Недавно вышла игра, которая похожа на Rust, где мы играем за уток! Она называется DuckSidе, а ней нужно точно также собирать ресурсы, строить базы и сражаться с другими игроками, а ко всему этому разнообразие добавляет возможность летать!
Она ещё находится в раннем доступе, но мы уже рекомендуем её попробовать, чтобы скрасить монотонные серые вечера в такой забавной игре!
Небольшие задачи (от нескольких часов до нескольких дней), возникают не регулярно, но часто.
Предвосхищая вопросы почему тут, а не на специализированных площадках - пробовал, подработка никому не интересна, только фулл-тайм (и это еще о цене речь даже не заходила).
Если есть желание - пишите в тг @whiteagle, договоримся. Задачи уже есть, самая первая и срочная - примерно часов на 20 (коннектор к платежной системе).
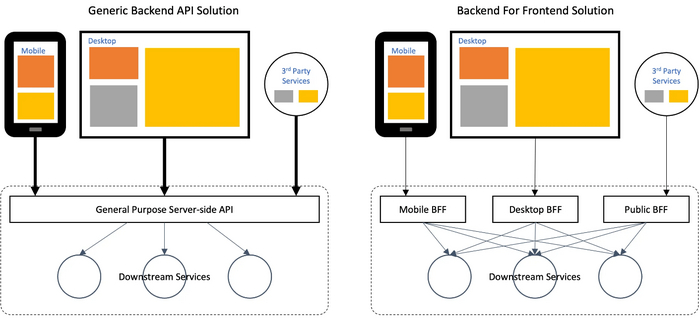
📲 Что такое Backends for Frontends и когда стоит его использовать
Backends for Frontends – это паттерн, который предполагает разработку отдельных бэкенд-сервисов, оптимизированных под фронтенд конкретных приложений (веб, мобильные, IoT и т. д.). Каждый BFF создает API, идеально подходящий для своего клиента. BFF можно рассматривать как развитие концепции API Gateway, однако между ними есть несколько ключевых отличий:
API Gateway обычно предоставляет единую точку входа для всех клиентов, а BFF создает отдельные шлюзы для каждого типа клиента (веб, мобильный и т. д.).
BFF более специализирован и ориентирован на конкретные нужды разных типов фронтендов, а API Gateway более универсален и может обслуживать разные клиенты без специфической оптимизации.
BFF больше фокусируется на оптимизации взаимодействия между конкретным фронтендом и бэкендом, в то время как API Gateway часто используется для общих задач (маршрутизация, аутентификация, балансировка нагрузки).
Как работает BFF:
API Gateway перенаправляет запросы на соответствующий BFF.
BFF взаимодействует с нужными микросервисами (например, Products, Orders, Cart).
BFF обрабатывает и оптимизирует данные для конкретного клиента.
Универсальный API vs BFF для каждого типа клиента
Паттерн появился в 2015 году, приобрел широкую известность к 2021-му и с тех пор остается одним из самых популярных подходов в разработке микросервисов. На это есть веские причины:
Оптимизация производительности – BFF позволяет настроить потоки данных и форматы ответов для каждого фронтенда, повышая скорость работы приложений.
Улучшенная безопасность – изоляция фронтендов дает возможность реализовать меры безопасности, учитывающие специфику каждого клиента.
Гибкость разработки – фронтендеры и бэкендеры могут работать более независимо, в отдельных командах, ускоряя процесс создания и обновления продукта.
Упрощение фронтенд-разработки – BFF предоставляет именно те данные, которые нужны конкретному интерфейсу, избавляя от лишней обработки на клиенте.
Упрощение поддержки и модификации API для каждого отдельного фронтенда.
Когда стоит использовать BFF:
Когда у сервиса несколько типов клиентов с разными потребностями в данных.
Если необходима серьезная оптимизация производительности для конкретных интерфейсов.
Например, BFF будет оптимальным выбором для:
E-commerce платформ – отдельные BFF для веб-сайта, мобильных приложений и умных устройств будут обрабатывать специфические потоки данных и действия пользователей.
