на генерацию изображения
function generateImageURL(prompt, options = {}) {
const params = new URLSearchParams(); // Создаем объект для URL-параметров
if (options.width) params.append('width', options.width); // Добавляем ширину, если указана
if (options.height) params.append('height', options.height); // Добавляем высоту, если указана
if (options.model) params.append('model', options.model); // Добавляем модель, если указана
// ...и другие параметры типа seed, nologo и т.д.
const queryString = params.toString(); // Преобразуем параметры в строку
// API_CONFIG.image.baseURL = 'https://image.pollinations.ai/prompt/'
// Собираем итоговый URL, кодируя сам промпт
return `${API_CONFIG.image.baseURL}${encodeURIComponent(prompt)}${queryString ? '?' + queryString : ''}`;
}
Интересный момент: попытка выполнить эти API-вызовы напрямую из среды Claude (с которой я тогда экспериментировал) не увенчалась успехом из-за сетевых ограничений. Но когда я сохранил этот HTML-файл тестера и открыл его локально в браузере – всё заработало! API откликалось, контент генерировался. Это стало подтверждением: концепция жизнеспособна.
Этот успешный тест и дал зеленый свет полноценной работе над GPT Arena.
Идея оставалась прежней: AI в роли гейм-мастера. Но какую игру выбрать? Я решил остановиться на простом пошаговом RPG-образном файтинге. Это позволяло, с одной стороны, иметь четкую структуру (раунды, действия, HP), а с другой – давало простор для AI в описаниях и генерации контента.
Это Proof of Concept в виде одного HTML-файла (около 140 КБ), работающий полностью в браузере пользователя.
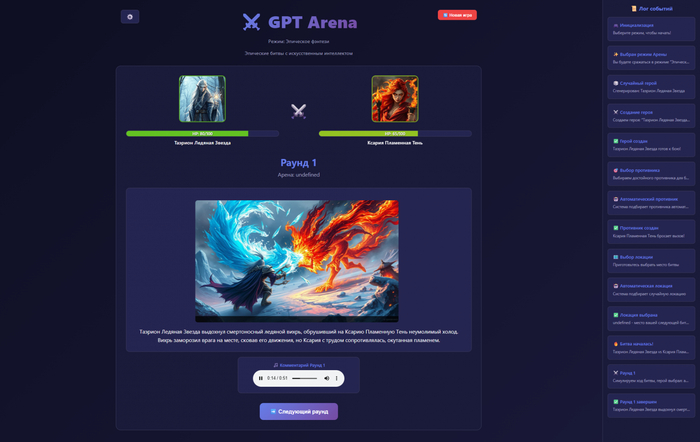
Ключевые возможности:
AI-генерация персонажей: на основе описания или случайным образом создаются уникальные бойцы с именами, историями, характеристиками и способностями.
Создание и озвучка локаций: место битвы также генерируется AI.
Динамическая симуляция пошаговых боев: каждый раунд сопровождается текстовыми комментариями, визуальными эффектами и свежей иллюстрацией.
Полная озвучка: все важные события в игре озвучиваются.
Три игровых режима: «✨ Эпическое фэнтези», «🩸 Кровавый файтинг» и «🚶 Скучная реальность».
Пользовательские действия: игрок может предложить свое действие.
Лог событий: весь ход игры фиксируется в таймлайне.
Вся игра – это HTML-разметка, CSS для стилизации и JavaScript для логики.
Промпты и игровые режимы
Ключ к работе GPT Arena – это, конечно же, промпты. Для каждого игрового режима и каждого типа генерируемого контента (персонаж, локация, описание боя) используется свой, специально настроенный системный промпт.
✨ Эпическое фэнтези
Промпты для персонажей нацелены на создание классических фэнтезийных архетипов: «Персонаж должен быть типичным для фэнтези мира: эльф, маг, рыцарь, дракон, минотавр и т.д.».
Визуальный стиль картинок описывается как: "cinematic fantasy illustration, high quality, unique style, vibrant colors".
Описания боя должны быть «динамичными, драматичными и зрелищными», с элементами "героического пафоса".
Диапазон урона тут средний (15-40 HP).
2.🩸 Кровавый файтинг
Персонажи тут уже «брутальные бойцы, киборги, ниндзя, монстры», в духе Mortal Kombat.
Визуальный стиль: "brutal 3D fighting game render, dark atmosphere, gore details, high quality, realistic textures".
Бои описываются как «сокрушительные", с элементами "черного юмора или иронии», но без ущерба для «брутальности».
Урон здесь самый высокий (25-60 HP).
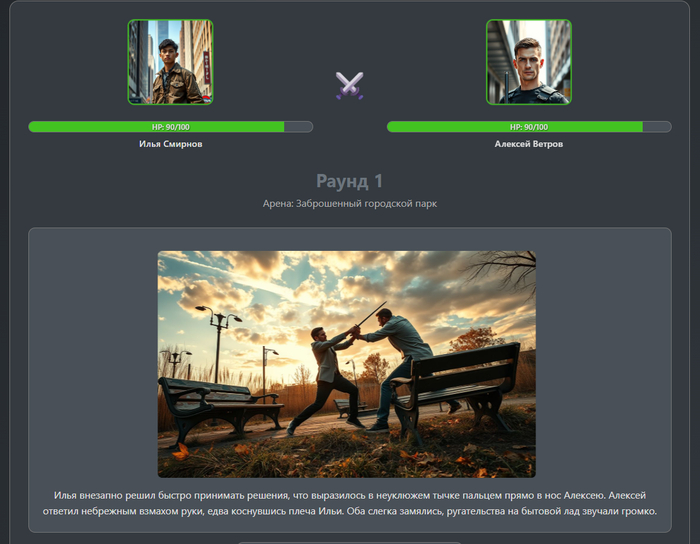
3.🚶 Скучная реальность
Персонажи – «обычные люди, без каких-либо сверхспособностей»: офисный работник, продавец, студент.
Визуальный стиль: "photorealistic, everyday scene, natural lighting, mundane details, high quality, realistic textures".
Бои – это «нелепые, скучные драки», с «неуклюжими движениями, случайными тычками и бытовой руганью», с элементами «абсурдного, бытового юмора».
И урон тут минимальный (1-10 HP).
Вот фрагмент общего шаблона для создания персонажа, который адаптируется под каждый режим:
// PROMPTS.CHARACTER_PROMPT_TEMPLATE = (additionalInstruction = "") =>
// `Ты создатель персонажей для GPT Arena. Отвечай СТРОГО в JSON формате.
// Создай уникального персонажа для динамичной арены на основе предоставленного описания.
// ${PROMPTS.PROMPT_INSTRUCTION} Персонаж должен точно соответствовать заданному сеттингу...
// ${additionalInstruction} // Сюда подставляется специфика режима
//
// {
// "name": "Имя персонажа (креативное, но уместное, на русском языке)",
// "description": "Подробное и интригующее описание...",
// "visualPrompt": "highly detailed character portrait, [внешность], ... This visualPrompt string MUST be in English.",
// "stats": { "strength": число_1_10, ... },
// "abilities": ["способность 1", "способность 2"]
// }`
Именно благодаря таким детальным и адаптируемым промптам удается добиться нужной атмосферы в каждом из режимов.
Трудности и их преодоление: были и стандартные «грабли» вроде ограничений GET-запросов, необходимости индикаторов загрузки из-за задержек API и, конечно, часы промпт-инжиниринга для получения стабильных JSON-ответов.
Несмотря на то, что GPT Arena – это, по сути, быстрый проект, созданный больше для проверки идеи и возможностей AI, результатом я остался доволен. Приложение наглядно демонстрирует, как с помощью современных генеративных нейросетей и относительно простых веб-технологий можно создавать полностью автономные интерактивные приложения.
Пространство для улучшений огромное: интеграция более мощных моделей, улучшение графики и звука, расширение интерактивности.
А еще я подумываю, а не замахнуться ли на создание бесконечного «Нейро-Клуба Романтики» – такой себе визуальной новеллы или даже интерактивного комикса, где сюжет, персонажи и иллюстрации будут генерироваться на лету. Понятно, что это будет на порядок сложнее, чем одностраничное приложение, но сама идея захватывает! Остается лишь подключить более качественное API, Deep Seek R1 для ведения боев, Flux 1 D для генерации картинок, и Fish Speech для генерация озвучки. Для этого можно использовать кого-то из агрегаторов, чтобы не подключаться к разным нейронкам по отдельности, рассматриваю: Fal, Segmind, Replicate или Piper – потому что можно оплачивать доступ к API российской картой. Если вы разработчик, которому понравилась эта идея, и вы готовы поэкспериментировать в этом направлении – напишите мне, возможно, нам по пути, и мы сможем сделать что-то крутое вместе!
Буду рад, если вы оцените проект и поделитесь в комментариях, какие безумные персонажи и эпичные (или просто забавные) битвы у вас получились!
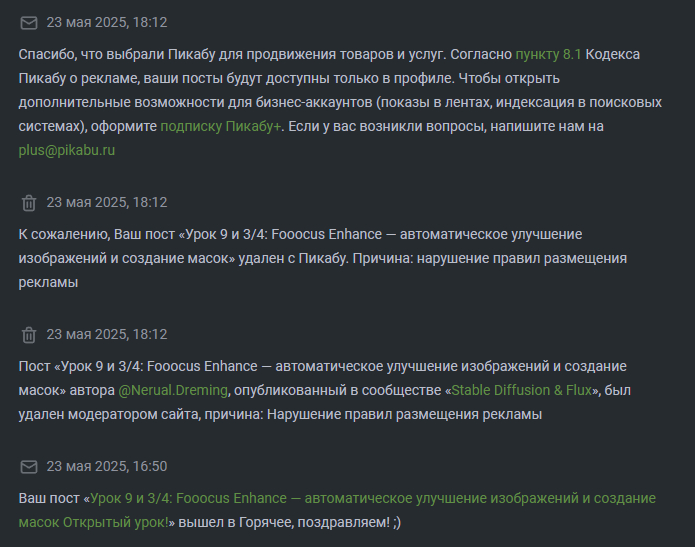
Этот день сегодня, я два с половиной года создавал контент, вел сообщество и развивался вместе с Пикабу. Пока Пикабу не решил, что может в одностороннем порядку нагибать своих авторов. Я выкладываю 30 минутный открытый урок в свое сообщество, урок является частью курса, указываю на этот курс ссылку - получаю удаление своего контента из закрепа.
Для меня, как для автора и администратора сообщества - это плевок в душу. Это не адекватно. Я не буду развивать такой сайт, который плюет на своих авторов.
Угадайте все культовые роли легендарного актера в кукольной-версии — без подсказок и напишите в комментариях!













