Новый ноутбук 2: скорость, плюсы-минусы, DiskSPD, Hyper-V и далее
Для лиги лени: привыкание к новому и бесполезные тесты часть следующая. И немного powershell
Начало тут:
Тестирование локальных дисков и систем хранения данных: подводные камни. Часть 1 - общая
Тестирование локальных дисков и систем хранения данных: подводные камни. Часть 2 - виртуализация
Тестирование локальных дисков и систем хранения данных: подводные камни. Часть 3 – цифры и предварительные итоги
Тестирование локальных дисков и систем хранения данных: подводные камни. Часть 4 – что там изнутри виртуализации
Новый ноутбук: скорость, плюсы-минусы, DiskSPD, Hyper-V и продолжение про методику тестирование скорости
Решил я доделать сбор статистики перед тем, как что-то смотреть изнутри виртуалки, тем более вложенной виртуализации.
Предупреждение еще раз. Все данные ниже можно принимать во внимание, но не стоит рассматривать как какой-то эталон.
Что получил:
Один тред, один файл, блок 4k на чтение.
1 Влияние длины очереди. Тут была таблица, но не вставилась, поэтому просто цифрами:
После очереди == 4, нагрузка не растет, около 90k IOPS
2 Влияние числа тредов и числа файлов в работе на общий IOPS
Примечание: для 2 и 3 файлов – один файл был размещен на другом логическом диске
Тут тоже была таблица, но мне лень вставлять ее даже картинкой. На картинке опечатка, везде k, тысячи IOPS.

IOPS
Затем общий IOPS не рос.
До 10 тредов IOPS на поток падало – с 40 тысяч при 1 треде на каждый файл.
При соотношении 2 файла \ 3 треда, всего 6 тредов, и 3 файла \ 2 треда – выйдя на примерно 40k IOPS на поток, при 4 тредах и 3 файлах просев до 33-35 k IOPS на поток
На 14 (7\2) и 15 (5\3) тредах начинает падать IOPS\thread – с 35 до 17.
На 14 – 10 по 35k, 4 по 17k
на 15 – 9 треда по 35k, 3 треда по 17k.
Что отлично укладывается в логику 12 тредов CPU, из которых 9 работают на один тред, генерируя по 35k, и 3 CPU потока обрабатывают по 2 дисковых треда по 17k.
На 24 тредах (2 файла \ 12 тредов и 3 файла \ 8 тредов) картинка та же – все треды примерно по 17.5 IOPS
На 26 тредах (2\13 и 3\12) -4-6 потоков падают до 10k IOPS \ thread. Суммарно те же 40k
И для записи, пиковое значение было получено при 2 тредах на каждый их 3 файлов, 240k IOPS итого, по 40k IOPS на тред. Затем было только хуже –
Например, на казалось бы ПОЧТИ то же самое, 3 треда на два файла – производительность упала до 20k на тред, 120k IOPS.
На 4 потоках на файл, 12 файлах – производительность вроде бы была 210k, но есть разброс – от 15 до 20k IOPS на тред, перемерять надо.
На этом обзор физики можно и закончить, с выводами:
AMD потоки работают интереснее, чем у Intel, в именно этой реализации.
Максимальная производительность по чтению по дисковым операциям на физическом хосте достигается на числе потоков данных = числу потоков CPU
Производительность на чтение от очереди зависит достаточно слабо, то есть на очереди 8 выжало не 430, а 440k IOPS, на очереди 16 и 32 – 450k IOPS.
Внезапно, наловил ошибок – удалил старые файлы тестов, а новые, с тем же именем, не создаются!
There has been an error during threads execution
Error generating I/O requests
Оказалось, в какой-то момент в середине ночи удалил параметр с размером файлов. Случайно. И даже не заметил. Поправил и завелось.
И, наконец, влияние read-modify-write для любителей дисков потолще.
Показать не удалось, потому что:
Картина на файле 10 гигабайт и длительности записи 10 секунд и прогреве W=10

Картина приплыли на файле 200 гигабайт при прогреве W=2
До этого прогрев был W=10. И, в таблице ниже, 3.5k это не опечатка, 3500 IOPS

Везде забыл проставить k, это тысячи IOPS
Как бы так сказать, что при таком разбросе данных, это не тестирование, а полная и беспросветная лажа?
Потому что ничего не понятно, кроме того, что не зря замерял при разных параметрах. Получить лажу и увидеть ее полезно.
Перейдем к SQLsim.
Для опытов был взят Microsoft® SQL Server® 2019 Express,
Будете ставить – не забывайте сразу качать SQL Server Management Studio, пригодится.