Финансовых сервисов – специализированные BFF для веб- и мобильного банкинга обеспечат более удобное и безопасное использование сервиса.
CMS – паттерн упростит адаптивную доставку контента для разных устройств.
✍️ Как написать HTTP-сервер на Go
Платформа CodeCrafters предлагает практичный подход к обучению – разработчики там учатся и совершенствуют навыки в процессе создания реальных, готовых к использованию приложений. Например, одно из заданий – разработка HTTP-сервера. Студент успешно выполнил задание на Go без использования сторонних библиотек и рассказал о процессе работы в этом пошаговом туториале.
Основные характеристики и функциональность сервера:
Базовый TCP-сервер, слушающий порт 4221.
Обрабатывает HTTP-запросы и отправляет соответствующие ответы.
Поддерживает разные маршруты и HTTP-методы.
Обрабатывает параметры URL и заголовки запросов.
Поддерживает отправку файлов в ответ на запросы.
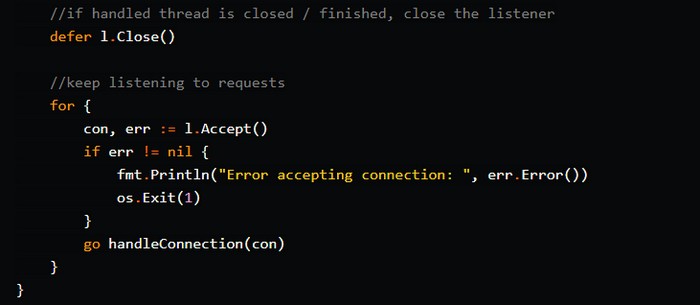
Предусматривает конкурентную обработку нескольких соединений.
Для каждого нового соединения запускается отдельная горутина
Этот проект отлично подходит для начинающих разработчиков – помогает понять, как работают веб-серверы под капотом, без абстракций, предоставляемых высокоуровневыми фреймворками. Процесс создания аналогичного сервера на Python подробно рассмотрен здесь.
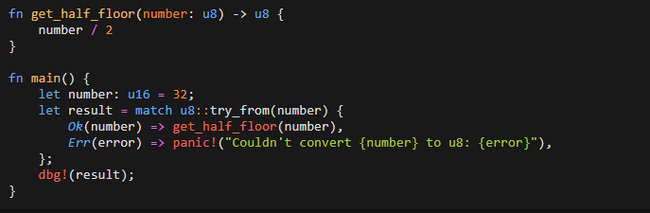
Оператор as используется для приведения типов: позволяет преобразовывать значения одного типа в другой. Но, как пишет опытный Rust-разработчик, использование as может привести к неожиданному поведению при преобразовании в меньший тип данных: если значение не помещается в целевой тип, происходит усечение без предупреждения – это приводит к появлению трудноотслеживаемых ошибок в больших проектах. Например, у нас есть число 288, которое мы хотим преобразовать в тип u8 (8-битное беззнаковое целое число). Тип u8 может хранить значения от 0 до 255. Очевидно, 288 не помещается в этот диапазон. При использовании as для преобразования вместо ожидаемой ошибки или предупреждения Rust выполняет усечение значения. В этом случае результат будет равен 32:
288 в двоичном виде: 100100000.
При преобразовании в u8 Rust берет только 8 младших битов (справа налево): 00100000.
00100000 в десятичной системе равно 32.
Это поведение станет полной неожиданностью для программистов, переключившихся на Rust с языков высокого уровня, где подобные преобразования всегда вызывают ошибки или предупреждения. Лучшее решение этой проблемы – использовать трейт TryFrom вместо as. Этот подход требует чуть больше кода, но это один из тех немногих случаев, когда отказ от стандартного приема действительно оправдан:
TryFrom явно обрабатывает случаи, когда значение не помещается в целевой тип данных
🐍 Как создать инвертированный индекс на Python
Инвертированный индекс – это структура данных, которая позволяет быстро находить документы, содержащие определенное слово или фразу. Главные преимущества инвертированного индекса:
Высокая скорость – поиск по индексу значительно быстрее, чем полный просмотр всех документов.
Эффективность для больших объемов данных – индекс позволяет эффективно обрабатывать большие коллекции документов.