Узнали все фильмы? Как спина? Поздравляю, тест на артрит пройден. Если опознали не всех, в комментариях будет список персонажей и названия фильмов.
А каких актеров, франшизу, или персонажей в таком стиле было бы интересно увидеть вам?

Генеративные нейросети уже изменили мир цифрового искусства, но настоящая магия начинается, когда ты сам берешь их под контроль. Сегодня расскажу о своем эксперименте по обучению LoRA на стиле South Park — от сбора датасета до финальной модели. Поделюсь реальным опытом, техническими нюансами и самое главное — что конкретно сработало, а что оказалось пустой тратой времени.
Меня зовут Илья, я основатель онлайн-нейросети для создания изображений ArtGeneration.me, техноблогер и нейро-евангелист.
Идея обучить LoRA на стиле мультсериала пришла ко мне случайно. На глаза попался новый анимационный сериал «Ваш дружелюбный сосед Человек-паук», и я подумал: «Было бы классно обучить LoRA именно на этом стиле!». Я уже обучал LoRA на отдельных персонажах и простых стилях, но на таких сложных и комплексных особо ещё не тренировал.
Но стиль человека-паука показался мне слишком сложным для первого эксперимента такого рода. Решил сначала потренироваться на чем-то попроще. И тут удачно подвернулась спешл-серия South Park! Стиль South Park простой, узнаваемый, многие его любят (включая меня). На Civitai уже была одна LoRA South Park, так что я подумал — если смог кто-то другой, то и я смогу!
Спойлер: всё оказалось гораздо сложнее, чем я думал. Но обо всём по порядку.
Первое, что нужно для обучения LoRA — качественный датасет. У меня была FullHD-серия South Park — идеальное качество для набора скриншотов. Осталось только придумать, как эти скриншоты делать быстро и удобно.

