Хочу поделиться с разработчиками своим опытом научного поиска. Изобретать велосипед хорошо только в учебных целях. Но весело :)
Любая работа по программированию начинается с анализа предметной области. Надёжнее всего использовать материалы из рецензируемых научных изданий (отечественные ВАК и РИНЦ, зарубежные WebOfScience и Scopus — напрямую из РФ недоступны). Наличие рецензирования обычно позволяет отбросить плохие статьи, что в целом повышает качество оставшихся статей. Могу порекомендовать для русского и английского поиска такие ресурсы
Киберленинка — open science платформа
ResearchGate — соц сеть для учёных (англ).
Google.Академия — сбор знаний отовсюду
ArXiv — сборник препринтов, то есть незавершённых исследований
Мне меньше нравятся, но тоже хороши:
eLibrary — собственно, сам РИНЦ
IEEE Xplore
Semantic Scholar
Springer
У большинства современных рецензируемых статей есть DOI. Отсутствие не страшно, но в современном мире удивительно.
В начале ищутся самые популярные статьи, потом следует подкрутить фильтры и взять самые свежие (не старше 5 лет, не старше 3 лет — зависит от области знаний). Большую часть усилий стоит сосредоточить на англоязычных источниках, там самый свежий и актуальный материал.
Если статья интересная, но отсутствует в открытом доступе, можно погуглить "название статьи filetype:pdf" в гугле. Нередко так можно найти PDF от автора, препринт или статьи, которые на искомую ссылаются.
Видео примеры по тегам можно искать по размеченным видео с ютуба.
Интересные рассмотренные статьи необходимо заносить в список с небольшой аннотацией. Такой список позволит в большей степени понимать и ориентироваться в предметной области. и синхронизировать усилия нескольких людей. Например,
1. <ссылка>. Работа на "хорошо". В работе есть данные по нейросети, которая с 80% точностью распознаёт человека в маске. Ссылка на программу есть, на датасет нет. Напрямую применить нельзя, но можно взять часть про нормализацию кадра
2. <ссылка>. Выглядела на "отлично", по факту бред. Литературы нет, написано на коленке
Примеры разобранных статей в области видеоаналитики:
1. Многокритериальная оценка качества фотографий. В статье рассматриваются различные критерии качества изображений, а также их количественная оценка. Из полезного: оценка резкости изображения, что может быть полезно для выделения одного наиболее информативного кадра в потоке на заданном промежутке времени. Есть математические операции по подсчету, а также примеры использования OpenCV для получения количественных оценок
2. Алгоритмы предобработки изображений в системе идентификации лиц в видеопотоке. В статье описывается алгоритмы предобработки изображений для их последующей обработки. Сюда входит
— Обесцвечивание
— Выравнивание гистограммы яркости изображения
— Выравнивание изображения относительно вертикальной оси симметрии лица (по возможности)
— Масштабирование
3. Video data quality improvement methods and tools development for mobile vision systems. В статье производится сравнение подходов однопоточной и многопоточной мобильной обработки видео, зависимость скорости обработки видео от его разрешения, а также приводятся примеры перехода из пространства RGB в YUV на OpenCV с целью оценки освещенности изображения
4. Age + Gender Estimation in Android with TensorFlow. Приложение под Android, определяющее пол и возраст человека на изображении. Прилагаются скриншоты результатов распознавания. Если с точностью определения пола все хорошо, то c определением возраста как-то не очень (числовые оценки не приводятся). Есть ссылки на датасет и блокноты в Colab, которые экспортируют модели TFLite (используется в приложении для Android). Из полезного можно вынести на мобилку модель для определения пола.
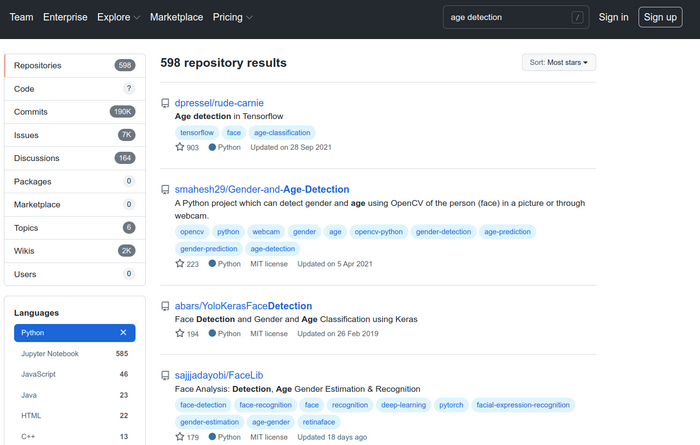
Очень важно изучить существующие открытые проекты на github. Например, если мы пытаемся по видеоряду определить возраст человека и всё делаем на питоне, то можно поискать age detection и выбрать ограничение на python. На текущий момент в поиске будет почти 600 проектов. Их берём и разбираем — есть ли документация, можно ли запустить, свежее ли, есть ли описание. Если что-то можно переиспользовать (с оглядкой на лицензию) — то переиспользуем.
В телеграм-канале разбираем разные нюансы из жизни разработчика на Python и не только — python, bash, linux, тесты, командную разработку.
PS: спасибо Александре Элбакян за sci-hub