


Немного истории
47 постов
47 постов
10 постов
180 постов

4 поста

С обратной стороны подложки находится множество электронных компонентов, стабилизирующих напряжения для правильной работы внутренних частей процессора. Они окружены металлическими контактами, отвечающими за подключение процессора в сокет материнской платы.
С верхней стороны чип покрывается дополнительным слоем кремния. Следом наносится припой или пластичный терм интерфейс, после которого на процессор устанавливается термо-распределительная металлическая крышка.

После того, как процессор принимает привычный для нас вид, он отправляется на последнее тестирование. По его окончании на крышку наносится название модели и номер партии. Затем процессор отправляют в упаковочный цех. Из него он попадает на склад производителя, а следом — и на полки магазинов.

Так что же такое "Центральный процессор"
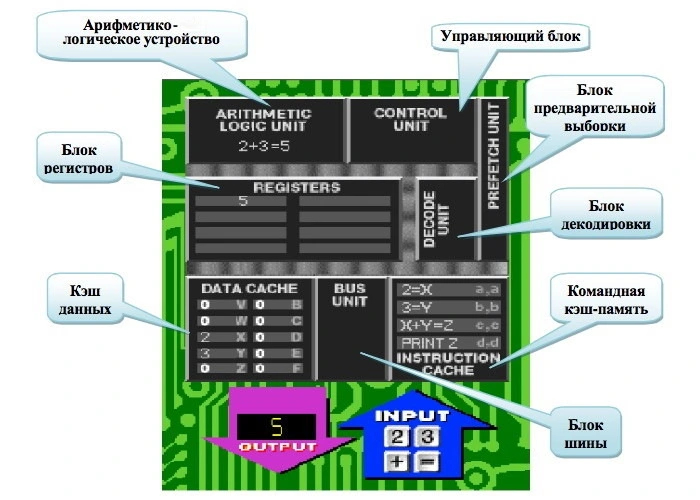
Центральный процессор — сложное электронное устройство. В его состав входят различные блоки вычислительных ядер, несколько уровней кэш-памяти, шины обмена данными, встроенная графика и прочие блоки. За счет чего же растет то самое IPC?
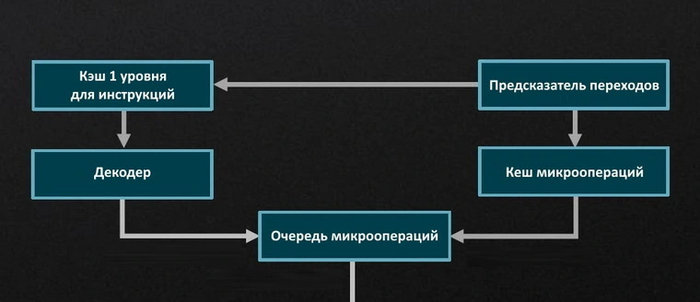
Инструкции, полученные процессором, поступают на исполнительный конвейер. От количества и скорости работы разнообразных исполнительных блоков, имеющихся в нем, зависит скорость исполнения инструкций. В каждом новом поколении количество таких блоков увеличивается, а также улучшается эффективность их работы. Сначала идут следующие блоки:
Предсказатели переходов (Branch Predictors). Блоки, прогнозирующие выполнение или невыполнение инструкций в программах на несколько шагов вперед.
Блоки выборки инструкций (Instruction Fetch Units, IFU). Блоки, занимающиеся выборкой инструкций для последующей передачи их декодерам.
Декодеры (Decoders). Преобразуют сложные команды x86 в простейшие микрооперации для исполнения.
Это общая часть конвейера. Затем он разделяется на две части, каждая из которых предназначена для работы с собственным типом вычислений: целочисленную (Integer) и с плавающей запятой (Floating-Point). У каждой части имеются следующие независимые блоки:
Блок переименования регистров (Register Rename). Исполняемые инструкции ссылаются на логические регистры. Этот блок переносит ссылки на физические регистры процессора.
Планировщики исполнения (Schedulers). Выстраивают поступающие инструкции в очередь с целью максимально эффективного исполнения.
Регистровый файл (Register File). Ячейки памяти, которые хранят коды команд в период их исполнения.
Далее целочисленная часть разделяется на несколько ячеек, которые называются исполнительными портами (Execution Ports). В каждом из них может быть один из следующих блоков:
Арифметико-логическое устройство (Arithmetic Logic Unit, ALU). Занимается целочисленными вычислениями.
Блок генерации адресов (Address Generation Unit, AGU). Вычисляет адреса, используемые ядром для доступа к памяти, а также занимается их загрузкой и выгрузкой.
Блок хранения адресов (Store Data). Упрощенный вид AGU, который занимается исключительно выгрузкой адресов в память.
Блок исполнения переходов (Branch Execution Unit, BRU). Выполняет переходы и вызовы процедур на основе решений исполняемой программы.
После исполнительных портов следует блок сохранения/загрузки (Load/Store), который отвечает за загрузку данных из памяти и сохранение данных в нее.
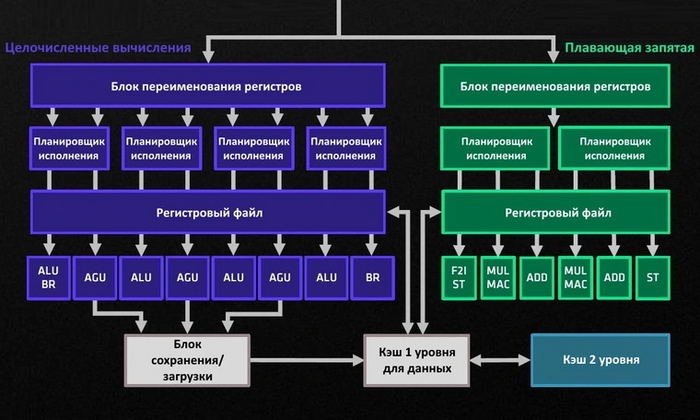
Часть вычислений с плавающей запятой называется FPU. Она работает с мультимедийными инструкциями семейств SSE, AVX, FMA и прочими. У этой части собственные порты, в которых другие блоки, отвечающие за математические операции: сложения (Add), умножения-сложения (Multiple-Add, MAD), умножения-накопления (Multiply-Accumulate, MAC), сдвига (Shift), смешивания (Shuffle).