Для просмотра видео я использую MPV. Раньше сидел на MPC-HC, но он стал подтормаживать на некоторых 4K рипах, так что я переехал на MPV. Он не только быстрее, но и поддерживает кучу всяких приколюшек типа скриптинга. Хотя для наших целей хватит и встроенной функции скриншотов.
Функция сохранения кадров в MPV активируется нажатием клавиши S (только на английской раскладке, что важно). Но чтобы не хранить скриншоты где попало, стоит настроить плеер. Создаём файл конфигурации по пути C:\Users\[имя_пользователя]\AppData\Roaming\mpv\mpv.conf (можно быстро перейти через Win+R → %APPDATA%\mpv → Enter). Если папки mpv нет – создайте её.
Вот содержимое файла mpv.conf:
screenshot-directory="C:/Users/user/Pictures/Screenshots/mpv"
screenshot-template="%F/%P"
screenshot-format=png
save-position-on-quit=yes
resume-playback=yes
(Замените user на ваше имя пользователя)
Что делает каждая строчка: screenshot-directory задаёт путь для скриншотов, screenshot-template определяет формат имени (где %F - имя видео, %P - позиция), screenshot-format выбирает PNG для лучшего качества, а две последние строки заставляют плеер запоминать где вы остановились и автоматически продолжать с этого места при следующем запуске. Таким образом мы решаем и проблему скриншотов, и вечный вопрос — «а где я остановился в прошлый раз?».
Вооружившись настроенным MPV, я посмотрел несколько серий South Park, нажимая S в ключевые моменты. Это, кстати, гораздо веселее, чем может показаться — сидишь себе, ржёшь над Картманом и заодно собираешь датасет.
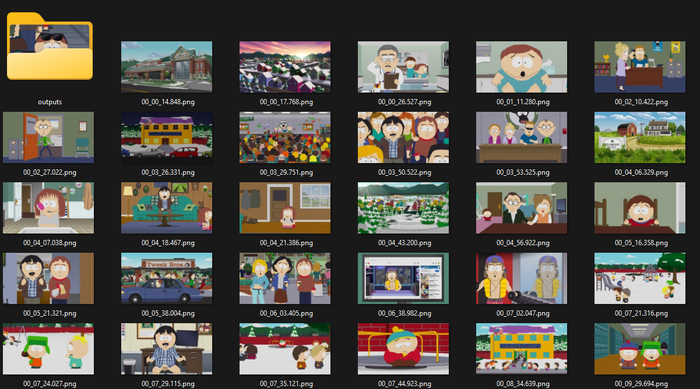
В итоге у меня набралось около 150 скриншотов. Но для качественного обучения мало просто надёргать кадров — нужно тщательно их отфильтровать: убрать смазанные кадры, выкинуть неудачные ракурсы, оставить только типичные для стиля примеры. Для тренировки LoRA на персонажа обычно достаточно ~30 изображений, а вот для стиля нужно больше — до 200. У меня осталось около 120 кадров после фильтрации.
Теперь встал вопрос обработки. Обучение модели будет проходить в разрешении 1024×1024, а мои скриншоты были другого формата. Без паники! Python-скрипт спешит на помощь!
Для тех, кто никогда не работал с Python, вот краткая инструкция: скачайте и установите Python с официального сайта, при установке поставьте галочку «Add Python to PATH», потом откройте командную строку (Win+R, введите «cmd») и выполните команду pip install pillow для установки библиотеки обработки изображений.
Теперь создайте текстовый файл с названием resize_images.py, вставьте в него код ниже, поместите файл в папку со скриншотами и запустите двойным кликом:
from PIL import Image
import os
# Создаем выходную директорию, если её нет
output_dir = "outputs"
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# Получаем все файлы изображений из текущей директории
image_extensions = ['.jpg', '.jpeg', '.png', '.bmp', '.gif', '.tiff', '.webp']
image_files = []
for file in os.listdir('.'):
if any(file.lower().endswith(ext) for ext in image_extensions) and os.path.isfile(file):
image_files.append(file)
# Обрабатываем каждое изображение
for i, file in enumerate(image_files):
try:
# Открываем изображение
img = Image.open(file)
# Принудительно конвертируем в RGB (убираем прозрачность)
img = img.convert('RGB')
# Получаем размеры изображения
width, height = img.size
# Определяем новые размеры, сохраняя соотношение сторон
if width > height:
# Если ширина больше высоты, устанавливаем ширину = 1024
new_width = 1024
new_height = int(height * (new_width / width))
else:
# Если высота больше ширины, устанавливаем высоту = 1024
new_height = 1024
new_width = int(width * (new_height / height))
# Изменяем размер изображения с сохранением пропорций
resized_img = img.resize((new_width, new_height), Image.Resampling.LANCZOS)
# Сохраняем с порядковым номером в формате PNG с максимальным качеством
output_path = os.path.join(output_dir, f"{i+1:03d}.png")
resized_img.save(output_path, format='PNG', optimize=True, compress_level=0)
print(f"Обработано {file} -> {output_path} ({new_width}x{new_height})")
except Exception as e:
print(f"Ошибка при обработке {file}: {e}")
print(f"Завершена обработка {len(image_files)} изображений.")
Этот скрипт делает несколько полезных вещей: сохраняет пропорции изображений, убирает прозрачность (чтобы не было проблем при обучении), нумерует файлы последовательно и оптимизирует PNG для лучшего качества. После запуска вы получите в папке outputs все обработанные изображения.
Следующий шаг — создание текстовых описаний (по-английски это называется captioning) для изображений. Нейросети учатся на парах «картинка + описание», и от качества описаний очень зависит результат.

