Предисловие и предыстория
Рgpro_pwr — инструмент стратегического мониторинга нагрузки на базу данных, который помогает DBA выявлять самые ресурсоёмкие операции.
Однако, в ходе решения задач сопровождения СУБД PostgreSQL возникают не только стратегические , но и оперативные и тактические задачи для которых инструмент стратегического мониторинга довольно громоздкий , что не очень удобно для быстрого решения ряда задач.
Задачи решаемые на оперативном уровне:
В каком состоянии находится производительность СУБД в данный момент времени?
Какая тенденция развития производительности СУБД на текущий момент или в прошлом?
На сколько снизилась производительность СУБД по сравнению с выбранным промежутком из прошлого?
Задачи тактического уровня:
Какая База Данных оказывает наибольшее влияние на производительность кластера в целом?
Какой/какие SQL запросы оказывают наибольшее влияние на снижение производительности ?
Предпосылки создания инструмента pg_hazel.
Производительность СУБД - как рассчитать ?
В ходе предварительных исследований были проверены разные способы расчета метрики производительности СУБД .
Однако , методы описанные в статье , к сожалению имеют свои аномалии.
Теоретически, наиболее близким к физическому определению производительность системы будет объемная скорость информации переданной клиенту , или другими словами - объем строк переданных запросом. Но к сожалению, на текущий момент , получить такую информацию - нет технической возможности. Важно - количество строк в запросе это не объем. Длина строки внутри выборки может меняться в очень широких диапазонах.
Поэтому было принято решения - непосредственный расчет производительности СУБД как физической величины - отложить на будущее, до реализации механизма получения объема данных переданных запросом.
Для решения задач анализа производительности СУБД используются индикаторы производительности СУБД и комплексный анализ изменения значений метрик производительности СУБД.
Структура pg_hazel
Источником данных являются представления расширения pgpro_stats
G.3.4.1. Представление pgpro_stats_statements
Статистика, собираемая модулем, выдаётся через представление с именем pgpro_stats_statements. Это представление содержит отдельные строки для каждой комбинации идентификатора базы данных, идентификатора пользователя и идентификатора запроса
G.3.4.2. Представление pgpro_stats_totals
Агрегированная статистика, собранная модулем, выдаётся через представление pgpro_stats_totals. Это представление содержит отдельные строки для каждого отдельного объекта БД
Данные собираются ежеминутно и агрегируются на 3-х уровнях:
Уровень Кластера
Уровень Базы Данных
Уровень SQL запроса
Дополнительные данные pg_hazel
Как было указано ранее данные о среднем времени выполнения запроса собираемые в расширениях pg_stat_statements или pgpro_stats имеют очень серьезную проблему - среднее арифметическое не устойчиво к выбросам.
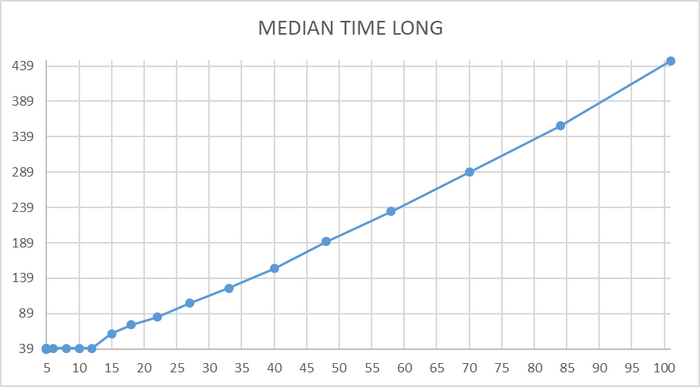
Поэтому для корректного расчета среднего времени выполнения запроса используется не среднее арифметическое , а медиана.
К сожалению, расчет проводимый на уровне БД требует специальной подготовки для тестового запроса и дополнительных ресурсов для хранения и статистического анализа данных. Поэтому применяется не для всех SQL запросов а только для конкретных тестовых запросов:
Benchmark кластера - медианное время выполнения тестового запроса для оценки производительности кластера в целом.
Тестовый запрос стресс-тестирования - медианное время выполнения запроса по выбранному сценарию в ходе проведения стресс-теста(нагрузочного тестирования)СУБД.
Данные собираемый pg_hazel
1. Уровень Кластера
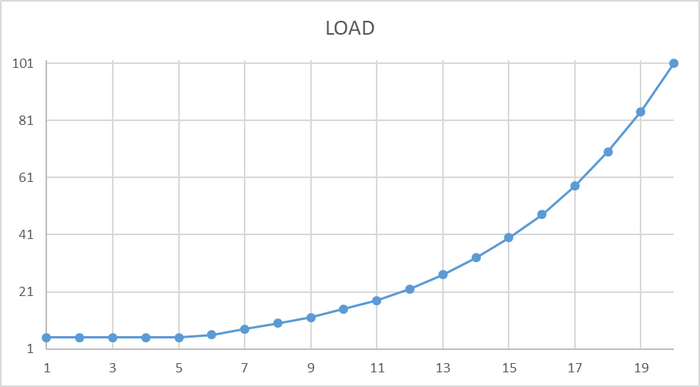
Операционная скорость - количество завершенных операций и сформированных строк за период .