файл отдельно не качается (я не нашел), поэтому скачал, поставил и вот -
C:\Program Files\Microsoft SQL Server\MSSQLXX.<InstanceName>\MSSQL\Binn
В GUI варианте теста «по умолчанию» ничего сложного – размеры файлов, размещение, число циклов, длина теста. Просто, наглядно.
Одна проблема – по умолчанию на 1 цикл поставлено 600 секунд (10 минут), и 12 циклов – то есть базовый тест – это два часа.
В конце теста генерируется sqliosim.log.xml.
Вторая проблема: тест не выдает в итоге каких-то цифр, типа «вы молодец, давайте дальше» - только таблицу
Display Monitor ********** Final Summary for file sqliosim.ldx ********** CLogicalFile::OutputSummary fileio.cpp
Display Monitor File Attributes: Compression = No, Encryption = No, Sparse = No CLogicalFile::OutputSummary fileio.cpp
Display Monitor Target IO Duration (ms) = 100, Running Average IO Duration (ms) = 0, Number of times IO throttled = NN, IO request blocks = NN CLogicalFile::OutputSummary fileio.cpp
Display Monitor Reads = NN, Scatter Reads = 0, Writes = NN, Gather Writes = 0, Total IO Time (ms) = NN CLogicalFile::OutputSummary fileio.cpp
Display Monitor DRIVE LEVEL: Sector size = 512, Cylinders = NN, Media type = NN, Sectors per track = 63, Tracks per Cylinders = 255 CLogicalFile::OutputSummary fileio.cpp
Display Monitor DRIVE LEVEL: Read cache enabled = Yes, Write cache enabled = Yes CLogicalFile::OutputSummary fileio.cpp
Display Monitor DRIVE LEVEL: Read count = BB, Read time = BB, Write count = BB, Write time = NN, Idle time = NN, Bytes read = NN, Bytes written = NN, Split IO Count = 0, Storage number = NN, Storage manager name = VOLMGR CLogicalFile::OutputSummary fileio.cpp
Я молодец, ок, а дальше что?
Конечно, если вы молодец (как я), то будете смотреть не только в окно самой программы, а запустите resmon и будете смотреть нагрузку по дискам, очереди, задержки, etc.
Перейду к hammerdb .. но это уже другая история.
В следующих сериях, теперь уже точно!
Опыты на виртуальной машине на 3 ядра.
CPU affinity
Опыты на Debian внутри Hyper-V, опыты с Proxmox nested. Stay tuned!
Литература
Performance benchmark test recommendations for Azure NetApp Files
Azure NetApp Files regular volume performance benchmarks for Linux
Hidden Treasure Part 1: Additional Performance Insights in DISKSPD XML
Hidden Treasure Part 2: Mining Additional Insights
Command line and parameters
Customizing tests
Use an XML file to provide DiskSpd parameters
Use the SQLIOSim utility to simulate SQL Server activity on a disk subsystem
SQL Server I/O Basics, Chapter 2
Use the SQLIOSim utility to simulate SQL Server activity on a disk subsystem on Linux
SQLIOSim Create a realistic I/O load for stress-testing SQL Server 2005
PS
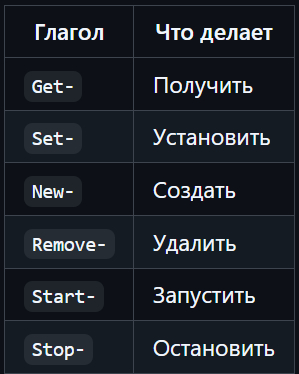
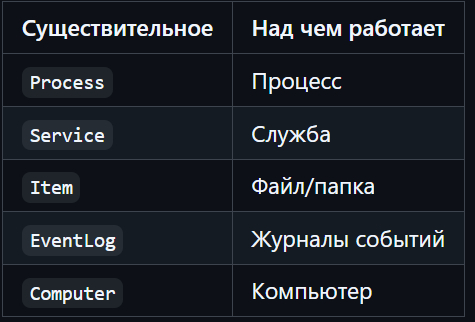
И немного powershell.