Если бы я делал LoRA для чего-то безобидного, то использовал бы Florence-2 от Microsoft. Эта модель шикарно описывает обычные сцены и довольно быстрая. Но с South Park ситуация сложнее — там NSFW-контент, который Florence-2 не сможет нормально обработать (стесняется).
Я перепробовал кучу инструментов для создания описаний и в итоге остановился на Joy Caption Alpha Two. Эта модель меня покорила тем, что в ней есть более 19 различных настроек, разные типы описаний (включая стили Midjourney и Fusion) и основа на визуальной языковой модели, что даёт более подробные и точные описания.
Но возникла проблема — Joy Caption обрабатывает изображения только по одному, а у меня их 120! Сначала я искал готовые решения для пакетной обработки, но нашел только несколько cli, которые у меня даже не запустились. Пришлось закатать рукава и сделать свою локальную версию, за одно прикрутил к ней перевод и пакетный режим обработки.
Несколько вечеров кодинга (и некоторое количество психованных удалений файлов) — и я смог сделать работающую локальную версию с мультирежимом. Я хорошо потрудился, чтобы превратить это в портативную версию, которая запускается даже на видеокартах с 12 ГБ памяти.
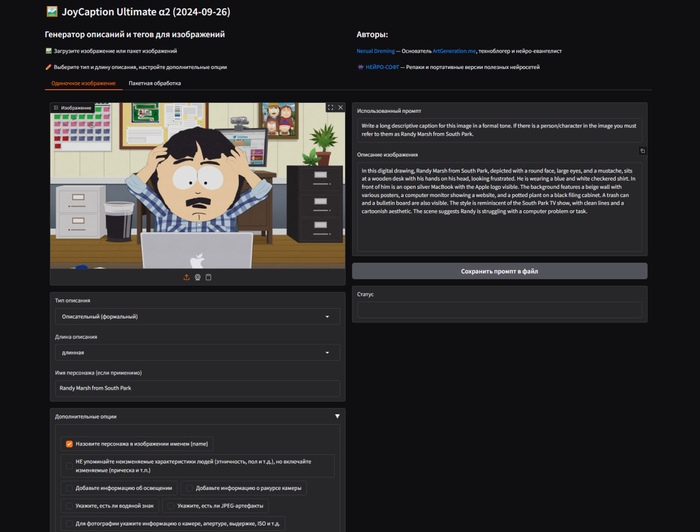
Результатом стал JoyCaption Ultimate α2, который я выложил на канал Нейрософт, где публикуются репаки и портативные версии различных нейросетей. Моя модификация умеет генерировать описания в 9 разных режимах, поддерживает расширенные инструкции, разные стили и длину описаний, а также позволяет визуально проверить и исправить неудачные промпты в пакетном режиме.

Обработка 120 изображений заняла около 5 минут на RTX 4090. Главное — результат получился отличный, с корректными описаниями всех особенностей стиля South Park. На выходе мы получаем папку с результатами, в которой лежат все картинки и у каждой есть txt файл с промптом.
Теперь, когда у меня был готовый датасет с картинками и описаниями, можно было приступать к самому обучению. Для этого я использовал FluxGym, установленный через Pinokio.
Pinokio — это удобный инсталлер для различных нейросетей. Установка проста: заходите на сайт, скачиваете, запускаете. Через интерфейс Pinokio находите FluxGym, жмёте Install, ждёте загрузки компонентов — и вуаля, у вас есть рабочий инструмент для обучения LoRA специально под модель Flux.

После запуска FluxGym появляется окошко с настройками. Я закинул свой датасет и настроил такие параметры:
Ранг: 4 (мне казалось, что для простого стиля South Park этого достаточно)
Эпохи: 13
Повторения: 10
Генерация сэмплов каждые 500 шагов
Добавил параметры --w 1280 --h 768 --s 20 для настройки превью, чтобы они генерировались с нормальным разрешением, а не стандартным 512×512
Запустил обучение и стал с нетерпением ждать результатов... И тут произошёл первый шок.
Результаты были... мягко говоря, неутешительными. Фоны получались более-менее нормальными, но персонажи — просто ужас какой-то. Месиво из десятков одинаковых Картманов, наложенных друг на друга, деформированные лица, непонятные конечности.

«Нет, это не очередной трип Паркера и Стоуна, это были мои плохо натренированные LoRA», — думал я, глядя на эту цифровую какофонию. Раньше я тренировал LoRA на персонажах, и никаких проблем не возникало. Почему же сейчас всё пошло не так?
Гуглинг подсказал, что для стилей, возможно, нужен более высокий ранг LoRA. Это влияет на глубину обучения — чем выше ранг, тем глубже модель может изучить особенности стиля.

Я решил попробовать обучение с рангом 128. Результаты стали лучше, но объем модели раздулся до полутора гигабайт! Решил попробовать компромиссный вариант: ранг 64, при котором LoRA весит примерно 500-600 МБ, что уже приемлемо.
Также я кардинально снизил скороть обучения. По умолчанию в FluxGym используется --learning_rate 8e-4, а я уменьшил до --learning_rate 2e-4, то есть в 4 раза. Это должно было предотвратить переобучение, но увеличило время тренировки. Вместо нескольких часов обучение заняло почти полдня. Но ради качества можно и подождать.
В процессе экспериментов я также пришел к выводу, что лучше ставить количество повторов равным 1, а желаемую продолжительность обучения регулировать числом эпох. Это даёт бóльшую гибкость и упрощает анализ результатов.
Примерно на 260-й эпохе я начал замечать явные признаки переобучения — множество зрачков в глазах персонажей, смазанные формы, снижение качества изображений. Пора было останавливаться. К тому времени обучение шло уже около суток.

Я решил остановиться на 255-й эпохе, и у меня получилось 90 файлов моделей с разных этапов обучения. Но как теперь понять, какая из них лучшая?

Для начала я написал простой скрипт, который создал мне список всех файлов в папке:
import os
from datetime import datetime
# Получаем текущую папку, откуда запущен скрипт
current_folder = os.getcwd()
# Имя выходного файла
output_file = 'file_list.txt'
# Открываем файл для записи
with open(output_file, 'w', encoding='utf-8') as f:
f.write(f"Список файлов в текущей папке: {current_folder}\n")
f.write(f"Дата: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n")
f.write("-" * 50 + "\n\n")
# Получаем список всех файлов в текущей папке и подпапках
for root, dirs, files in os.walk(current_folder):
# Получаем относительный путь от текущей папки
rel_path = os.path.relpath(root, current_folder)
if rel_path != '.':
f.write(f"\nПапка: {rel_path}\n")
else:
f.write("Текущая папка:\n")
# Записываем все файлы из этой папки
for file in sorted(files):
f.write(f" {file}\n")
print(f"Список файлов сохранен в {output_file}")
Затем скормив в ЛЛМ список, я составил последовательность для тестирования с равномерной выборкой примерно каждой 30-й эпохи:
<lora:sp64-000003:1>, <lora:sp64-000030:1>, <lora:sp64-000060:1>, <lora:sp64-000087:1>, <lora:sp64-000114:1>, <lora:sp64-000144:1>, <lora:sp64-000171:1>, <lora:sp64-000198:1>, <lora:sp64-000228:1>, <lora:sp64-000255:1>
Для тестирования я использовал Stable Diffusion WebUI Forge. Хоть этот форк A1111 и устаревает, он всё ещё удобен для многих задач. Особенно круто в нём работает скрипт X/Y/Z plot, который позволяет автоматически протестировать разные LoRA и получить наглядную таблицу.