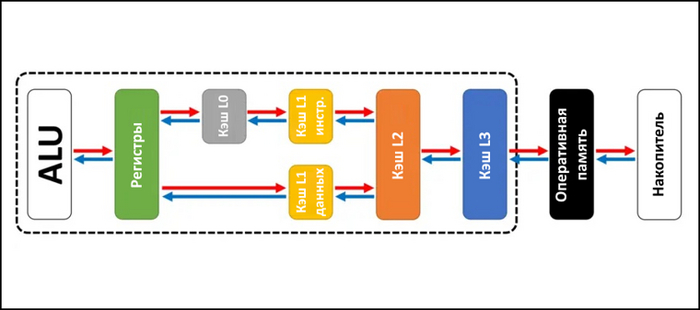
Помимо скорости работы вычислительных блоков, на производительность влияют скорость, объем и строение кэшей. В процессоре есть несколько различных кэшей, каждый из которых предназначен для ускорения работы на определенном отрезке процесса вычислений.
Кэш инструкций (L1 Instruction Cache). Кэш, куда попадают еще не декодированные x86-инструкции.
Кэш микроопераций (L0 Cache, Micro-Ops Cache). Кэш, предназначенный для хранения декодированных микроопераций.
Кэш первого уровня для данных (L1 Data Cache). Кэш малого объема, предназначенный для данных.
Кэш второго уровня (L2 Cache). Кэш среднего объема, следующий за L1. Работает медленнее кэша первого уровня.
Кеш третьего уровня (L3 Cache). Кеш большого объема, следующий за L2. Самый медленный из всех кэшей. В отличие от других кэшей, которые у каждого ядра свои, L3 - общий для всех ядер процессора.
Буферы и очереди для работы с инструкциями (Instruction Buffers and Queue) используются для ускорения работы с инструкциями. В их число входят буфер переупорядочивания, буфер загрузки, буфер выгрузки, очередь декодированных микроопераций и очередь распределения.
Буферы ассоциативной трансляции (Translation Lookaside Buffers, TLB). Небольшие кэши, расположенные после конвейера, а также между обычными кэшами разных уровней. Используются для ускорения трансляции виртуального адреса памяти в физический.
Оперативная память (Random Access Memory, RAM). Последний уровень динамической памяти. Хотя сама память находится за пределами процессора, ее контроллер, задающий тип, число каналов и тактовую частоту, находится именно в ЦП.
Помимо объема и их скорости, на производительность влияют и другие характеристики кэшей:
Организация. При инклюзивной организации кэша данные дублируются на различных уровнях. Это дает быстрый доступ к ним, но есть и минус — они занимают место на разных уровнях кэша. При эксклюзивной организации дублирований нет, и объем кэша используется более эффективно. Однако в случае, если нужных данных не оказалось в более быстром кэше, процессору придется тратить дополнительное время на извлечение их из более медленного уровня. Неинклюзивный кэш сочетает преимущества первых двух видов: он отслеживает данные, пытаясь спрогнозировать их необходимость на верхнем уровне кэша. При ее отсутствии алгоритмы вытесняют ненужные данные в нижний уровень кэша, экономя объем.
Сегментация. У современных процессоров кэш последнего уровня может быть как монолитным, так и состоять из нескольких сегментов.
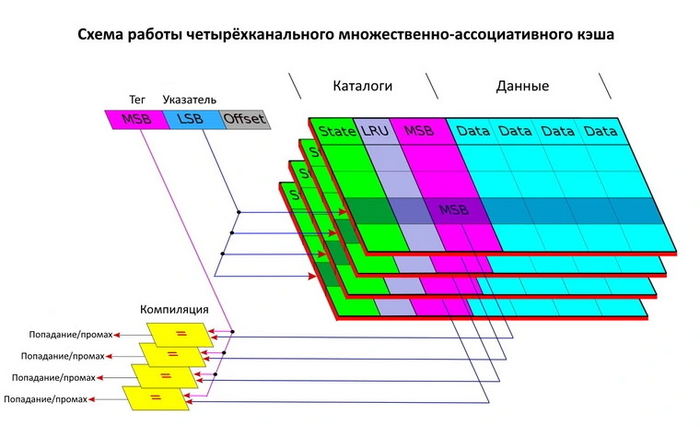
Ассоциативность. Для ускорения работы кэша доступ к нему осуществляется по нескольким каналам. Уровень ассоциативности — это количество используемых кэшем каналов. Чем их больше, тем эффективнее работа кэша: меньше промахов при поиске данных, больше попаданий. Но с ростом числа каналов усложняется и система доступа к кэшу. Несмотря на меньшие промахи, в результате обработки большого количества каналов производительность кэша может снижаться.
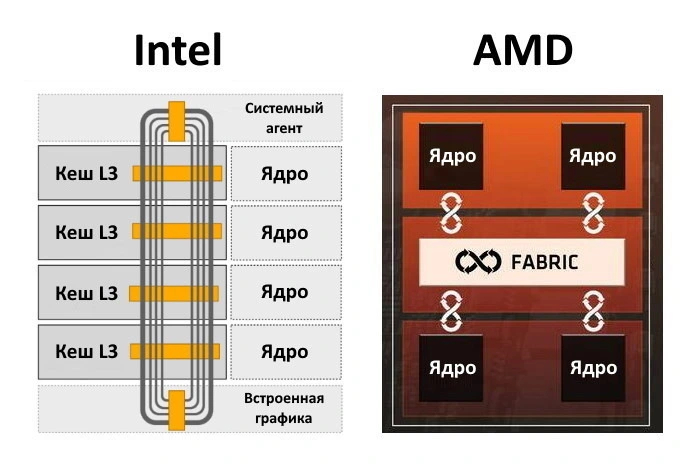
В современных многоядерных моделях важную роль играет также скорость передачи данных между внутренними компонентами процессора, в первую очередь — вычислительными ядрами. Каждая из компаний-производителей использует шину собственной разработки для соединения компонентов ЦП между собой:
Компоненты процессоров Intel соединены кольцевой шиной Ring Bus.
Компоненты процессоров AMD общаются посредством соединений шины Infinity Fabric.
На сегодняшний день процессорная архитектура, разработанная с нуля — очень редкое явление. Чаще всего новые процессорные архитектуры получаются с помощью доработки различных блоков уже существующих решений. В число таких доработок входят:
Улучшение предсказателей переходов. Доработка этих блоков помогает увеличить производительность за счет уменьшения количества промахов предсказания инструкций.
Увеличение количества декодеров. За счет этого процессор становится способен декодировать больше инструкций за такт. В теории, это должно прямо повлиять на производительность. Однако, для раскрытия потенциала большего количества декодеров необходимо одновременно «подтягивать» и другие части конвейера.
Улучшения планировщиков исполнения. Благодаря этому становится возможным более «плотно» загрузить работой исполнительные порты. Это помогает добиться их большей эффективности, повышая производительность.
Увеличение регистрового файла. Расширяет хранилище для поступающих команд. Обычно производится вместе с увеличением количества исполнительных портов – это делается для достижения их большей эффективности.
Увеличение количества исполнительных портов. Расширение конвейера с добавлением вычислительных блоков позволяет производить больше расчетов за такт и быстрее передавать их. Это прямо влияет на производительность, особенно при сложном коде.
Усовершенствования блока сохранения/загрузки. Позволяют совершать больше операций сохранения/загрузки за такт, тем самым увеличивая эффективность работы с памятью.
Улучшения блоков FPU. Увеличение количества и производительности блоков вычислений с плавающей запятой позволяет быстрее выполнять мультимедийные инструкции, а также внедрять поддержку их новых видов.
Вдобавок к улучшениям вычислительных блоков процессоры новых архитектур обычно получают и улучшения подсистемы кешей:
Увеличение размеров кэшей. Повышает количество хранящихся в них данных, вследствие чего уменьшается вероятность промаха.
Увеличение скорости кэшей. Более высокая пропускная способность кэша снижает время, необходимое для его чтения или записи.
Изменения в ассоциативности, организации или сегментации. Совокупность этих изменений обычно подбирается под прочие характеристики процессора, чтобы сделать работу кэша наиболее эффективной.
Увеличение буферов и очередей работы с инструкциями. За счет увеличения позволяют более эффективно работать вычислительным блокам процессора.
Увеличение буферов ассоциативной трансляции. Уменьшает вероятность промаха при поиске страницы памяти.
Увеличение скорости обмена по внутренним шинам. Скорость внутренней шины повышается раз в несколько поколений, чтобы успевать передавать данные с учетом роста производительности ядер и роста их количества.
Улучшения контроллера памяти. Более высокие тактовые частоты и новые типы памяти подбираются с учетом усовершенствований архитектуры, чтобы ОЗУ не стала узким местом в производительности системы.
Обратимся к примерам таких изменений. Для начала возьмем процессоры Intel. В 2021 году после шести лет «царствования» в десктопах архитектуры Skylake наконец-то вышли модели 11 поколения Core на новой архитектуре Sunny Cove.
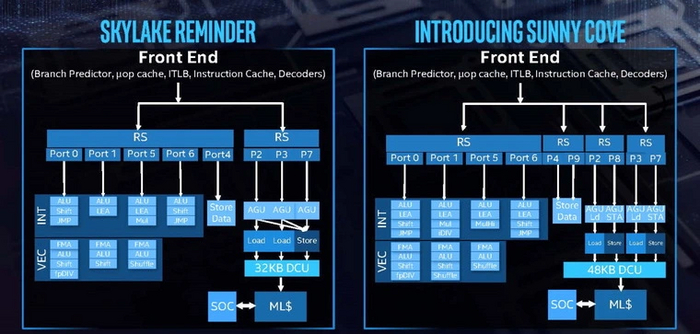
На ее основе построены десктопные процессоры Rocket Lake, которые быстрее предшественников на одной частоте примерно на 10–12%. Это стало возможным благодаря следующим улучшениям:
Пять инструкций за такт вместо четырех — заслуга расширенного декодера.
Десять исполнительных портов вместо восьми: плюс один AGU, и еще один порт для блока Store Data.
Усовершенствованный блок сохранения/загрузки, позволяющий производить одновременно две операции сохранения против одной у предшественника.
Увеличенные буферы и очереди для работы с инструкциями.
В полтора раза увеличенный кэш микроопераций и кеш L1. Последний, к тому же, был ускорен.
Кэш L2 был увеличен в два с половиной раза. Его инклюзивная организация сменилась неинклюзивной.
Производительные ядра современных процессоров Alder Lake и Raptor Lake основаны на следующей, самой современной на данный момент архитектуре Intel — Golden Cove.