Объемная скорость - объем обработанных блоков распределенной/локальной/временной области за период.
Активные сессии - количество активных сессий на точку времени.
Ожидания - количество событий ожидания СУБД за период.
BUFFERPIN - количество событий ожидания bufferpin за период.
EXTENSION - количество событий ожидания extension за период.
IO - количество событий ожидания io за период.
IPC - количество событий ожидания ipc за период.
LOCK - количество событий ожидания lock за период.
LWLOCK - количество событий ожидания lwlock за период.
WAITING_RATIO - относительная доля ожиданий СУБД в общем времени работы СУБД за период.
CORRELATION - коэффициент корреляции между количеством активных сессий и операционной скоростью.
BENCHMARK - медианное время выполнения тестового запроса.
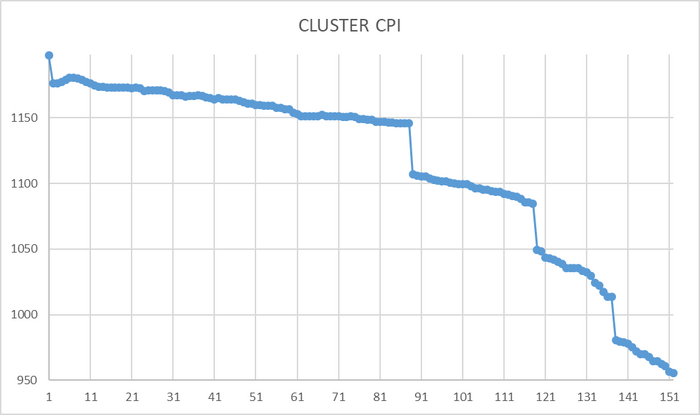
CPI - комплексный индикатор производительности = Операционная скорость / BENCHMARK .
2.Уровень Базы данных
Операционная скорость - количество завершенных операций и сформированных строк за период .
Объемная скорость - объем обработанных блоков распределенной/локальной/временной области за период.
Активные сессии - количество активных сессий на точку времени.
Ожидания - количество событий ожидания БД за период.
BUFFERPIN - количество событий ожидания bufferpin за период.
EXTENSION - количество событий ожидания extension за период.
IO - количество событий ожидания io за период.
IPC - количество событий ожидания ipc за период.
LOCK - количество событий ожидания lock за период.
LWLOCK - количество событий ожидания lwlock за период.
WAITING_RATIO - относительная доля ожиданий БД в общем времени работы БД .
3.Уровень SQL запроса
Операционная скорость - количество завершенных операций и сформированных строк за период .
Объемная скорость - объем обработанных блоков распределенной/локальной/временной области за за период .
Активные сессии - количество активных сессий на точку времени.
Ожидания - количество событий ожидания SQL запроса за период.
BUFFERPIN - количество событий ожидания bufferpin за период.
EXTENSION - количество событий ожидания extension за период.
IO - количество событий ожидания io за период.
IPC - количество событий ожидания ipc за период.
LOCK - количество событий ожидания lock за период.
LWLOCK - количество событий ожидания lwlock за период.
WAITING_RATIO - относительная доля ожиданий SQL запроса в общем времени работы SQL запроса .
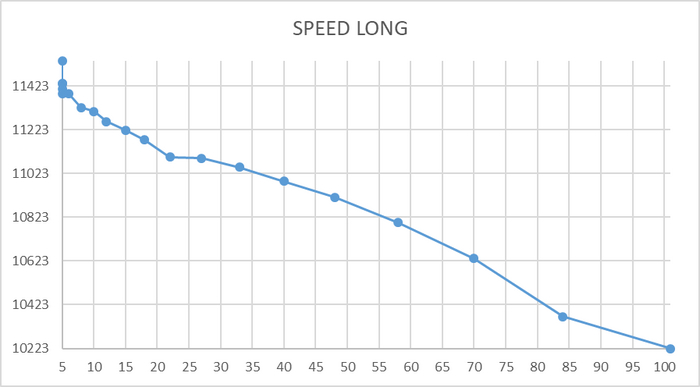
Для данных используется медианное сглаживание - короткий период 10 минут , долгий период 60 минут.
Примеры практического применения и анализа на основе собранных данных - в следующих статьях.