Я использовал функцию PROMPT S/R (Search and Replace), чтобы автоматически перебрать все варианты LoRA. Для тестов я использовал такие промпты:
Digital drawing in South Park style A fat boy sits astride a cow, with a red barn behind him
Digital drawing in South Park style a policeman is sitting in a strip club, a naked stripper is showing her breasts on stage.
Digital drawing in South Park style tricycle chase, fat boy with glasses rides after red-haired boy in green ushanka hat, cinematic
Результаты тестирования, я небрежно сложил на онлайн доску, можно посмотреть.
После первых тестов я понял свою глупую ошибку — я тестировал на промте, похожем на те, что были в моём датасете! Так делать нельзя, ведь это не показывает реальную гибкость модели.
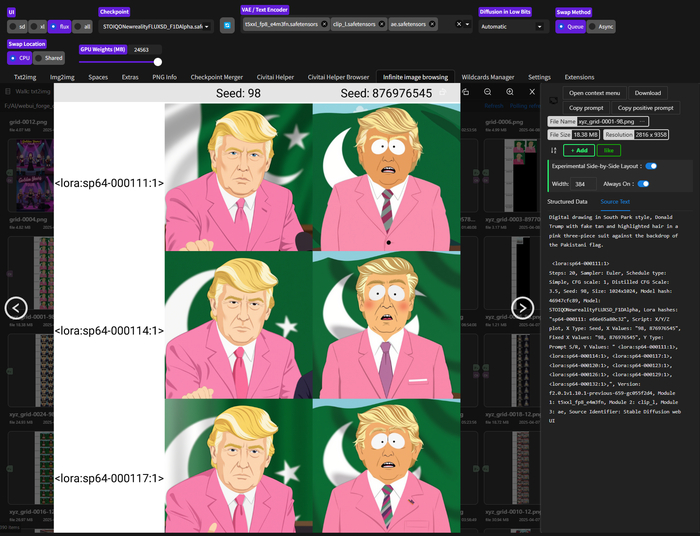
Я составил более короткие и совершенно другие промпты, и результаты оказались ГОРАЗДО лучше. Оказывается, проблема была не в моделях, а в моём тестировании!
После нескольких циклов тестирования я обнаружил несколько интересных закономерностей:

LoRA на ранге 128 выглядит интереснее, чем на ранге 4 — она глубже изучает стиль и не так топорно его применяет. Высокий ранг позволяет модели улавливать более сложные и нюансированные особенности стиля.
Чем ниже ранг, тем быстрее происходит переобучение, что было для меня сюрпризом. Я ожидал, что модели с высоким рангом будут быстрее переобучаться из-за большего количества параметров. На практике оказалось наоборот — высокий ранг позволяет обучаться более «аккуратно», с меньшим риском жесткой фиксации на обучающих примерах.
В итоге я остановился на ранге 64 и эпохе 114, которая дала лучший баланс стилизации без переобучения. Удивительно, но это только примерно треть от всего обучения — более поздние эпохи давали признаки переобучения.

Я проверил эту модель с разными весами (0.8 и 1.2), чтобы убедиться, что LoRA достаточно гибкая и работает предсказуемо при разных значениях. Результаты меня порадовали — даже при весе 0.8 стиль South Park был хорошо узнаваем, а при 1.2 не появлялись артефакты переобучения.

Обучение LoRA на стили оказалось гораздо сложнее, чем я предполагал. Вот главные уроки, которые я извлек:
Для стилей нужен гораздо более высокий ранг, чем для персонажей. Если для персонажа часто хватает ранга 4-8, то для стиля лучше ставить 64-128. Это связано с тем, что стиль — это комплексный набор визуальных особенностей, которые затрагивают множество аспектов изображения.

Чем ниже скорость обучения, тем более плавно происходит обучение, хотя и дольше. Для сложных стилей лучше уменьшить скорость в 3-4 раза от рекомендуемой и запастись терпением. Результат того стоит — меньше шансов получить переобученную модель.
Оптимальные эпохи часто находятся примерно в первой трети всего обучения. У меня лучший результат дала эпоха 114 из 255. Не бойтесь останавливать обучение раньше, если видите признаки переобучения.

Никогда (серьезно, НИКОГДА) не тестируйте LoRA на промтах, похожих на те, что были в датасете! Это даст вам ложное представление о качестве модели. Тестировать нужно на новых, совершенно других промтах, чтобы проверить гибкость и универсальность обученной LoRA.

Готовую LoRA я опубликовал на Civitai: South Park Style Flux LoRA.
Все примеры и тесты можно посмотреть на доске: Примеры и тесты.
Обучение LoRA на стили оказалось намного сложнее, чем я ожидал, но результат того стоил. Теперь я гораздо лучше понимаю процесс и готов браться за более сложные стили — возможно, даже за тот самый сериал про человека-паука, который изначально меня вдохновил.

А какие LoRA вы обучали? Делитесь своим опытом в комментариях!
Друзья, рад представить вам свой первый Lo-Fi альбом "Bulka Lo-Fi — Cozy Beats for Work & Chill"! Это коллекция из 8 уютных треков, созданных для идеального фона во время работы, учебы или просто расслабления.
Каждый трек наполнен теплыми мелодиями, глубокими басами и атмосферными звуками, которые помогут вам сосредоточиться и создадут приятную атмосферу.
Слушайте на любимой музыкальной площадке:
Яндекс Музыка: https://music.yandex.ru/album/36022783
VK Музыка: https://music.vk.com/link/fpJwy
МТС Музыка: https://music.mts.ru/album/36022783
Wink Музыка: https://music.wink.ru/release/38099939
Или смотрите музыкальное видео:
Авторы:
🟣Музыка и Дизайн: https://t.me/nerual_dreming
🟣Сведение и Мастеринг: https://t.me/wonderloveyou
🟣Сервис для создания музыки: https://www.udio.com/
🟣Сервис для создания видео: https://vizzy.io/
А если хотите научиться создавать музыку в нейросетях на таком же уровне, ждем вас в клубе https://neuromusic.club/ — всего за два месяца вы научитесь превращать мелодии, засевшие в голове, в настоящие музыкальные произведения!
Буду очень благодарен, если поддержите релиз лайками и добавите треки в свои плейлисты — это очень поможет продвижению и мотивирует на создание новых альбомов! 👍
🔊 Мой ТГ канал Нейро-Звук про синтез музыки и аудио