По сравнению с предшественниками Rocket Lake они быстрее примерно на 15–20 %. Это достигается благодаря следующим усовершенствованиям:
В очередной раз расширенный декодер: шесть инструкций за такт против пяти
Двенадцать исполнительных портов вместо десяти: плюс один ALU и один AGU.
Увеличены буферы и очереди для работы с инструкциями.
Увеличены и ускорены кэши всех уровней.
Новый контроллер памяти, работающий с ОЗУ DDR5 наряду с DDR4.
Теперь обратим внимание на изменения в современных процессорах AMD. В конце 2020 года были представлены первые процессоры архитектуры Zen 3 — Ryzen 5000 серии.

Благодаря им впервые за много лет AMD смогла перегнать по однопоточной производительности конкурентные процессоры Intel. Рост производительности на одной частоте по сравнению с предшественниками Zen 2 составил около 20 %. Это стало возможным благодаря следующим улучшениям:
Предсказатель переходов получил улучшения для более эффективной работы.
Количество исполнительных портов было увеличено с семи до восьми. Новый порт содержит блок BRU. К тому же, теперь и один из ALU может работать в качестве BRU.
Количество планировщиков сокращено с семи до четырех. При этом каждый из переработанных планировщиков стал быстрее более, чем вдвое.
Усовершенствованный блок сохранения/загрузки позволяет производить на одно сохранение и одну загрузку больше.
Увеличены буферы и очереди для работы с инструкциями.
Усовершенствованный FPU расширился с четырех блоков до шести. Теперь у него два планировщика вместо одного.
Комплекс процессорных ядер CCX теперь содержит восемь ядер вместо четырех. Это уменьшает задержки при их общении. В связи с этим изменилась и сегментация кэша третьего уровня: теперь в каждом чипсете L3 — монолитный, объемом в 32МБ. Ранее использовались две секции по 16 МБ.
Последнее поколение процессоров AMD — серия Ryzen 7000. Они основаны на архитектуре Zen 4.
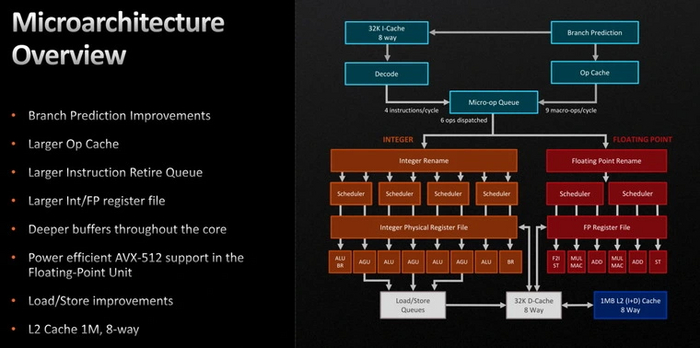
Новые процессоры быстрее предшественников примерно на 13 % на одной частоте. Архитектура Zen 4 получила следующие усовершенствования:
Предсказатель переходов в очередной раз усовершенствован.
Увеличен и ускорен кэш микроопераций.
Увеличены буферы и очереди для работы с инструкциями.
Кэш L2 вырос вдвое — с 0.5 до 1 МБ на ядро.
Увеличены размеры регистровых файлов.
Блок сохранения/загрузки теперь работает более эффективно.
Благодаря доработанному FPU добавлена поддержка инструкций AVX-512.
Новый контроллер памяти, который работает с ОЗУ DDR5 против DDR4 у предшественника.
Изменения в процессорных архитектурах разнятся из поколения в поколение. Это логично, ведь производители процессоров анализируют работу текущих поколений, и в первую очередь устраняют «узкие» места архитектур.

Рост производительности на такт (IPC) напрямую связан с блоками, в которые внесены изменения. Прирост производительности в разных видах задач может отличаться, в зависимости от внесенных в архитектуру изменений. Большинство программного обеспечения получает наибольший прирост от ускорения темпа целочисленных вычислений. Но есть и программы, которые больше чувствительны к скорости работы FPU или подсистемы кэшей.
IPC — главный показатель производительности современных ЦП, но далеко не единый. Стоит помнить, что прирост однопоточной производительности между разными поколениями процессоров дополнительно зависит от их тактовых частот, а многопоточной — еще и от количества ядер.
Для создания слоев маски используются:
Центрифуга. Перемешивает и подает на поверхность пластины фоторезист — чувствительный к свету материал. Затем производится нагрев пластины: лишний фоторезист испаряется, а оставшийся «прилипает» к поверхности пластины.

Литографический сканер. Подает ультрафиолетовый свет на пластину с помощью трафаретов соединений и системы линз. В засвеченных местах фоторезист закрепляется, в незасвеченных — нет.

Проявитель. Смывает незакрепленные области фоторезиста, а затем «запекает» закрепленные области с помощью нагрева пластины.

Обработчик поверхности. Производит шлифование пластины и ее очистку от пыли.
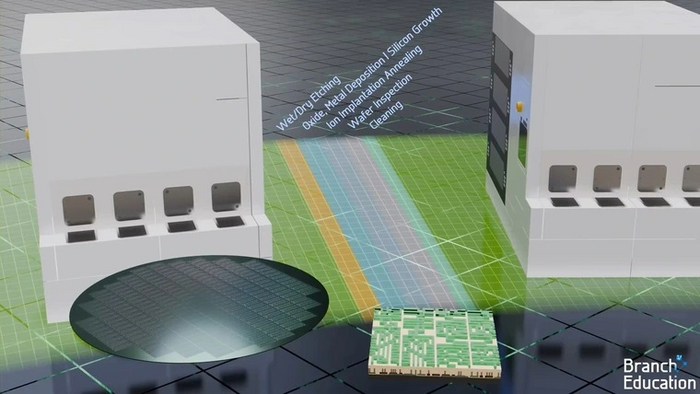
Очиститель. Устройство, в котором слой фоторезиста снимается с помощью растворителя.

Самый интересный элемент этой связки — литографический сканер. Внутри него находится источник ультрафиолетового света, который работает в связке с трафаретом соединений. Трафарет имеет размеры около 15×15 см. На одном трафарете могут находиться схемы сразу двух слоев чипа. На небольшие поверхности будущих чипов свет через трафарет попадает посредством сложной системы линз, которая уменьшает изображение в четыре раза.

После того, как поверхность одной процессорной заготовки будет засвечена, пластина сдвигается для обработки следующей. И так 230 раз для обработки всех заготовок.

После завершения формирования одного слоя, а также всех дальнейших шагов по его закреплению, обработке и проверке, процесс повторяется заново. Таким образом для создания процессора литографический сканер должен «напечатать» 80 слоев, используя для каждой пары свои уникальные трафареты.
С этой целью используются установки для осаждения материалов. После того, как маска готова, на нее распыляется жидкий материал — точно так же, как краска из баллончика.