Вместо того, чтобы просматривать каждый документ целиком, индекс хранит информацию о том, в каких документах встречается каждое слово. Для этого он использует хэш-таблицу (словарь в случае Python), где ключами являются слова, а значениями – списки идентификаторов документов, содержащих эти слова. Общий принцип построения индекса выглядит так:
Подготовка данных
Определяется структура документов (например, название и текст статьи).
Создается список документов.
Для каждого документа:
Преобразуется текст – переводится в нижний регистр, удаляются знаки препинания.
Обработанный текст разбивается на слова.
Для каждого слова:
Если слово еще не в индексе, создается запись с пустым списком документов.
Добавляется идентификатор текущего документа в список для данного слова.
Алгоритм поиска по индексу включает в себя:
Преобразование запроса
Запрос приводится к нижнему регистру и очищается от знаков препинания.
Преобразованный запрос разбивается на слова.
Поиск по индексу
Для каждого слова в запросе:
Находится список документов для этого слова в индексе.
Объединяются списки документов для всех слов запроса.
Получение результатов
По идентификаторам из объединенного списка находятся соответствующие документы.
Пример реализации простейшего инвертированного индекса на Python подробно описан здесь.
Сравнение скорости выполнения 20 запросов по 15 000 документов
🛠️ 18 основных паттернов микросервисной архитектуры
В этой статье подробно рассказано о паттернах, которые представляют собой набор проверенных решений типичных проблем и задач в микросервисной архитектуре. Их правильное применение может значительно улучшить масштабируемость, надежность и гибкость системы.
1. Service Registry (Реестр сервисов)
Этот паттерн решает проблему обнаружения сервисов в распределенной системе. Каждый микросервис регистрирует себя в центральном реестре (например, Netflix Eureka или Consul). Когда одному сервису нужно взаимодействовать с другим, он обращается к реестру, чтобы узнать текущий адрес нужного сервиса. Это позволяет сервисам динамически обнаруживать друг друга без жесткой привязки к конкретным адресам.
2. API Gateway (API-шлюз)
API Gateway действует как единая точка входа для всех клиентских запросов. Он принимает запросы от клиентов и перенаправляет их соответствующим микросервисам. API Gateway может также выполнять такие задачи, как аутентификация, авторизация и балансировка нагрузки. Это упрощает взаимодействие клиентов с системой, скрывая сложность внутренней архитектуры.
3. Circuit Breaker (Предохранитель)
Этот паттерн предотвращает каскадные сбои в системе. Когда один сервис начинает давать сбои, Circuit Breaker временно блокирует запросы к этому сервису, предотвращая перегрузку и позволяя системе восстановиться. Это повышает устойчивость системы и помогает избежать полного отказа всей системы из-за проблем с одним сервисом.
4. Bulkhead (Отсек)
Паттерн Bulkhead изолирует компоненты системы друг от друга, чтобы сбой в одной части не повлиял на другие. Например, для разных сервисов могут использоваться отдельные пулы потоков или базы данных. Это повышает устойчивость системы и ограничивает распространение сбоев.
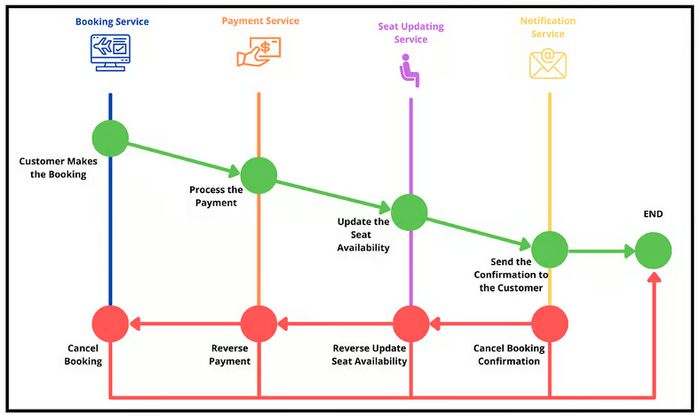
5. Saga Pattern (Сага)
Saga используется для управления распределенными транзакциями в микросервисной архитектуре. Длительная бизнес-операция разбивается на серию меньших, локальных транзакций. Каждый сервис выполняет свою часть транзакции и публикует событие, которое запускает следующий шаг. Если что-то идет не так, выполняются компенсирующие действия для отмены изменений.