Привет друзья! Вы наверняка уже знаете, что недавно ChatGPT получил обновление с революционной функцией генерации изображений. Новая технология, основанная на модели GPT-4o, генерирует картинки как никто другой на рынке! За первую неделю после запуска более 130 миллионов пользователей создали свыше 700 миллионов изображений – это настоящий бум! Уверен вы видели или даже сами делали Ghibli-фикацию – изображения в стиле аниме студии Гибли. Но что еще крутого может делать новая генеративная модель?
Меня зовут Илья, я основатель онлайн-нейросети для создания изображений ArtGeneration.me, техноблогер и нейро-евангелист. И я провел глубокое исследование, чтобы собрать для вас полный список из более чем 60 стилей и приемов, которые реально работают в обновленном ChatGPT. Это только проверенные примеры промптов с Reddit и других источников. Кроме того, расскажу об особых режимах работы, ограничениях и технических деталях.

Вы можете загрузить несколько изображений как референсы, и ChatGPT создаст новое изображение, объединяющее элементы загруженных. Например, можно загрузить фото четырех отдельных предметов (лосьон, мыло, аромапалочки и бомбочку для ванны), и попросить создать изображение подарочной корзины с этими товарами.
Пример промпта для объединения референсов:
Generate a photorealistic image of a gift basket on a white background labeled 'Relax & Unwind' with a ribbon and handwriting-like font, containing all the items in the reference pictures.

Или вот еще пример:
Объедини все эти изображения в один плакат, горизонтальное соотношение, название Хамон из Снорка – Любимый деликатес сталкеров. на столе стоит хамон, за окном вид на Припять, на столе так же лежит противогаз и на фоне сидит сталкер.

Результат получается впечатляющим! Это открывает огромные возможности для создания композиций из разных объектов, каталогизации товаров или дизайна.
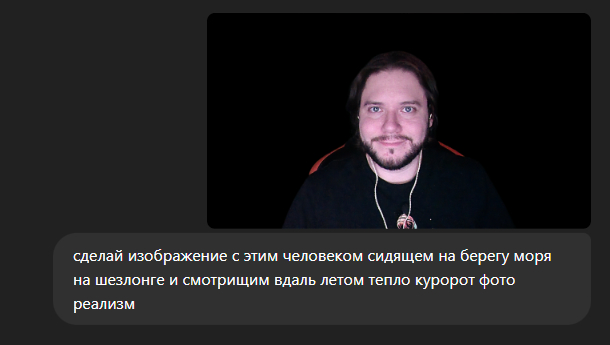
Вы можете загрузить свое (или чужое) фото и попросить чат гпт использовать его в качестве референса.

Получается очень классно, теперь и в отпуск можно не ехать.

Конечно, теперь с собой в качестве главного героя можно сделать что угодно, например советский плакат.
Промпты достаточно простые, кидаем свою фотку и пишем: Сделай советский агит плакат с этим парнем, держащим в руках полную тарелку пельменей со сметанкой и укропом сверху и подписью "Кто не работает – тот ест!"

Теперь вы легко можете создать фотографии в интерьере для любого продукта, особенно оценят продавцы на маркет плейсах.

И работает это действительно хорошо, я бы сказал слишком хорошо, чтобы быть правдой.
Уже жду в комментариях к посту ваши мемные продукты и товары.
Теперь вы можете не просто воссоздать стиль, вы можете взять стиль и создать в этом стиле совершенно новый предмет.

Я для примера взял из гугла вот этот ламповый усилитель, и подумал – а было бы круто сделать к нему еще пару колонок и мультимедийный плеер правда?

Ну и дальше мы с вами уже научились как посмотреть это в интерьере, скажем, на фоне камина. Чтобы как в каталогах с дорогой техникой.

Осталось выйти с этими примерами дизайна на китайскую фабрику и начать производство, как говорится, охапка дров – Hi-Fi готов.

Аутпеинтинг теперь тоже не проблема, достаточно скинуть изображение и написать куда его дорисовать.
Работает не идеально, у меня вот вместо группы Beatles получилась группа BTS.

Вроде бы и похоже и нет, а все потому, что это не настоящий аутпеинтинг, а просто перерисовка всей картинки. Такая же история и с колоризацией.

Просто командой Сделай это фото цветным его можно покрасить, но на самом деле это тоже будет уже совсем другое фото. А еще у меня много ругался на исторические снимки и не хотел их раскрашивать.
Может показаться, что это одно и то же изображение, но если посмотрите внимательнее, то увидите разницу, оно воссоздано.

Но в качестве развлечения на вечер для домочадцев, если у вас есть альбом черно-белых фоток – подойдет.
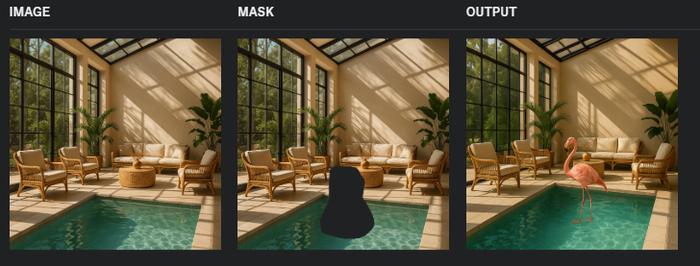
В ChatGPT есть полноценный инпейнтинг. Вы загружаете изображение и маску, где прозрачные области маски будут заменены, а черные области останутся без изменений. При этом можно описывать полное новое изображение, а не только редактируемую область.
Пример промпта для инпейнтинга:
A sunlit indoor lounge area with a pool containing a flamingo
Как на примере с фото солнечной комнаты, где в бассейн добавлен фламинго. Маска может быть простым черным пятном с прозрачной областью там, где вы хотите внести изменения. Важно: маска должна иметь альфа-канал прозрачности и быть того же размера, что и исходное изображение.
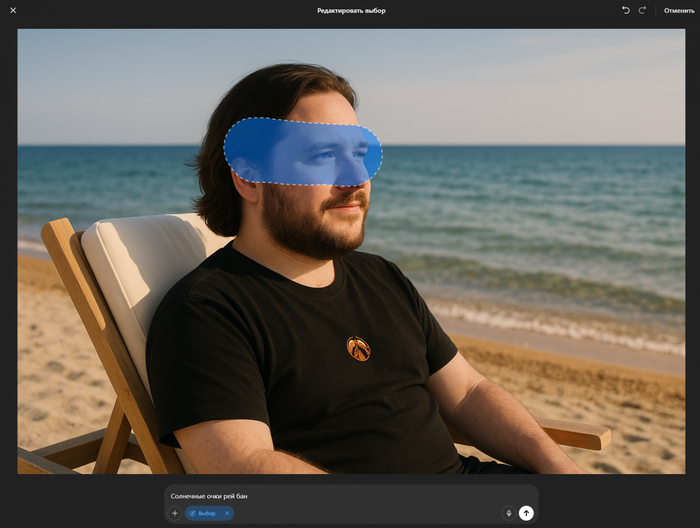
Через веб интерфейс же все еще проще. Просто выделите часть изображения и напишите промпт.
И вот отличный результат, в отпуск не еду, очки не покупаю. У меня уже "все было".