Установок данного типа бывает несколько, и каждая чем-то отличается от другой. По используемым материалам их можно поделить на три категории:
Проводящие материалы (медь, тантал)
Изоляционные материалы (оксиды)
Кристаллический кремний
Для каждой из групп материалов используются собственные химические способы осаждения на пластину, но эффект всеми ими достигается схожий.

В центре установки для осаждения находится главная камера для пластин. К ее краям прикреплены дополнительные камеры, в каждой из которых происходит нанесение одной разновидности материала. Например, металлов — алюминия, меди, золота, вольфрама, никеля или тантала.

Противоположная категория операций, которую выполняют машины для удаления материалов. Различают две разновидности таких установок:
Установки травления. Воздействуют коррозионными химическими веществами или плазмой для удаления материалов с поверхности пластины. Обычно используются с маской, вытравляя углубления для их последующего заполнения другим материалом.
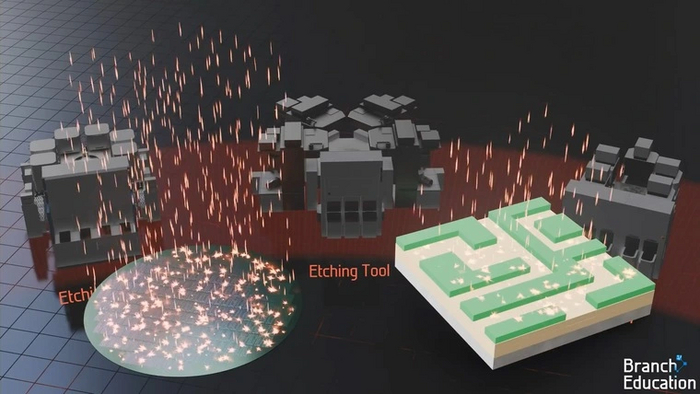
Установки химико-механической планаризации. Наносят на поверхность пластины специальную суспензию, затем шлифуя и полируя ее абразивными материалами до идеально ровной поверхности. Используются в конце формирования одного слоя, чтобы подготовить пластину к созданию следующего.

Ионные имплантаторы — установки, которые используют бомбардировку поверхность пластины люминофором, бором, мышьяком, сурьмой или другими элементами. Эта процедура необходима для создания P- и N-переходов процессорных транзисторов, поэтому применяется только на начальной стадии формирования чипов.

Бомбардировка осуществляется вместе с нанесенной маской, поэтому затрагивает только определенные места на пластине. По сравнению с методом осаждения этот способ добавляет гораздо меньшее количество материала. Все потому, что в первом случае материал распыляется потоком, а во втором происходит только точечный заброс атомов в кремниевую решетку.

Подобный процесс повреждает решетку. Поэтому следом производится нагрев пластины, чтобы восстановить ее. Для него используются отдельные установки отжига.
Установки-очистители используются для удаления загрязнений и посторонних частиц с пластины. Они промывают поверхность очищенной водой, а после этого сушат ее азотом или изопропиловым спиртом.

Такие операции проводятся часто, чтобы исключить любые случайные частицы, попавшие на пластину.
Метрологические инструменты — устройства для проверки транзисторов и металлических слоев на наличие дефектов. Они представляют собой мощные электронные микроскопы, которые делают снимки слоев и сравнивают их с эталонными, чтобы определить возможные дефекты или наличие посторонних частиц.
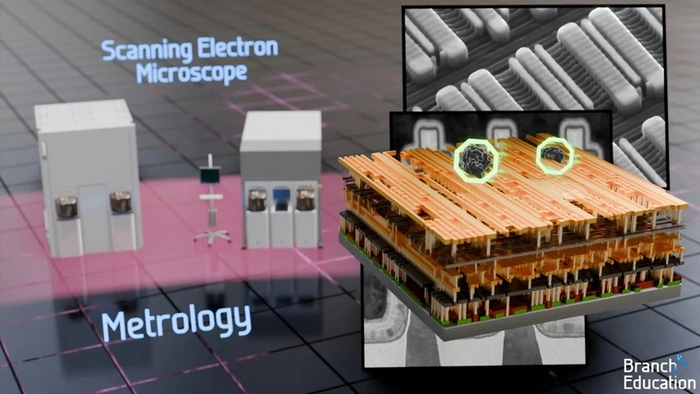
Изучив устройство полупроводникового производства и машин в нем, пройдемся по стадиям формирования чипов.
Первым делом на пластину наносится слой изолятора — диоксида кремния. Затем по поверхности распределяется фоторезист, и пластина подвергается термообработке для его усадки.

Пластина поступает в литографический сканер и засвечивается с помощью трафарета. В проявителе не засвеченные участки смываются, и производится запекание засвеченного фоторезиста.

Затем в дело вступает инструмент для травления, который «стачивает» изолятор. На первом слое это происходит до глубины, которая достаточна для формирования транзисторов. На последующих — до тех пор, пока не станут доступны металлические переходы от нижнего слоя.

Фоторезист смывается. На первом этапе производится бомбардировка атомами для создания транзисторов, после которой следует отжиг для восстановления кристаллической решетки. На более поздних этапах вместо этого производится распыление металла для создания слоя с соединениями.

После этого пластина шлифуется, чтобы обнажились образовавшиеся медные соединения. Один слой готов. Подобным образом создаются и все последующие слои. Между различными этапами пластины множество раз проверяются и очищаются, чтобы избежать проблем с будущими чипами.

После завершения формирования чипов на пластинах они отправляются в отдельное здание, где подвергаются тщательному тестированию. Несмотря на соблюдение всех условий производства, довольно часто отдельные части процессора могут иметь микродефекты.

Для каждого чипа создается карта дефектных областей, с учетом которой чип потом тестируется. Если область действительно работает нестабильно, но при этом не относится к критически важным частям кристалла — она отключается. Таким образом из одного кристалла получаются процессоры с разным количеством ядер — например, Core i9, Core i7 или Core i5. В части из них может быть отключена и встроенная графика.

После проверки пластины перевозятся в следующее здание, где разрезаются лазером на заготовки для будущих процессоров. После этого каждая заготовка помещается на интерпозер — соединительную пластину, покрытую шариками припоя.