Принцип работы паттерна Сага
6. Event Sourcing (Источник событий)
Вместо хранения только текущего состояния этот паттерн сохраняет все события, которые привели к этому состоянию. Это обеспечивает надежный аудиторский след и позволяет восстановить состояние системы на любой момент времени. Особенно полезен в системах, где важна история изменений и возможность отката.
7. Command Query Responsibility Segregation (CQRS, Разделение команд и запросов)
CQRS разделяет операции чтения и записи в приложении. Используются разные модели для обновления информации (команды) и чтения информации (запросы). Это позволяет оптимизировать каждую сторону независимо, что может значительно улучшить производительность и масштабируемость.
8. Data Sharding (Шардинг данных)
Этот паттерн используется для распределения нагрузки на базу данных. Данные разделяются на несколько баз данных или экземпляров базы данных. Каждый микросервис может обрабатывать подмножество данных или определенные типы запросов. Это помогает избежать узких мест в работе с данными и улучшает масштабируемость.
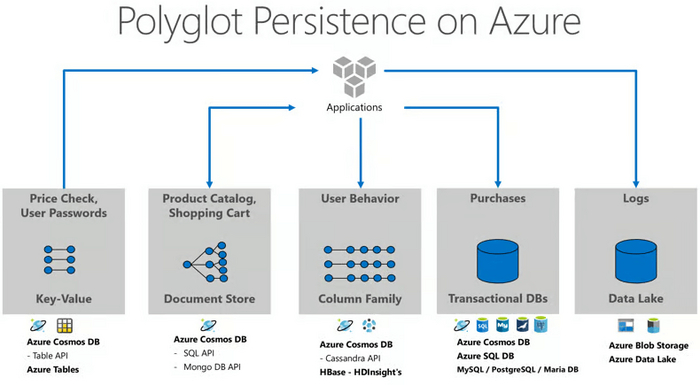
Этот подход позволяет использовать разные технологии баз данных для разных микросервисов, исходя из их конкретных потребностей. Например, один сервис может использовать реляционную БД, другой – NoSQL, третий – графовую БД. Это оптимизирует хранение, извлечение и обработку данных для каждого сервиса.
Реализация многовариантного хранения в Azure
10. Retry (Повторная попытка)
Обеспечивает повторение операции при возникновении временного сбоя – вместо немедленного отказа. Может применяться на разных уровнях: от взаимодействия между сервисами до работы с базой данных. Помогает справиться с кратковременными проблемами в сети или сервисах.
11. Sidecar (Вспомогательный сервис)
Этот паттерн предполагает присоединение вспомогательного сервиса (sidecar) к основному микросервису для обеспечения дополнительной функциональности, такой как логирование, безопасность или коммуникация с внешними сервисами. Позволяет основному сервису сосредоточиться на своей основной функции.
12. Backends for Frontends (BFF, Бэкенды для фронтендов)
BFF предполагает создание отдельных бэкенд-сервисов для каждого типа клиента (веб, мобильный и т. д.). Это позволяет оптимизировать API под конкретные нужды каждого клиента, улучшая производительность и упрощая разработку клиентской части.
13. Shadow Deployment (Теневое развертывание)
Этот паттерн предполагает отправку копии (тени) производственного трафика к новой версии микросервиса без влияния на реальный пользовательский опыт. Это позволяет проверить производительность и корректность новой версии в реальных условиях, не подвергая риску текущих пользователей.
В этом подходе потребители сервисов определяют свои ожидания от поставщиков сервисов. Это помогает обеспечить более надежные и согласованные изменения в системе. Каждый сервис-потребитель описывает, какой именно функционал и в каком формате он ожидает от сервиса-поставщика.