Из-за огромной популярности функции OpenAI ввела временные ограничения:
Бесплатные пользователи: около 3 изображений в день (может меняться в зависимости от нагрузки)
Платные подписчики: возможность сгенерировать подряд достаточно много изображений (десятки), но потом генератор ограничивает доступ на 15 минут, после чего возможность снова восстанавливается

В качестве примера я буду изменять обложку из одного из моих роликов. Изначально она была сгенерирована через Flux, но для нас это никакой роли не играет. Конечно меня бы не хватило на все стили, но многие я попробовал и показываю вам. Но из-за того, что на Пикабу ограничение в 25 картинок - вы увидите тут еще меньше.
Студия Ghibli: "Transform this image into a gentle, detailed Studio Ghibli-style scene with magical backgrounds and warm lighting."
Disney Animation: "Make this image look like a bright, lively Disney animation frame with expressive faces and glossy color."
Pixar: "Turn this image into a Pixar movie style with 3D modeling, shiny materials, and cinematic lighting."
Toy Story: "Restyle this image to look like a Toy Story frame with plastic textures and playful toy-like shapes."
Cars (Pixar): "Transform this image into a Cars universe scene, full of cartoon vehicles and reflective surfaces."
Minions: "Reimagine the subjects of this image as Minions, with yellow skin, goggles, and cheeky personalities."

Adventure Time: "Draw this image in Adventure Time style: thin black lines, simple shapes, and quirky fantasy details."
The Simpsons: "Make this image look like a Simpsons cartoon scene with yellow characters, Springfield vibes, and cartoon shading."
Chibi: "Convert this image to chibi style with tiny, cute bodies and large, shiny eyes."

Rubber Hose / Cuphead: "Restyle this image in 1930s rubber hose animation, with noodle limbs and vintage cartoon faces."

Mario Bros: "Convert this image to a Mario Bros pixel world with chunky colors and playful Nintendo elements."
Voxel Art: "Transform this image into voxel art with blocky, 3D cubes and simplified details."
8-bit Video Game: "Make this image look like an 8-bit video game screenshot, with chunky pixels and a limited palette."
16-bit Video Game: "Turn this image into a 16-bit video game scene with pixel art sprites and bright backgrounds."
LEGO: "Turn this image into a LEGO world, where everything is made of plastic bricks."
Peanuts: "Redraw this image as a Peanuts comic panel with hand-drawn lines and soft pastel backgrounds."
1940s Comics: "Turn this image into a 1940s comic book page with halftone textures and dramatic retro inking."
1950s Comics: "Restyle this image in the bold, bright look of a 1950s comic, using strong colors and classic comic fonts."
Manga: "Make this image a manga illustration with screentone shading and detailed black-and-white linework."
Pop Trading Card: "Transform this image into a shiny pop-art trading card with bold borders and collectible card style."
Lo-fi: "Render this image in cozy lo-fi art style with soft analog colors, gentle blur, and mellow atmosphere."
Vaporwave: "Convert this image into vaporwave with neon pinks, Greek statues, and retro grid backgrounds."
Synthwave: "Make this image synthwave style with glowing neon grids, sunsets, and futuristic cityscapes."
Cyberpunk: "Restyle this image in cyberpunk, full of rain-soaked streets, neon signage, and futuristic energy."
Steampunk: "Turn this image into steampunk with brass gears, Victorian fashion, and steam-powered devices."
Retro-futurism: "Turn this image into retro-futurism with 60s/70s sci-fi, chrome details, and optimistic technology."
Dreamcore: "Restyle this image in dreamcore with liminal spaces, surreal colors, and nostalgic mood."
Stickerbomb: "Restyle this image with stickerbomb collage, layering various sticker styles and graffiti tags."
Art Nouveau: "Transform this image into Art Nouveau, featuring flowing lines, ornate floral motifs, and decorative frames."
Art Deco: "Restyle this image as Art Deco, with geometric patterns, gold highlights, and symmetrical design."
Renaissance Painting: "Render this image in a Renaissance painting style, with classical poses, oil texture, and soft light."
Baroque: "Make this image a dramatic Baroque painting, full of contrast, ornate detail, and expressive light."
Impressionism: "Restyle this image as impressionist art, with visible brushstrokes, lively color, and dreamy atmosphere."
Cubism: "Transform this image into a Cubist piece, with fragmented geometry and multiple viewpoints."
Pop Art: "Make this image pop art style, using flat colors, thick outlines, and comic speech bubbles."
Gothic Art: "Transform this image into Gothic art, with pointed arches, stained glass, and dark romance."
Surrealism: "Turn this image into surrealist art, full of bizarre compositions and dreamlike visuals."
Ukiyo-e: "Convert this image into a Japanese ukiyo-e woodblock print with elegant outlines and flat colors."
Oil Painting: "Render this image as an oil painting, with deep colors and textured brushwork."
Watercolor: "Transform this image into watercolor with delicate washes, soft blending, and light paper texture."
Pencil Sketch: "Restyle this image as a pencil sketch, with cross-hatching, rough lines, and grayscale shading."
Charcoal Drawing: "Make this image into charcoal art with bold, rough strokes and strong shadows."
Stained Glass: "Turn this image into stained glass, with black outlines and glowing jewel-toned glass sections."
Mosaic: "Convert this image into a colorful mosaic made of tiny tiles and stone patterns."
Embroidery: "Make this image look embroidered, with stitched outlines, colorful threads, and fabric texture."
Chalkboard Art: "Restyle this image as chalkboard art, with white chalk sketches on a dark background."
Claymation: "Make this image into a claymation scene with modeling clay textures and stop-motion look."
Origami: "Render this image as an origami scene, using folded paper shapes and crisp creases."
Patch Embroidery: "Render this image as a patch embroidery design, with simple shapes and border stitches."