Часть 1, которую вы уже видели
$pciStats = (Get-WMIObject Win32_Bus -Filter 'DeviceID like "PCI%"').GetRelated('Win32_PnPEntity') |
foreach {
# request connection properties from wmi
[pscustomobject][ordered]@{
Name = $_.Name
ExpressSpecVersion=$_.GetDeviceProperties('DEVPKEY_PciDevice_ExpressSpecVersion').deviceProperties.data
MaxLinkSpeed =$_.GetDeviceProperties('DEVPKEY_PciDevice_MaxLinkSpeed' ).deviceProperties.data
MaxLinkWidth =$_.GetDeviceProperties('DEVPKEY_PciDevice_MaxLinkWidth' ).deviceProperties.data
CurrentLinkSpeed =$_.GetDeviceProperties('DEVPKEY_PciDevice_CurrentLinkSpeed' ).deviceProperties.data
CurrentLinkWidth =$_.GetDeviceProperties('DEVPKEY_PciDevice_CurrentLinkWidth' ).deviceProperties.data
} |
# only keep devices with PCI connections
Where MaxLinkSpeed
}
$pciStats | Format-Table -AutoSize
Get-CimInstance -ClassName Win32_Volume | Select-Object DriveLetter, FileSystem, BlockSize| Format-Table -AutoSize
$Path001 = 'C:\DiskSpd\amd64\'
$Sp = $Path001 + "diskspd.exe"
cd $Path001
$Rn = Get-Random -Minimum 1 -Maximum 10
$Version = "070_" + $Rn
$Drives = @("C")
$FilesTemp = "Data4del"
$File001 = "deleteme_01a.dm"
$File002 = "deleteme_02a.dm"
$File003 = "deleteme_03a.dm"
$Out021 = $Drives[0] + ':\' + $FilesTemp + '\' + $File001
$Out022 = $Drives[0] + ':\' + $FilesTemp + '\' + $File002
$Out023 = "D" + ':\' + $FilesTemp + '\' + $File003
# $OutsFilesAA = @("$Out021", "$Out023", "$Out021 $Out022","$Out021 $Out023","$Out021 $Out022 $Out023") - не работает вот так и все.
$OutsFilesAA = @( "$Out022")
$Logs = @()
$Threads = @("-t1","-t2", "-t3", "-t4","-t5","-t6","-t7","-t8","-t9","-t10","-t11","-t12","-t13","-t14","-t15")
# $Threads = @("-t1")
# $Write = ("-w0","-w30", "-w100")
$Write = @("-w100")
#$BlockSize = ("-b4k","-b8k")
$BlockSize = @("-b4k")
# $Outstanding = @("-o2","-o4","-o8","-o16","-o32")
$Outstanding = @("-o2")
$Size = "-c200G"
$Time = "-d10"
foreach ($OutFilesGr in $OutsFilesAA){
foreach ($Drv in $Drives){
foreach ($Bl in $BlockSize) {
foreach ($Wr in $Write) {
foreach ($Outs in $Outstanding){
foreach ($T1 in $Threads){
$TimeNow = get-date -UFormat "-%d-%m-%Y-%R" | ForEach-Object {$_ -replace ":","-"}
Write-Host "TT " $TimeNow
$Out001 = $Drv + ':\' + $FilesTemp + '\' + $File001
$Out002 = $Drv + ':\' + $FilesTemp + '\' + $File002
$Out003 = "D" + ':\' + $FilesTemp + '\' + $File003
$Stat1 = $Drv + ':\' + $FilesTemp + '\' + $Version + $TimeNow + "_" + $T1 + $Drv + $Outs + $T1 +'_1.log'
$Stat2 = $Drv + ':\' + $FilesTemp + '\' + $Version + $TimeNow + "_" + $T1 + $Drv + $Outs + $T1 +'_2.log'
$Stat3 = $Drv + ':\' + $FilesTemp + '\' + $Version + $TimeNow + "_" + $T1 + $Drv + $Outs + $T1 +'_3.log'
$Logs += $Stat1
Write-Host "testing mode " $T1 $Wr $Bl $Outs 'time' $Time # "GR" $OutFilesGr
# &$Sp $T1 $Wr $Bl -W10 $Outs $Time -Suw -D -L $Size $Out021 $Out022 > $Stat1
&$Sp $T1 $Wr $Bl -W10 $Outs $Time -Suw -D -L $Size $Out021 > $Stat1
}}}}}}
И часть 2
$FilesTempDir = "c:\Data4del\"
$StatFiles = "069"
$StatFilesList = Get-ChildItem -Path $FilesTempDir | Where-Object {$_.Name -like ($StatFiles + '*') | Sort-Object -Property CreationTime }
foreach ($MyFile in $StatFilesList){
$TempData1 = Get-Content $MyFile.FullName | Where-Object {$_ -like "Command Line*"}
$TempData1
$TempData2 = Get-Content $MyFile.FullName | Where-Object {$_ -like "total:*"}
$TempData2
}