Этот паттерн рекомендует размещать бизнес-логику в самих микросервисах (умные конечные точки), а не полагаться на сложное промежуточное ПО. Инфраструктура коммуникаций (каналы) должна быть простой и заниматься только маршрутизацией сообщений. Это упрощает систему и делает ее более гибкой.
16. Database per Service (База данных для каждого сервиса)
В этом паттерне каждый микросервис имеет свою собственную базу данных, и сервисы общаются через четко определенные API. Это обеспечивает изоляцию данных и независимость сервисов, но требует тщательного подхода к обеспечению согласованности данных между сервисами.
17. Async Messaging (Асинхронный обмен сообщениями)
Вместо синхронного взаимодействия между микросервисами этот паттерн предполагает использование очередей сообщений для асинхронной коммуникации. Это может улучшить отзывчивость системы и ее масштабируемость, так как сервисы не блокируются в ожидании ответа друг от друга.
18. Stateless Services (Сервисы без состояния)
Проектирование микросервисов как stateless (без сохранения состояния) упрощает масштабирование и повышает устойчивость. Каждый сервис обрабатывает запрос независимо, не полагаясь на сохраненное состояние – это облегчает горизонтальное масштабирование.
В 2024 году Python исполняется 33 года. За это время он прошел невероятный путь – от пет-проекта до одного из самых универсальных и популярных языков. Все начинающие питонисты знают, что первую версию языка разработал голландский программист Гвидо ван Россум, а назван он в честь британского комедийного шоу, а не прожорливой змеи. Как развивались основные концепции языка, почему крупные ИТ-компании боялись, что автобус может переехать Гвидо, и когда на логотипе Python все-таки появились змеи – расскажет публикация на Хабре.
🏆 Лучшие практики разработки на Python
Знание и правильное применение лучших практик – один из самых важных навыков профессионального разработчика. Следование общепринятым правилам позволяет:
Повысить качество кода. Лучшие практики основаны на многолетнем опыте обширного сообщества разработчиков и направлены на минимизацию ошибок, улучшение читаемости и поддерживаемости кода. Это помогает создавать более надежные и долговечные системы.
Ускорить процесс разработки. Применение многократно опробованных шаблонов и подходов помогает быстрее писать типовой код и решать распространенные проблемы.
Упростить совместную работу, ревью кода и интеграцию изменений. Особенно в больших командах и опенсорсных проектах.
Обеспечить гибкость и масштабируемость проекта. Правильно организованный код легче адаптировать под новые требования и масштабы. Это снижает риск технического долга — ситуации, в которой изменения становятся слишком дорогостоящими или сложными для реализации.
Привет!
Всю неделю мы мониторим интернет, чтобы в воскресенье прислать тебе интересное письмо. Наша цель – держать читателей в курсе последних открытий и тенденций в мире Python. В еженедельных письмах ты найдешь:
Новые возможности в последних версиях Python
Работа с базами данных и SQL в Python.
Веб-разработка на Django и Flask.
Машинное обучение и анализ данных с помощью Python.
Устанавливайте Python с поддержкой нескольких версий. Используйте mise или pyenv для установки Python – они дают возможность переключаться между разными версиями языка и позволяют обновлять интерпретатор без влияния на другие инструменты и проекты. Еще один отличный вариант – Development Containers.
Используйте последнюю версию Python. Для новых проектов выбирайте самую последнюю стабильную версию Python 3. Это обеспечивает наличие последних исправлений безопасности и максимальную производительность. Обязательно обновляйте проекты по мере выхода новых версий языка и забудьте про Python 2.
Используйте pipx для запуска приложений в среде разработки. Вместо установки пакетов с помощью pip или другого аналогичного метода используйте pipx для запуска инструментов в отдельной виртуальной среде.
Не используйте Poetry для новых проектов – в нем нестандартно реализованы некоторые ключевые функции. Лучше пользоваться PDM или Hatch.
Создавайте файл pyproject.toml в корневой директории каждого проекта – для хранения информации о конфигурации и используемых инструментах.
Используйте src-структуру для каталогов. Это требует использования редактируемых установок, но PDM и Hatch упрощают задачу.
Используйте виртуальные среды для разработки. Виртуальная среда изолирует проекты и наборы установленных для них пакетов – не будет никаких конфликтов.