Patchwork Quilt: "Turn this image into a patchwork quilt, with fabric squares and visible stitches."
Flat Design: "Turn this image into flat design, with solid colors, clear shapes, and no gradients or shadows."
Minimalist Sticker: "Transform this image into a minimalist sticker, using bold outlines, tiny details, and a cute vibe."
Doodle Art: "Make this image look like playful doodle art, with random sketches, squiggles, and hand-drawn icons."
Infographic: "Turn this image into a clean, informative infographic with icons, labels, and easy-to-read layout."
UI/UX Mockup: "Render this image as a modern UI/UX mockup, with crisp interface elements and clean grids."
Children's Book: "Restyle this image for a children's book with soft shapes, pastel backgrounds, and playful details."
Fantasy Storybook: "Transform this image into a fantasy storybook illustration with enchanting scenery and magical lighting."
Peter Rabbit: "Transform this image into an elegant Peter Rabbit storybook illustration with soft, classic watercolor."
Fashion Illustration: "Make this image a high-fashion illustration, with elongated figures and elegant clothing details."
Tattoo Art: "Restyle this image as tattoo art, with bold outlines and limited ink shading."
Graffiti Street Art: "Turn this image into colorful graffiti street art, with spray paint, urban motifs, and rough outlines."
Psychedelic Art: "Make this image psychedelic, with bright swirling patterns and mind-bending colors."
Noir: "Make this image a film noir still, with dramatic black and white contrast and moody shadows."
Polaroid Photo: "Render this image as a black and white Polaroid photo, with film grain and vintage fade."
LensPilot Camera: "Make this image look like it was shot with a LensPilot camera, with unique analog textures."
Лучшие результаты получаются при использовании следующей структуры запроса:
Действие: начинайте с глагола (Transform, Make, Turn, Render)
Объект: что именно изменить ("this image", "this photo")
Целевой стиль: конкретное название стиля
Детали стиля: 2-3 ключевых характеристики
текстуры ("plastic textures", "film grain")
цвета ("neon pinks", "soft pastel")
техники ("visible brushstrokes", "cross-hatching")
атмосфера ("dreamlike visuals", "nostalgic mood")
Для сложных композиций можно использовать структурированный JSON-формат:
{ "Subject": "Elderly couple on a park bench", "Style": "monochrome:1.2, black and white Polaroid, vintage", "Composition": "centered, square format, candid framing", "Lighting": "soft natural light, slight vignetting", "Finish": "film grain, white border, subtle fade", "NegativePrompt": "color, blur, watermark, modern" }
Конечно же фактически модель не обрабатывает промпт именно в таком виде, а переводит его в свой формат, так что вы можете не переживать за синтаксис, это нужно для вашего удобства и структурированного ввода.
OpenAI уже выпустила API gpt-image-1, позволяющий интегрировать новый генератор изображений в сторонние приложения. По отзывам экспертов, модель превосходит конкурентов (включая Midjourney-v7) по точности исполнения запросов, особенно когда нужно следовать сложным инструкциям.
При генерации доступны размеры 1024x1024 (квадрат), 1536x1024 (пейзаж) и 1024x1536 (портрет), три уровня качества (низкое, среднее, высокое), форматы PNG, JPEG и WebP с контролем сжатия, а также возможность прозрачного фона для PNG и WebP.
Ценообразование основано на токенах с тремя разными тарифами: текстовые токены для запросов ($5 за миллион), входные токены для референсных изображений ($10 за миллион) и выходные токены для результатов ($40 за миллион).
Стоимость квадратного изображения 1024×1024 составляет $0.02 при низком качестве (272 токена), $0.07 при среднем (1056 токенов) и $0.19 при высоком (4160 токенов). Портретные (1024×1536) и пейзажные (1536×1024) изображения стоят примерно $0.03 при низком качестве, $0.09 при среднем и $0.25 при высоком.
Интеграцию с gpt-image-1 уже внедряют Adobe в продукты Creative Cloud, Firefly и Express; Figma и Canva в свои дизайн-платформы; GoDaddy для создания логотипов; HubSpot для маркетинговых материалов; Instacart для визуализации рецептов и списков покупок; а также Invideo для своих редакторов.
Официальный API gpt-image-1 от OpenAI требует пройти верификацию организации через сторонний сервис whitepersona, что создает сложности для многих разработчиков. Альтернативой могут служить агрегаторы и провайдеры, которые упрощают доступ. Российский сервис Piper.my уже предоставляет доступ к этому API через свой "народный оркестратор нейросетей", а также ожидается, что популярные платформы Together AI, Fireworks.ai и Fal.ai в ближайшее время добавят поддержку gpt-image-1. Это существенно расширит возможности для независимых разработчиков и небольших команд, которым сложно пройти официальную верификацию.
При разработке API gpt-image-1 особое внимание уделено безопасности. Система защиты работает по тем же принципам, что и в веб-версии ChatGPT-4o, обеспечивая надежную фильтрацию контента.
Система защиты включает автоматические блокировки для предотвращения генерации контента, нарушающего правила использования. Каждое созданное изображение автоматически маркируется метаданными C2PA, что позволяет подтвердить его происхождение.
Разработчикам доступен параметр moderation с двумя режимами: стандартный (auto) с полной защитой и облегченный (low) с менее строгими фильтрами для определенных случаев использования.

Новый генератор изображений в ChatGPT — настоящий прорыв в области генеративного ИИ. Широкий спектр стилей, высокое качество результатов и удобные режимы редактирования делают его мощным инструментом для творчества. Несмотря на временные ограничения, вызванные огромной популярностью, эта технология уже меняет подход к созданию визуального контента и открывает новые возможности как для обычных пользователей, так и для бизнеса.
Всем хай! В новом выпуске нейроподкаста делюсь результатами исследования современного языка, которое изначально провел для своего музыкального проекта. Погружаемся в мир современного сленга, разбираем источники новых слов и смотрим, как меняется язык в разных контекстах — от TikTok до рэп-культуры.
Альтернативный плеер YouTube
Ссылки из видео:
Мои ссылки:
Буду рад вашей подписке и поддержке. Всех обнял и удачных генераций.





