Карьера в IT. Системный аналитик, часть 8.1. Пример ТЗ для описания API
Всем привет.
UPD. Опять получился длиннопост с большим количеством текста в формате моих пояснений - простите, но не представляю как по-другому можно что-то объяснить, вроде стараюсь не графоманить.
В этом посте, наконец, приведу один из примеров того, как может быть написано техническое задание (кто-то может придраться, что это не ТЗ, а какой-то другой вид документа - да, возможно, но как-то сформировалась привычка для упрощения, что ТЗ - это любой документ, в котором описывается техническая постановка задачи, которую разработчик должен реализовать), в котором описываются требования к методу получения информации по конкретному объекту.
Шаблонов, на самом деле много и от команды к команде отличаются. Где-то СА просто пишут, что "метод должен получать объект User из базы Users и дальше отдавать его вызывающей стороне" - и это вся постановка. В каких-то командах упарываются и пишут ТЗ на микросервис целиком, в связке статьи в git в формате asciidoc + swagger (yes, I like it и отдельно про это тоже расскажу).
Но в большинстве случаев принято что-то среднее между этими крайностями - системному аналитику важно описать следующее:
То, какие данные метод получит на вход и правила валидации для них;
То, что метод должен сделать с этими данными, т.е. какую бизнес-логику выполнить;
То, что метод должен вернуть в ответ вызывающей стороне.
Допустим, нам нужно описать какой-нибудь метод, который получает любую бизнес-сущность по ее идентификатору.
Один из шаблонов, позволяющий это описать выглядит так (к сожалению, приходится скриншотом, потому что пикабу не умеет в таблицы (или я не умею в таблицы на пикабу)):
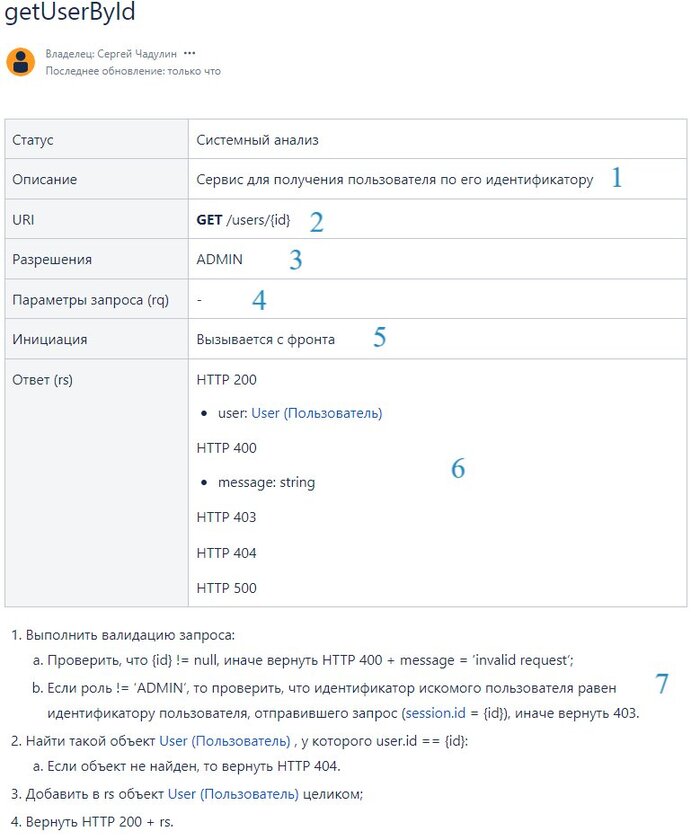
Если кто хочет посмотреть "вживую" или попользовать шаблон - вот ссылка на страницу моего конфлю (вроде должна работать).
Теперь по шагам:
Описание метода. Что он делает, для чего предназначен. Можно описать что-то конкретное, если сервис работает как-то специфично, такую краткую выжимку, что сторонним людям не приходилось анализировать его целиком;
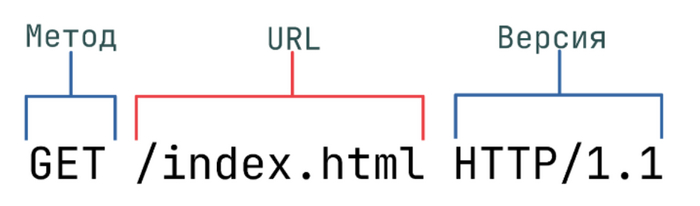
URI или URL метода. Состоит из одного из типовых глаголов плюс сам путь, по которому данный метод будет доступен. Про всякие best practices нейминга расскажу отдельно, в комментариях под предыдущим постом спрашивали;
Разрешения или Permissions. Если у вас есть ролевая модель и вам нужно разграничить доступ к каким-либо ресурсам среди пользователей с разными ролями - то вступает в дело данная строка таблицы. В ней нужно перечислить те роли, у которых есть доступ до данного метода;
Параметры запроса, который должны (или могут) быть переданы на вход данного метода. Т.к. у нас очень простой метод, то у нас их нет. Единственный атрибут в виде идентификатора пользователя ( {id} ) передается напрямую в ссылке. Т.е. пример запроса будет просто выглядеть вот так: GET /users/22 - дай мне пользователя с идентификатором 22.