Применяйте файлы requirements.txt для установки пакетов в среду – вместо использования команды pip. Либо используйте PDM или Hatch для управления пакетами.
Используйте инструмент для форматирования кода и линтер для проверки на ошибки. Самый популярный форматер Python-кода – Black, а самый известный линтер – flake8. Однако их с успехом можно заменить одним мощным и быстрым инструментом – Ruff.
Применяйте pytest для тестирования, а в ситуациях, где это невозможно – используйте стандартный модуль unittest.
Используйте PyInstaller для упаковки приложений в исполняемый файл. А свои пакеты публикуйте в виде wheel, чтобы другие разработчики могли загружать их с помощью pipx и pip-sync.
Используйте аннотации типов – особенно в важных приложениях и библиотеках. Для проверки вам пригодится mypy, а для интеграции этого инструмента с Pydantic – плагин.
Форматируйте строки с помощью f-строк, а не с использованием %, str.format() или str.Template().
Всегда используйте объекты datetime, которые знают о временных зонах. По умолчанию Python создает объекты datetime, которые не включают временную зону.
Применяйте enum или collections.namedtuple() для неизменяемых наборов пар «ключ-значение».
Создавайте классы данных для пользовательских объектов. Среди прочего это позволяет сократить количество кода, необходимого для определения классов, предназначенных для хранения значений. Экземпляры таких классов можно замораживать.
Используйте collections.abc для пользовательских типов коллекций. Абстрактные базовые классы в collections.abcреализованы на C и работают очень быстро.
Применяйте breakpoint() для отладки. Эта функция создает точки останова, которые могут использовать и встроенный отладчик, и внешние инструменты отладки.
Используйте журналирование для диагностических сообщений. Команда print() удобна для вывода отладочной информации, но в скрипты и приложения нужно включать логирование.
Применяйте формат TOML для конфигурационных файлов – если они предназначены для людей. Используйте формат JSON для данных, которые передаются между компонентами приложения.
Используйте async только там, где это необходимо. Асинхронные возможности Python позволяют одному процессу избегать блокировки на операциях ввода-вывода. Для запуска нескольких процессов нужно использовать контейнеры или сервер Gunicorn. Чтобы создать собственное приложения для управления многочисленными процессами, воспользуйтесь этим стандартным пакетом.
Обрабатывайте ввод из командной строки с argparse. Модуль argparse теперь является рекомендуемым способом обработки ввода вместо устаревших optparse и getopt.
Для указания путей к файлам и каталогам используйте pathlib, а не строки.
Используйте os.scandir() вместо os.listdir(). Функция os.scandir() значительно быстрее и эффективнее, чем os.listdir().
Запускайте внешние команды с subprocess. Модуль subprocess предоставляет безопасный способ запуска внешних команд. Используйте его вместо spawn, popen2 и popen3.
Используйте httpx для клиентских приложений. Пакет httpx поддерживает HTTP/2 и async и заменяет requests, который работает только с HTTP 1.1.
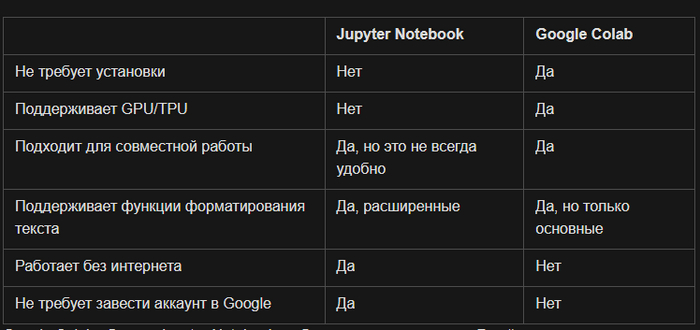
📒 Google Colab или Jupyter Notebook: что лучше подойдет для новичка
Jupyter Notebook обладает массой очевидных достоинств:
Позволяет выполнять код по частям и мгновенно видеть результаты.
Поддерживает большинство популярных библиотек.
В блокнотах легко визуализировать данные и форматировать текст.
Устанавливается локально, работает без подключения к сети.