С помощью шариков интерпозер соединяет чип и подложку процессора, передавая между ними электрические сигналы.

Ввиду ограничения фотоматериалов
ПРОДОЛЖЕНИЕ СЛЕДУЕТ...
Дорогие пользователи PIKABU!
С наступающим 2025 годом! Пусть этот год станет для вас настоящим источником вдохновения, радости и удивительных открытий. Оставьте в прошлом все переживания и преграды, а в новом году впустите только светлые мысли и добрые намерения.
Желаю, чтобы каждый ваш день был наполнен яркими моментами, а каждое начинание — успехом. Пусть сбудутся самые заветные мечты, а рядом будут верные друзья и любимые люди, готовые поддержать в любой ситуации.
Пусть 2025 год подарит вам возможность создавать и делиться незабываемыми историями. Желаю, чтобы ваше творчество цвело, чтобы смех звучал в ваших домах, а сердце наполнялось теплом и любовью.
С новым годом! Пусть он станет для всех нас временем новых свершений и ярких эмоций!
С наилучшими пожеланиями,
TechSavvyZone

«Мозгом» современной техники являются различные микрочипы. Самые сложные из них — это центральные и графические процессоры, а также системы на чипе для смартфонов. В их составе находятся миллиарды транзисторов. Как они производятся? И как такое огромное количество электронных компонентов и соединений между ними помещается на маленьком кристалле?
Сердце процессора
Принципы устройства микрочипов не менялись с самого их появления. Что микропроцессор Intel 4004, которому уже больше полувека, что современный Core i9 состоят из транзисторов — миниатюрных переключателей электрической цепи, которыми можно управлять с помощью подачи тока.
Главное отличие в том, что старые чипы производились по достаточно «толстым» техпроцессам и содержали небольшое количество транзисторов. В Intel 4004, который выпускался по техпроцессу 10 мкм (10000 нм), их было всего 2300. А в современном Core i9-13900K, производящемся по техпроцессу Intel 7 (10 нм), транзисторов в миллионы раз больше — целых 26 миллиардов.
Рассмотрим строение чипа на его примере. Данный процессор содержит восемь больших ядер и 16 малых, крупный кэш третьего уровня, контроллер памяти с поддержкой DDR4 и DDR5, встроенную графику UHD770 и прочие функциональные блоки. При этом размер кристалла такого чипа всего 10.7х24.2 мм.
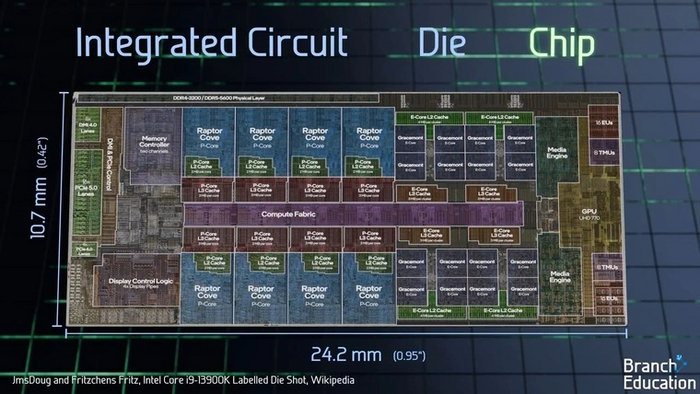
Если заглянуть в любое ядро, мы увидим, что оно состоит из различных частей — блоков выборки и декодеров, целочисленной части, блока вычислений с плавающей запятой, блоков загрузки/выгрузки, кэша первого и второго уровня. На каждую из них приходится несколько миллионов транзисторов.

Обратимся к еще более маленькой составляющей ЦП: блоку умножения в целочисленной части ядра. Он состоит из 44 тысяч транзисторов, что составляет всего 0,00017 % от их общего количества в чипе.

Увеличив масштаб, мы увидим несколько слоёв из множества металлических соединений, которые проводят сигналы от транзисторов.

Сами транзисторы находятся под слоями этих соединений.

Для наглядности соединения были представлены в виде тонких проволочек в пространстве. На самом деле они не парят в воздухе — между ними находятся слои изоляционного материала.

Это упрощенное представление, включающее слой транзисторов и пять слоев соединений. Всего в процессоре 17 слоев соединений, расположенных друг над другом. Внизу расположены локальные соединения между компонентами ядер, посередине — соединения вокруг ядер, на самом верху — глобальные соединения между разными компонентами ЦП. Чем ближе слой к верху, тем крупнее становятся соединяющие линии.

В современных процессорах используются трехмерные транзисторы FinFET. При технологии производства Intel 7 (10 нм), размер канала транзистора составляет 36 × 6 × 52 нм, а шаг между затворами транзисторов — 57 нм.
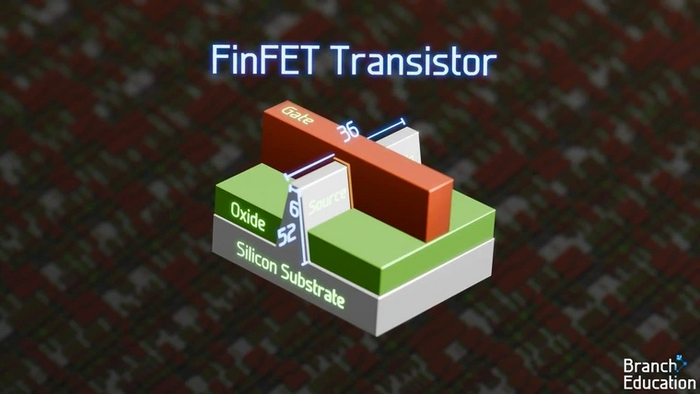
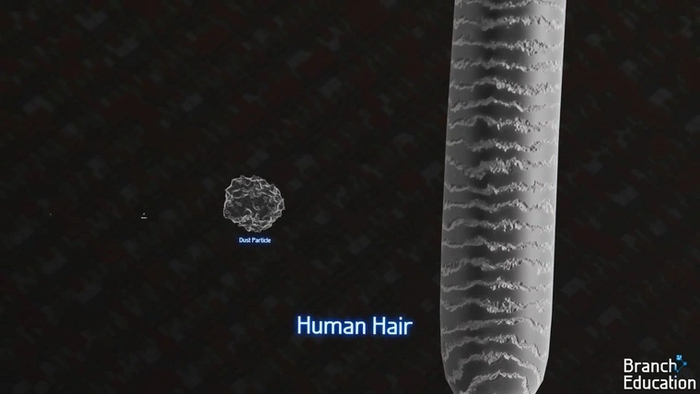
Чтобы представить себе размер такого транзистора, можно сравнить его с митохондрией, частицей домашней пыли или человеческим волосом. Транзистор — это первая белая точка слева, митохондрия — вторая.
Как же производят чипы из таких микроскопических составляющих? Чтобы узнать это, пройдем небольшую виртуальную экскурсию по производству.
Заготовки для будущих процессоров делают на заводе по производству кремниевых пластин. Основой для них служит кварцит — горная порода, из которой сложными методами очистки получается чистый кремний.

