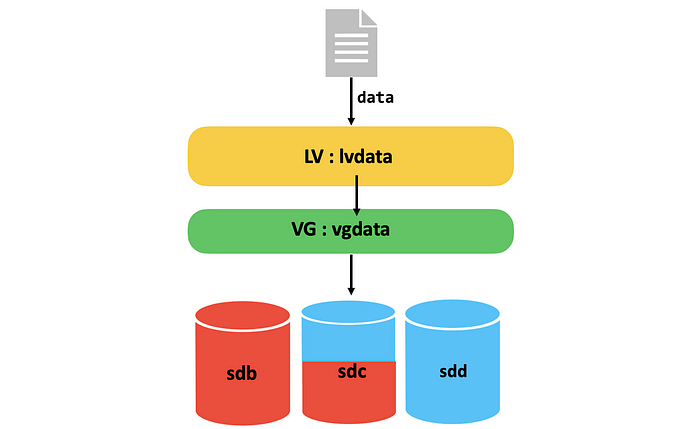
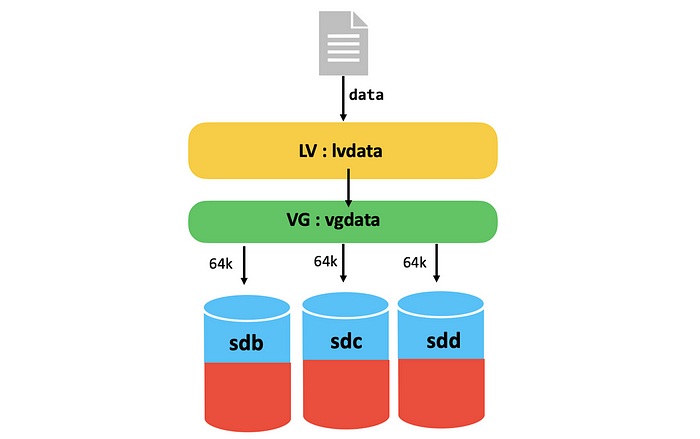
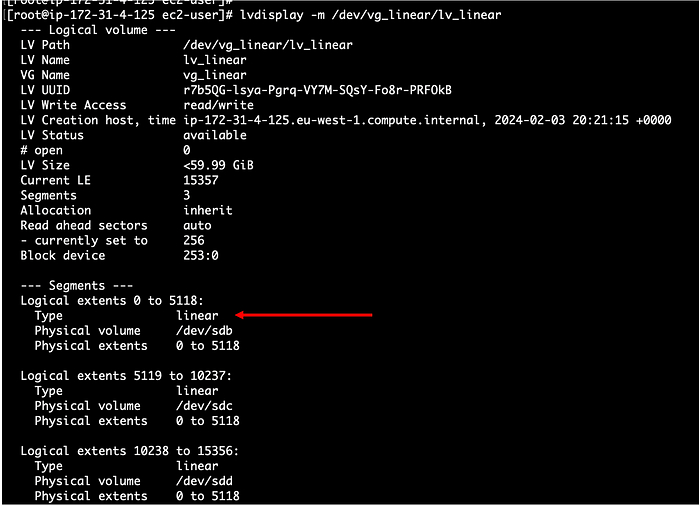
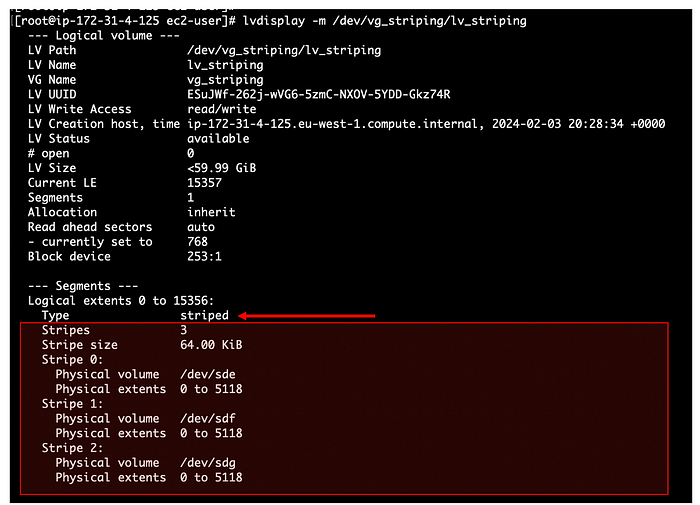
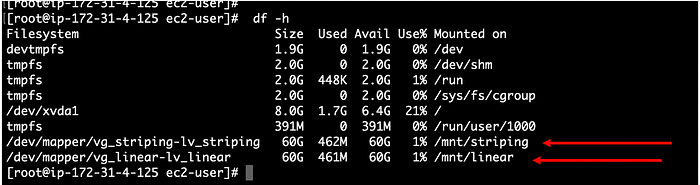
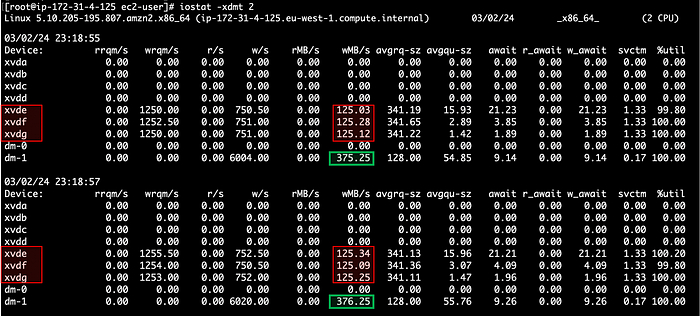
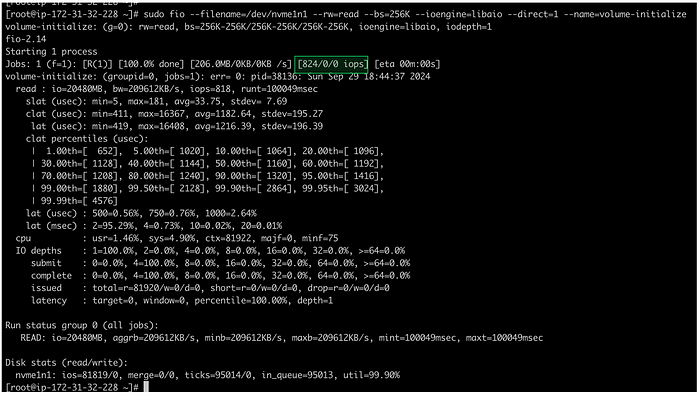
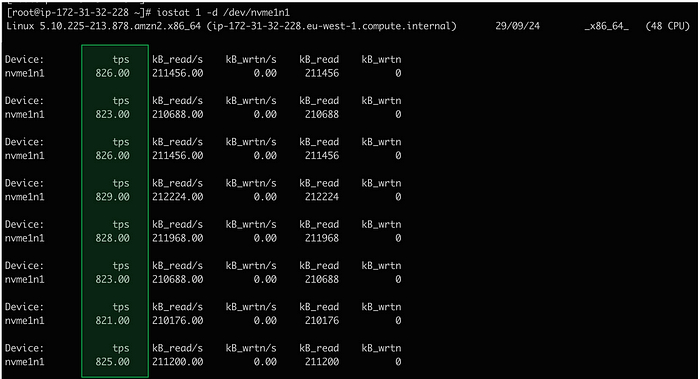
Кадры: новое поколение слушает Emancipation proclamation. И это прекрасно
Для ЛЛ: Наша молодёжь любит роскошь, она дурно воспитана, она насмехается над начальством и нисколько не уважает стариков. Наши нынешние дети стали тиранами; они не встают, когда в комнату входит пожилой человек, перечат своим родителям. Попросту говоря, они очень плохие.