Пункт больше для удобства, в случае, если у вас большая система и много взаимодействующих компонентов. Описываете, кто будет дергать ваши метод. Как минимум это нужно для того, чтобы потом, когда вы будете дорабатывать их - было понятно влияние. В данном случае, если вдруг метод поменяется мажорным образом, добавится какой-нибудь новый обязательный параметр - вы не забудете доработать еще и фронт.
Параметры ответа. Все варианты того, что ваш метод вернет вызывающей стороне после выполнения своей внутренней логики. Перечисляем как успешные коды ответа и всё их содержимое, так и ошибочные.
Непосредственно описание бизнес-логики метода. Т.е. что метод должен сделать с атрибутами, переданными на вход, и что должен вернуть.
Теперь немного про описание самой логики работы любого сервиса. Кому-то может показаться это сложным, но на самом деле все немного проще. Вам просто логически нужно представить у себя в голове, что должен вообще в принципе сделать ваш метод и попытаться придумать - как он должен это сделать.
На этом примере - у вас стоит бизнесовая задача (например): есть админка со списком пользователей, администратор нажимает на какую-то конкретную карточку пользователя, с целью просмотреть всю информацию по нему - в этот момент, как раз фронт откроет отдельную экранную форму и вызывает наш метод, передавая туда идентификатор искомого пользователя (который он ранее получил из другого метода, который получает массив пользователей, что-то вроде GET /users), чтобы получить всю нужную информацию для отображения.
Далее представляем что наш метод должен сделать, чтобы вернуть информацию по этому пользователю. Самое логичное - надо сначала найти его. Для этого нужно залезть в таблицу с пользователями и найти такого пользователя, у которого идентификатор будет совпадать с тем, что нам передали в запросе. Нашли - круто, не усложняем и возвращаем успешный успех фронт с передачей в теле ответа всей необходимой информации.
А что делать если не нашли? Вообще, технически такого быть не должно, потому что это значит, что у фронта устаревшая или недостоверная информация и нужно с этим разбираться - откуда он взял идентификатор, которого не существует? Но представим, что после того как админ открыл страницу со списком пользователей и до того, как перешел в карточку конкретного - другой админ удалил ее. В этом случае надо вернуть ошибку, что такой объект не найден.
Ну и всегда (по моему мнению), во всех методах нам нужно валидировать входящий запрос до того, как начать основную бизнес логику. Потому что зачем нам это делать и тратить драгоценное время и ресурсы, если мы заранее знаем, что запрос не валиден? Т.е. как минимум нам нужно проверить rq на соответствие контракту, что все обязательные атрибуты пришли и пришли в корректном формате. Как максимум выполнить еще всякие кастомные валидации, по типу тех же проверок на роли.
Также заранее поясняю, что в ответе ссылка на объект User (пользователь) ведет на описание атрибутивного состава объекта (в моем примере в конфлю нет, потому что я этого не сделал, но на боевых задачах - да), поэтому не нужно расписывать и дублировать этот объект еще и тут. Однако, если вам нужно передать не весь объект, а только его часть, например, не возвращать на фронт какие-то пароли пользователей или другие конфиденциальные данные, чтобы их не "схачили" - то нужно отдельно это указывать.
И еще поясню немного про пункт 1.b - особенно внимательные наверняка про него что-нибудь скажут. Пока писал, подумал, что можно использовать этот метод не только для админа, но и переиспользовать его на случай, когда обычный пользователь хочет получить информацию по себе же, например, когда открывает свой профиль. Вместо того, чтобы делать отдельный метод - просто разграничиваем права. Если он захочет запросить информацию о ком-то другом (если фронт подведет), то ему вернется болт.
P.S.: По традиции - буду признателен за вопросы про карьеру\профессию\чему угодно связанному со сферой IT - постараюсь ответить на всё.
P.P.S.: Также веду телеграмм-канал, в котором делюсь разным про профессию и про свой путь в ней. Есть и хардовая информация (асинхронные, синхронные интеграции, примеры ТЗ\шаблонов написания микросервисов), так и более софтовая - см. закрепленный дайджест.