После очистки кремний расплавляется, и из него «выращивается» кристалл формы цилиндра.

С помощью лазера кристалл разрезается на множество пластин, а затем шлифуется до идеально ровной поверхности. Одна пластина имеет диаметр 30 см и толщину около 0,75 мм. У каждой из них сбоку делается небольшая выемка для указания положения кристаллической решетки, а сзади наносится серийный номер. Такие пластины очень хрупкие — стоит им упасть, и они разлетятся на множество мелких кусочков.

После производства пластин дальнейший процесс по «готовке» процессоров происходит на полупроводниковом производстве. Общая площадь помещений такого завода, отведенная непосредственно под производство чипов, составляет десятки тысяч квадратных метров.

Внутри производственной зоны поддерживается практически стерильная чистота, так как попадание пыли на будущие чипы непременно грозит их порчей. Здесь находятся сотни различных установок для работы с кремниевыми пластинами. Каждая из них имеет размер, схожий с фургоном или автобусом.

Кремниевые пластины последовательно перемещаются от установки к установке, поочередно проходя около тысячи производственных этапов. С момента поступления пластины на производства до готовности процессоров проходит около трех месяцев.

Пластины перевозятся стопками по 25 штук в специальном герметичном контейнере (FOUP), которые передвигаются по производственному помещению благодаря подвесной транспортной системе. С нее контейнеры опускаются на загрузочную площадку принимающей установки.

Через переходное отверстие контейнера пластины забирают роботизированные манипуляторы. Они отправляют их в камеры обработки, где добавляются, обрабатываются или смываются различные материалы.

После этого пластины вновь возвращаются в контейнер и едут в нем на следующие этапы обработки в других установках.

Таким образом наносятся и обрабатываются 80 различных слоев. После окончания обработки из одной пластины могут получится 230 центральных процессора или 952 чипа оперативной памяти.

На одном заводе имеется несколько сотен установок каждого вида, которые производят одни и те же операции с пластинами. Таким образом обеспечивается массовое производство: за месяц один завод может обработать 50000 пластин или 11.5 млн процессорных чипов.
Классификация установок обработки
Установки для обработки пластин можно поделить на шесть категорий.
1. Нанесение слоев маски
2. Добавление материала
3. Удаление материала
4. Модификация материала
5. Очистка пластины
6. Проверка пластины
Как выглядят установки и как они распределяются на заводе, можно увидеть на иллюстрациях ниже.


Рассмотрим каждый вид установок подробнее.
Ввиду ограничения фотоматериалов
ПРОДОЛЖЕНИЕ СЛЕДУЕТ.....
Сложно в это поверить, но современный процессор является одним из самых сложных готовых продуктов на Земле – а ведь, казалось бы, чего сложного в этом куске железа?

Давайте рассмотрим весь процесс более подробно. Содержание кремния в земной коре составляет порядка 25-30% по массе, благодаря чему по распространённости этот элемент занимает второе место после кислорода. Песок, особенно кварцевый, имеет высокий процент содержания кремния в виде диоксида кремния (SiO2) и в начале производственного процесса является базовым компонентом для создания полупроводников.

Первоначально берется SiO2 в виде песка, который в дуговых печах (при температуре около 1800°C) восстанавливают коксом:
SiO2 + 2C = Si + 2CO
Такой кремний носит название «технический» и имеет чистоту 98-99.9%. Для производства процессоров требуется гораздо более чистое сырье, называемое «электронным кремнием» — в таком должно быть не более одного чужеродного атома на миллиард атомов кремния. Для очистки до такого уровня, кремний буквально «рождается заново». Путем хлорирования технического кремния получают тетрахлорид кремния (SiCl4), который в дальнейшем преобразуется в трихлорсилан (SiHCl3):
3SiCl4 + 2H2 + Si ↔ 4SiHCl3
Данные реакции с использованием рецикла образующихся побочных кремнийсодержащих веществ снижают себестоимость и устраняют экологические проблемы:
2SiHCl3 ↔ SiH2Cl2 + SiCl4
2SiH2Cl2 ↔ SiH3Cl + SiHCl3
2SiH3Cl ↔ SiH4 + SiH2Cl2
SiH4 ↔ Si + 2H2
Получившийся в результате водород можно много где использовать, но самое главное то, что был получен «электронный» кремний, чистый-пречистый (99,9999999%). Чуть позже в расплав такого кремния опускается затравка («точка роста»), которая постепенно вытягивается из тигля. В результате образуется так называемая «буля» — монокристалл высотой со взрослого человека. Вес соответствующий — на производстве такая заготовка весит порядка 100 кг.