Проблема российского ИТ , да и не российского тоже, да и не ИТ, просто это в России лучше видно и громче кричат - пропал рынок сбыта, и пропали дешёвые квалифицированные люди. Совсем пропали.
Ряд не-ИТ проектов в РФ опирался на то, что есть дешёвая рабочая сила из N-стана, и есть дешёвые местные проектировщики, бригадиры итд. И они кончились. Совсем.
То есть, 35 лет, с 1990 (если не с 1985) работал естественный отбор.
Работал он очень просто.
1990-2000.
Единственным рабочим способом выживания стало «крутиться». На немногие оставшиеся работать предприятия выстроились очереди, народ массово поехал из умирающих колхозов – в районные центры, из районных – в областные, из областных – в миллионники, из миллионников – в Москву.
Началась сепарация.
На тех, кто готов поднять формальные, неформальные, любые связи (включая межполовые), и уехать туда, где есть работа и перспектива.
И тех, кто не готов. Причины «не готовности» были разные, у кого-то в жизни и так все было неплохо – папа и мама при бизнесе, можно не напрягаться, как-то работать. У кого-то не было яростного желания вырваться любой ценой, хватало на еду, и раз в год съездить в Турцию, и нормально.
Сепарация привела к интересному результату. Из регионов вымыло не столько, и не только квалифицированную рабочую силу, но скорее:
мотивированную рабочую силу, и
мотивирующую рабочую силу.
То есть, в регионах остались не единицы квалифицированных людей, а десятки и сотни, но мотивация «затаскивать» и мотивация «затаскиваться» постепенно заканчивалась.
Люди, умеющие считать, четко понимали, что:
Кризис по образцу 1998, и 2008 года может повториться. В регионах в 2008 году масса людей просто вылетели с работ, в том числе в тепленьком ИТ. В Москве много вылетели, зарплаты просели, кто-то полгода проедал заначку. Но в Москве эта заначка была. В регионах, зачастую, нет.
После 2008, посидев с полгода на картошке с огорода и 6 соток, многие задумались про деньги.
В регионе на линейной позиции в ИТ ты мог (на 2010 год, условно) зарабатывать 15-25 тысяч. При курсе примерно 30, это 500-750$. Кстати, это 50-75 тысяч по текущему курсу.
После всех затрат у тебя оставалось 2-5 тысяч. Квартплата, транспорт, исключительно платная медицина, итд.
При перекате в Москву ты сразу мог уходить на 45-60, на 1500-2000 $. Кстати, это 150-200 к по текущему курсу, то есть не изменилось ничего.
Но, в Москве после вычета аренды (15-20), транспорта (причем, иногда в Моске уже тогда оплачивали проездной) и минимальных расходов (те же 10 к, 300$), у работника оставалось 45-15-10 = 20к. А не 2-5.
Стоит ли говорить, что приток в Москву не останавливался никогда?
Сейчас с этим притоком есть проблема, точнее с его качеством. Причем, проблема многогранная. Или, даже и не проблема.
Проблема первая, квалификация.
Сколько раз сказано, что просмотр видео «берем сперва укропу, ведро воды» - не учит готовить плов.
Сколько раз сказано, что просмотр видео «дети, вот это докер, докер это дети» - не учит понимать, что это, зачем оно, и куда оно. Ну вот докер, да.
Коллеги недавно плакали, громкими слезами, люди пишут в резюме «ставил докер». Если кто не в курсе, то процесс крайне увлекательный и сложный, целых 2 (две) строчки:
sudo apt-get install docker-ce
sudo docker run hello-world
Примечание. В Европе тоже любят писать Python, или Zscaler. Уровень знания - картинку с ним видели, в интерфейс IDE заходили, создать словарь, не говоря уже о загрузке словаря из файла, уже не могут. Fizz buzz не сделают.
Ничего удивительного в этом нет, люди где-то, в 2025 году, под 2019 AD - находят PDC и BDC. Не FSMO, так и пишут – PDC.