Облачный сервис Google Colab предоставляет похожую функциональность – код можно писать и выполнять в браузере – и несколько дополнительных преимуществ:
Использование GPU/TPU.
Удобное меню навигации по файлу.
Возможность совместной работы над проектом – настойка доступа и синхронизация работают точно так же, как в документах Google.
Подробнее о преимуществах и начале работы в Google Colab – в этой статье на Хабре
Беспрецедентное развитие ИИ сделало Python суперпопулярным языком – и поставило исключительно сложную задачу перед ведущими инженерами: как увеличить скорость работы Питона, не жертвуя его простотой и гибкостью. Одним из решений проблемы стал перенос критически важных для производительности частей кода на более быстрые языки – C, C++ и Rust. Для упрощения совместного использования Python и Rust разработчик Дэвид Хьюитт создал PyO3. В этом интервью он подробно рассказал о сложностях разработки такого проекта и его впечатляющих возможностях.
Как преодолеть разрыв
Интеграция Python и Rust – нетривиальная задача, поскольку эти два языка имеют принципиально разные подходы к управлению памятью, потоками и обработке ошибок. Однако PyO3 решает эти проблемы, используя мощные возможности Rust и C-образную архитектуру интерпретатора Python.
В основе PyO3 лежит концепция сопоставления функций и структур Rust их аналогам в Python. Используя процедурные макросы, PyO3 генерирует необходимый код для создания совместимых с Python объектов и функций, позволяя разработчикам Python легко взаимодействовать с компонентами на базе Rust. Этот подход позволяет программистам на Python воспользоваться преимуществами производительности и безопасности Rust без необходимости глубоко погружаться в тонкости языка.
Безопасность памяти и время жизни объектов
Одна из ключевых задач при объединении Python и Rust – обеспечение безопасности памяти. Система проверки заимствований и времени жизни объектов в Rust играет в этом отношении важную роль. PyO3 использует аннотации времени жизни Rust для управления владением и временем жизни объектов Python, гарантируя, что ссылки на объекты Python являются действительными, а доступ к памяти не осуществляется после ее освобождения. Это внимание к безопасности памяти является существенным преимуществом использования Rust в контексте оптимизации производительности Python. Обеспечивая эти гарантии во время компиляции, PyO3 помогает разработчикам избежать распространенных ошибок и уязвимостей, связанных с памятью, которые могут возникать при использовании привязок C/C++.
Обработка ошибок и производительность
Это одно из самых мощных преимуществ PyO3. Сопоставляя механизмы обработки ошибок Rust с системой исключений Python, PyO3 обеспечивает бесшовную интеграцию для программистов, работающих с обоими языками. Эта интеграция гарантирует правильную передачу ошибок, позволяя коду Python элегантно обрабатывать исключения, созданные в Rust. Что касается производительности, PyO3 стремится обеспечить производительность, близкую к нативной, за счет использования абстракций Rust. Хотя на границе между Python и Rust могут быть некоторые накладные расходы, прирост производительности, достигаемый внутри кода Rust, часто с лихвой компенсирует их. По мере развития проекта PyO3 команда активно работает над оптимизацией этих пограничных случаев для дальнейшего снижения влияния на производительность.
Потоки и асинхронность
Одна из самых сложных областей интеграции Python и Rust – обработка потоков и асинхронности. Асинхронная модель Rust с async/await и глобальная блокировка интерпретатора (GIL) Python представляют собой уникальные проблемы, которые команда PyO3 активно решает. Разработчики исследуют различные подходы к преодолению разрыва между моделями параллелизма Rust и Python, в том числе использование типов Rust Send и Sync для обеспечения безопасного обмена данными между потоками, а также обеспечение бесшовной совместимости между асинхронными средами выполнения Rust и циклами событий Python.
Друзья, не едиными Дальнобойщиками живут южные Игуси, сегодня у нас в меня сурвивал Раст) Пойдем кашмарить ботов на нефтевышку 😈 Залетайте в гости 🦔 Стрим 18+ будьте готовы к эмоциям и великому и могучему Русскому Языку во всей его красе 💪😎