Слиток шкурят «нулёвкой» :) и режут алмазной пилой. На выходе – пластины (кодовое название «вафля») толщиной около 1 мм и диаметром 300 мм (~12 дюймов; именно такие используются для техпроцесса в 32нм с технологией HKMG, High-K/Metal Gate). Когда-то давно Intel использовала диски диаметром 50мм (2"), а в ближайшем будущем уже планируется переход на пластины с диаметром в 450мм – это оправдано как минимум с точки зрения снижения затрат на производство чипов. К слову об экономии — все эти кристаллы выращиваются вне Intel; для процессорного производства они закупаются в другом месте.
Каждую пластину полируют, делают идеально ровной, доводя ее поверхность до зеркального блеска.
ПРОДОЛЖЕНИЕ СЛЕДУЕТ...
Хронология увеличения транзисторов в процессоре. Микроэлектронные кремниевые компьютерные «чипы» выросли в возможностях от одного транзистора в 1950-х годах до миллиардов транзисторов на чип в современных микропроцессорах и запоминающих устройствах. От первого задокументированного полупроводникового эффекта в 1833 году до перехода от транзисторов к интегральным схемам в 1960-х и 70-х годах.

Период 1950-2020 гг.

Схема устройства Bell Labs DSP-1, 1979 г.
Архитектура однокристального цифрового сигнального процессора DSP-1 компании Bell Labs оптимизирована для электронных коммутационных систем. Цифровая обработка сигналов (DSP) использует математические методы для анализа аналоговых сигналов от естественных и электронных источников, чтобы отделить информацию от фонового шума.

Реклама высокоскоростных множителей-аккумуляторов компании TRW 1979 года
После преобразования в цифровую форму алгоритмы, такие как быстрое преобразование Фурье, фильтруют и восстанавливают данные, готовые к преобразованию обратно в пригодный для использования аналоговый сигнал. Возможности DSP были реализованы в каждом поколении технологий от электронных ламп до ИС в аудио, коммуникациях, изображениях, радарах, гидролокаторах и системах распознавания голоса.
Умножители 2 x 4 от Fairchild (9334) и AMD (2505) в 1970 году были одними из первых стандартных продуктов IC для ускорения алгоритмов обработки сигналов с большим количеством математических вычислений. Продукты TRW LSI использовали тройной диффузный биполярный процесс для создания более сложных функций, таких как умножитель 16x16 (MPY 16), используемый вместе с процессором AMD 2901 bit-slice для видео и оборонных приложений в конце 1970-х годов. Периферийные микросхемы MOS для обеспечения обработки сигналов с использованием универсальных MPU включали AMI S2811 (1978) для Motorola 6800 и 2920 от Intel (1979), которые объединяли программируемую цифровую обработку и схемы преобразования данных (1968 Milestone) .

Статья в журнале Electronic Design о ЦСП
Однокристальные DSP-процессоры по сути являются микропроцессорами с дополнительными сложными математическими возможностями. Однокристальный DSP-1 от Bell Labs, ключевой компонент цифрового коммутатора ESS от AT&T, появился в мае 1979 года. Фиксированная точка µPD7720 от NEC, представленная в 1980 году для приложений голосового диапазона, была одним из самых коммерчески успешных ранних DSP. Семейство 16-битных программируемых DSP-устройств TMS 320 от TI с 1983 года нашло широкое применение в потребительских товарах от сотовых телефонов до игрушек. Последующие поколения более высокоинтегрированных DSP от TI, а также Analog Devices, Motorola и других обеспечивают работу современных мобильных телефонов, дисководов и HDTV-продуктов.

Х. Т. Чуа и Джон Биркнер в середине 1980-х годов
Джон Биркнер и Х. Т. Чуа из Monolithic Memories разрабатывают простые в использовании программируемые матричные логические устройства (PAL) и инструменты для быстрого прототипирования пользовательских логических функций. Креативные проектировщики логики поняли, что небольшие, быстрые PROM (1971 Milestone) также могут быть сконфигурированы для выполнения простых логических функций. Поставщики полупроводников начали разрабатывать устройства, специально предназначенные для логических приложений.

Фотография кристалла MMI PAL16R8
В июне 1975 года Intersil представила IM5200 FPLA (Field Programmable Logic Array). Разработанное Биллом Сиверсом с использованием процесса компании Avalanche Induced Migration PROM, устройство рекламировалось как «первая PLA, которую можно программировать электрически в полевых условиях». В том же году Рон Клайн адаптировал технологию Signetics PROM для создания 82S100. В обоих случаях требуемая функция, выраженная в виде набора булевых логических уравнений, вводилась в блок программирования предохранителей, который мгновенно генерировал пользовательскую ИС на рабочем столе проектировщика.

Обложка первого Справочника по применению PAL (1978)
Джон Биркнер и Х. Т. Чуа из Monolithic Memories работали с Энди Чаном, чтобы представить более рационализированную архитектуру, которую они назвали Programmable Array Logic (PAL) в 1978 году, которая поменяла часть логической гибкости архитектуры PLA, используемой Intersil и Signetics, на более высокую скорость и более низкую стоимость. Программный инструмент проектирования PALASM (PAL Assembler) также сделал устройства простыми в использовании. Лицензионные соглашения с AMD, National и TI установили 20-контактные биполярные устройства (16L8, 16R8 и т. д.) в качестве стандартных продуктов отрасли. Они представлены в книге Трейси Киддер «Душа новой машины» (1981), технологическом бестселлере той эпохи. Более универсальная архитектура от AMD (22V10), технология КМОП для снижения энергопотребления от Cypress и Lattice и повторно используемые устройства на базе КМОП-СППЗУ, поддерживаемые совместимыми с ПК инструментами проектирования ввода схем от Altera (1983), расширили спектр их применения.

Книга Трейси Киддер, удостоенная Пулитцеровской премии
Xilinx (1984), Actel (1985) и QuickLogic (1988) представили архитектуры Field Programmable Gate Array (FPGA) для обслуживания приложений. Разработчики систем выбрали одно из этих конфигурируемых пользователем решений, известных под общим названием PLD (Programmable Logic Devices), вместо подходов ASIC (1967 Milestone) в качестве предпочтительного подхода к пользовательской цифровой логике для всех приложений, кроме самых дешевых или самых производительных.