То есть, определенная часть поколения после 2000 года рождения, начисто потеряла умение читать, и понимать текст. И до этого у многих были проблемы с пониманием написанного, но, когда человека с 5-10 лет окружает, в основном, видео – он не то что потеряет, он не приобретет умение конспектировать и перерабатывать видео в текст, а текст забивать в МНУ (Межушный нервный узел). На это еще Фейнман жаловался, но соотношение стало хуже, на мой взгляд.
Намазываем на это отсутствие квалифицированных преподавателей (см. вымывание кадров), отсутствие корректной русскоязычной литературы, цыганские курсы, общие верования – и получаем, что получаем.
Изменилось само соотношение. Люди то есть.
Вовсе не проблема, а даже и наоборот – смена мотивации и поведения, то есть пункт второй.
Поколениям «до 2000 года» - деление, конечно, условное, точнее «поколениям до, примерно, 1980-1985 года рождения» много лет вбивали, что надо «понять, осознать, и покаяться». То есть, если начальник ругается, то нужно стоять и обтекать, вне зависимости от того, прав начальник, не прав. И всегда надо надеяться на светлое будущее. Не подняли зарплату хотя бы по инфляции – ну ничего, потерпим.
Али не выйдем на недоплачиваемые смены? За гроши совестью мужицкой приторговали? Да нет, я по глазам вашим мужицким вижу, что тут зарплатных нет.
До какого-то момента это работало, что в СССР, что в мире. Грамоты, медальки, значки, доска почета – это все работало и работает, но есть нюанс – работает только после закрытия первичных потребностей. В современном мире это своя квартира, своя машина. И только так. Своя квартира пояснений не требует, а своя машина, это не только вывоз тещи на дачу для похорон картошки, это еще и легко реализуемый актив, и в разы лучшая мобильность. Особенно в регионах. Даже в Москве до, примерно, 2010 года. А может и потом.
Сейчас перестало, или стало работать хуже. Genetation Next даже не будет тебе цитировать продолжение поговорки «ты работай дурачок», оно просто уйдет, и от конфликта, из из организации. Рабочая сила стала мобильной, и это хорошо.
НО.
Из того что я слышу в разговорах с приезжающими из РФ, и с оставшимися в РФ бывшими коллегами (опять же, надо заметить, что почти та же ситуация есть и в Европе), что бизнес пока не готов отказаться от двоемыслия и речекряка (Duckspeakers)
Бизнес (говоря про ИТ) прекрасно видит, что нехватку квалифицированной дешёвой силы не закрыть деньгами.
Можно поставить в вакансии заветные 300кк, придут все те же, ничего не знающие, люди.
Можно делать модно, по заграничному, до последнего скрывать размер вилки. И потом плакать, что плак плак, как так, где же люди, почему они все хотят работать за деньги, нас на кратких курсах учили, что мотивация должна быть нематериальной, максимум грамотка. Почему с нас ржут, ведь мы заказали такие красивые блокнотики, а кандидаты при их виде начинают смеяться, ОБИДНО!
Отдельно надо отметить сложности с экономикой некоторых проектов. Проект закладывался, скажем, исходя из того, что 5 программистов по 500к каждому в ФЗП (фонд заработной платы, то есть то, с чего потом возьмут ЕСН, травматизм, потом еще раз НДФЛ, и еще раз возьмут НДС) наработают прибыли на 1.000к в месяц каждый, что окупит и офис, и менеджеров, и макбуки, и еще останется. При 650к проект уже начинает трещать по балансу, при 750к баланс не сходится совсем. И, даже если и сходится, то у любого проекта есть заложенная норма прибыли. Зачем вкладываться в проект с прибылью 10%, когда можно положить деньги в банк под 20%.
