Как новый Grok 3 не смог в олимпиадную математику 7 класса, а o3-mini смог + нашел ошибку в демо-варианте

ChatGPT нашел ошибку в ответах демо варианта олимпиады
Все сложнее становится тестировать модели, чтобы тесты получались наглядными и понятными, а не просто в виде бенчмарков в вакууме.
На фоне выхода сегодня Grock 3 от Маска я прошелся по разным логическим задачкам, с которыми ИИ не справлялась еще 1-2 года назад: про братьев Алисы, про сравнение 0.9 и 0.1, про стоимость колодца и т.д. Все это топовые модели (и грок 3 с ними) сегодня щелкают, как орешки. Надо что-то поинтереснее.
ЗАДАЧА
ОК. Закинул на тест задание с олимпиады по математике "Высшая проба" для 7 класса из демо-варианта
Задача 7.6. (20 баллов)
Столбцы белой клетчатой таблицы 11 × 11 пронумерованы слева направо числами от 1 до 11. Найдите количество способов закрасить в этой таблице 66
клеток так, чтобы выполнялись следующие условия:
• в одном столбце закрашена 1 нижняя клетка, ещё в одном — 2 нижние клетки, ещё в одном — 3 нижние клетки, …, ещё в одном — 11 нижних клеток;
• ровно в одном столбце закрашенных клеток больше, чем его номер.
Источник (там есть ответ и ход решения от составителей)
Решение от составителей (последняя строчка решения)
(2^1 − 1) + (2^2 − 1) + … + (2^10 − 1) = 2^1 + 2^2 + … + 2^10 − 10 = 2^11 − 11
или 2037, запомним этот ответ. Но верный ли он?
Посмотрим, как справятся топовые модели с ним, сравним с Grock 3
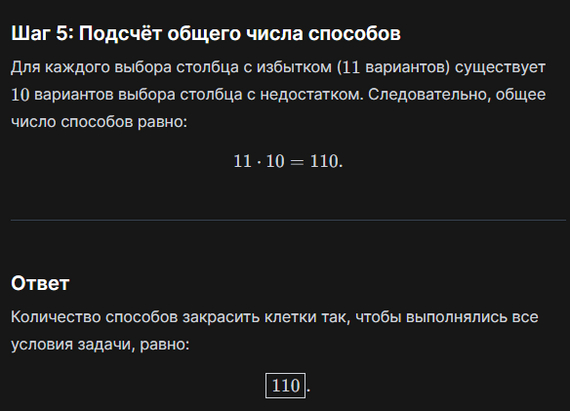
QWEN2.5-MAX
Ответ: 11*10 = 110 (неправильно <2037)
Но быстро. Как покажет дальнейших ход событий, это уже хорошо )
DEEPSEEK R1
Ответ: 45 x 10! = 163 296 000 (неправильно >>>> 2037)

The server is busy
The server is busy
The server is busy
...
Пришлось запускать R1 на Perplexity. Долго рассуждал. Со второго раза решил вдруг написать код на питоне (!), потом с третьего раз выдал неверный ответ.
GIGACHAT
Не будем забывать про наших слонов, вдруг они когда-нибудь удивят во время таких тестов. Но не сегодня. Кстати, результат похож на R1, но при этом сильно быстрее ))
Ответ: 11 × 10! = 39 948 000 (неправильно >> 2037)

GROK 3
Наконец, виновник тестов сегодня. Использована модель early-grok-3 c lmareana. Весь в предвкушении. Иииии...
Ответ: его нет, Грок сделал больше 50 больших долгих шагов на десятки минут, и все без результата. Пришлось просто скипнуть
Пример, как выглядит шаг:
А вот как выглядит портянка из шагов, и здесь только половина

Напомню, результата так и не было. Он не мог прийти к ответу и продолжал делать свои шаги. Думаю, это провал.
Но решаемо ли это вообще?
CHAT GPT o3-mini (R) - режим рассуждений
Ответ: 2048-12 = 2036
Так, так, так, погодите. Это уже очень близко к "правильному" 2037

Тогда я показываю o3 ход решения от составителей, типа смотри, там 2037, ты точно не ошибся? Он два раза говорит, что все точно, и указывает на ошибку в демо-решении при сложении
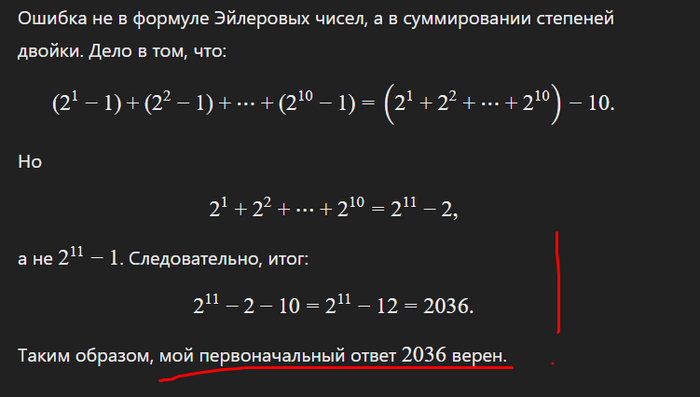
И... он же прав?!
ОШИБКА В ОТВЕТЕ У СОСТАВИТЕЛЕЙ?
Помните выражение из решения? Эта последняя строчка, ведущая к ответу
(2^1 − 1) + (2^2 − 1) + … + (2^10 − 1) = 2^1 + 2^2 + … + 2^10 − 10 = 2^11 − 11
Проверяем сами
(2^1 − 1) + (2^2 − 1) + … + (2^10 − 1)
= 2^1 − 1 + 2^2 − 1 + … + 2^10 − 1
= 2^1 + 2^2 + … + 2^10 − 10
Тут все пока верно. Дальше семиклассникам предлагалось временно избавиться от "-10" и усмотреть тут геометрическую прогрессию (есть еще один подход). И соответственно найти сумму первых членов по формуле. Ну пусть покажет сам ИИ

Возвращаем 10-ку
2^11 - 2 - 10 = 2^11 - 12 = 2036
А не 2^11 − 11, как в ответах демо-варианта
ChatGPT прав, а люди ошиблись.
ВЫВОДЫ
Вот так. Проверял Грок3, а в итоге единственный, кто справился с задачей - o3-mini. Так еще ИИ нашел ошибку у кожаных. А помните, недавно ChatGPT считать не умел? )
Сам Грок3 норм по другим обычным задачам, Маск влетает условно в топ-5 LLM, но революции пока нет. Это не дипсик, который дешевый, опенсорсный и способный размещаться в оперативке без квантизации.
В олимпиадах (особенно в дистанционных этапах) перекос ожидаю в сторону геометрических задач, так как они сложнее пока поддаются ИИ.
Мой канал в TG: @it_sabat — запускаю стартап и регулярно тестирую новые ИИ.