Добавляем то, что люди по 500к (до всех налогов) эту катку могут не затащить. То есть не смогут запустить проект. Физически не могут – для одних слишком сложно, другие не могут работать с менеджером, который орет «вы все тут бездари». Минус один программист на проекте означает минус два, потому что, даже если нового тут же найдут, его ж кому-то надо учить. Это базовейшая из баз, мифический человеко-месяц, но кто ж его читал-то?
Добавляем то, что психологически бизнес не готов публично признать, что дешёвые люди кончились.
И часть бизнеса не понимает, как так - техника же работает все быстрее (это правда, все эти авто-дополнения, анализаторы, LLM, co-pilot очень хороши), но почему и раньше на проект надо было 10 человек, и сейчас на проект надо 10 человек. Нет понимания, почему машзал на 1000 стоек в 2000 году сейчас поместится, пожалуй, в десяток. Почему раньше «огромный» проект занимал 100.000 строк и выполнялся за 5 минут, а сейчас надо 1.000.000 строк кода, и железо в 20 раз мощнее выполняет задачу хорошо если за 5, а скорее за 15 минут.
А вот потому. Потому что оптимизировать код дорого. Потому что железо имеет свои пределы, и плохо написанный код, пусть он 10 раз опенсорсный, все равно остается плохо написанным и медленным.
Отсюда растет нытье.
Нытье удобно - не мы такие, жизнь такая. Так и есть, экономика части проектов на том и строится, что любой труд стоит дёшево, с дорогим трудом проект не окупается.
Поэтому нытье будет продолжаться, ровно до того момента, когда проблему станет невозможно терпеть бизнесу.
Удивительно, но труд в РФ не дорожает, если рассматривать в долларе. Как стоил мидл 4000 - 6000$, так и стоит, как стоил сеньор 6000-12000 $, так и стоит. Но нет, мантра 'вы же покупаете в рублях, зачем вам доллары' прочно засела в некоторых головах. Но мидл и сеньор тем и отличаются, что в курсе , что даже в Турции, берут доллары. И что телефон покупается за доллары (или юани). И, слушая эти рассказы, плавно утекают.
Отдельно надо сказать, что в РФ с ростом зарплат в рублях пытаются бороться на самом высоком уровне, но не афишируя этот процесс.
Осенью 2024 менеджмент в РФ пел «сейчас будут сокращения», подразумевая «надо лучше работать, сократим самых отстающих в части ритуальной похвалы меня по утрам».
Сейчас, судя по некоторым крикам боли, оказывается, что сократили или тех, кто реально работал, или тех, кто работал исключительно в части софт-скиллов, то есть много говорил, но ничего не умел.
Новая песня на 2025 – тут у нас обстоятельства, надо потерпеть, повышение, обещанное еще осенью, сдвинуто на следующую осень.
Начинает работать следующий этап сепарации – те, кто готов терпеть, остаются сидеть (но их производительность труда начинает страдать), а те, особенно из Gen Next, кто в этим сказки не верит – берут и уходят. Иногда в никуда, иногда уходят проедать подушку, иногда уходят на мамкины борщи (ТМ), иногда уезжают.
И вот тут бизнес начинает орать – ЧТО Ж ВЫ ДЕЛАЕТЕ, МЫ ВОТ ТАКИМИ НЕ БЫЛИ.
Да были вы, были и остались.
PS.
Полная цитата
General: Now each battalion has a specific code-name and mission. Battalion 5, raise your hands!
General: You will be the all important first defense wave, which we will call "Operation Human Shield".
Chef: Hey, wait a minute...
General: Now keep in mind, 'Operation Human Shield' will suffer heavy losses. But don't lose your spirit men! Stay until the bitter end. Battalion 14?
General: Right, you are 'Operation Get Behind The Darkies'. You will follow Battalion 5 here and try not to get killed for God's Sake. Are there any questions men?
General: Yes Soldier?
Chef: Have you ever heard of the Emancipation Proclamation?
General: I don't listen to hip-hop!
South Park: Bigger, Longer & Uncut
Английский вариант
Русский вариант