

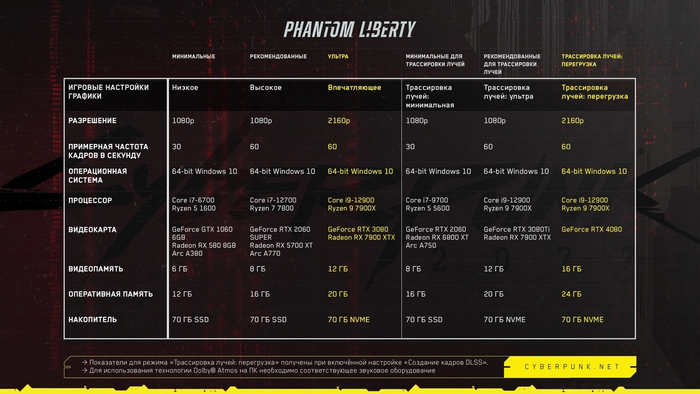
Системные требования для DLC "Призрачная Свобода" к Cyberpunk 2077
DLC выйдет 26 сентября на ПК и консолях нового поколения без русской озвучки, только с субтитрами. Цена - 30$
Источник - паблик Cyberpunk 2077
DLC выйдет 26 сентября на ПК и консолях нового поколения без русской озвучки, только с субтитрами. Цена - 30$
Источник - паблик Cyberpunk 2077
Всем привет.
Настала пора наконец закончить с прелюдиями и перейти к рассказу про один из самых важных навыков системного аналитика - REST. Больше важны навыки практического применения\проектирования, но и теория тоже важна. Как минимум для прохождения собеседования, потому что значительная часть вопросов приходится как раз на интеграцию и знание REST в том числе.
В следующем посте разбавлю серию только теоретических - практикой. Приведу шаблон того, как можно описывать API.
REST
Representational State Transfer (REST) в переводе — это передача состояния представления.
Сам по себе REST – это архитектурный стиль взаимодействия компонентов распределённого приложения в сети. Архитектурный стиль – это набор согласованных ограничений и принципов проектирования, позволяющий добиться определённых свойств системы.
И у него есть определенные принципы, которые важно понимать и применять при проектировании системы.
В рамках данного принципа самое важное - это отделение клиента и сервера. Клиент - это интерфейсная часть (уровень представления), сервер - это центральное звено системы, на котором реализованы все основные функции системы (наш backend). Более подробно рассмотрено в части 6 этой серии.
Это понятие означает, что сервер не должен хранить информацию о состоянии клиента, в том числе информацию о предыдущих запросах клиента, а клиент не должен знать ничего о текущем состоянии сервера.
Это не значит, что у них вообще нет состояния, но они не отслеживают состояние друг друга (что очень удобно, т.к. избавляет нас от необходимости держать постоянное неразрывное соединение между двумя системами).
Поэтому каждый запрос рассматривается индивидуально, как будто бы не было ничего до, и не будет после. Соответственно клиент в этом случае, обязан предоставить все необходимые данные для успешного выполнения запроса. Это, пожалуй, почти единственная логика, которая должна быть на клиенте.
Принцип гарантирует, что между клиентом и сервером существует общий язык (интерфейс), с помощью которого они будут понимать друг друга. Т.е. клиент посылает понятные серверу запросы, использую конкретные HTTP-методы, сервер посылает ответ в понятном клиенту формате.
Это достигается через несколько субограничений:
Идентификация ресурсов
В терминологии REST что угодно может быть ресурсом — HTML-документ, изображение, информация о конкретном пользователе - то, чему можно дать имя. Каждый ресурс должен быть уникально обозначен постоянным идентификатором. «Постоянный» означает, что идентификатор не изменится за время обмена данными, и даже когда изменится состояние ресурса. Если ресурсу присваивается другой идентификатор, сервер должен сообщить клиенту, что запрос был неудачным и дать ссылку на новый адрес.
Тут важно понимать, что в REST (в идеале, по крайней мере), ресурс может быть только существительным, а не глаголом. Потому что за "глагол", т.е. действие - отвечает конкретный метод.
2. Управление ресурсами через представления
Второе субограничение «унифицированного интерфейса» говорит, что клиент управляет ресурсами, направляя серверу представления, обычно в виде JSON-объекта, содержащего контент, который он хотел бы добавить, удалить или изменить. В REST у сервера полный контроль над ресурсами, и он отвечает за любые изменения.
Когда клиент хочет внести изменения в ресурсы, он посылает серверу представление того, каким он видит итоговый ресурс (а для этого, сервер сначала должен предоставить эту информацию клиенту). Сервер принимает запрос как предложение, но за ним всё так же остаётся полный контроль.
3. Самодостаточные сообщения
Самодостаточные сообщения — это ещё одно ограничение, которое гарантирует унифицированность интерфейса у клиентов и серверов. Только самодостаточное сообщение содержит всю информацию, которая необходима для понимания его получателем. В отдельной документации или другом сообщении не должно быть дополнительной информации.
В данных запроса должно быть указано, нужно ли кэшировать данные (сохранять в специальном буфере для частых запросов). Если такое указание есть, клиент получит право обращаться к этому буферу при необходимости.
Это нужно для того, что максимально ускорить обработку запроса от клиента. Для примера, если нам нужно часто получать информацию о пользователе (а сама информация о пользователе меняется достаточно редко, что важно), то мы можем закэшировать эту информацию.
Т.е. стандартный запрос выглядит условно так: Фронт -> микросервис адаптер к фронту -> какой-нибудь микросервис MDM системы пользователей -> база где лежат пользователи и потом обратный путь. Это не прям мгновенно всё происходит. Что мы делаем - например, наш фронт прислал запрос GET /user/121, мы проделали этот путь, описанный выше, но еще и сохранили эти данные в кэше на уровне микросервиса-адаптера. В следующий раз, когда фронт вызовет метод GET /user/121, наш путь будет намного короче и быстрее - всего лишь от фронта к нашему же микросервису в кэш и сразу обратно.
Тут есть множество нюансов, которые нужно учесть - но в целом полезный инструмент.
Система слоев предполагает наличие большего количества компонентов, чем клиент и сервер. В системе может быть больше одного слоя. Тем не менее, каждый компонент ограничен способностью видеть только соседний слой и взаимодействовать только с ним.
Но что самое замечательное, при добавлении новых слоев между клиентом и сервером - их не нужно дорабатывать. Т.е. не важно, если у нас архитектура выглядит как просто "Клиент" -> "Сервер", или "Клиент" -> "Прокси" -> "Балансировщик" -> "Несколько серверов" - их логика не меняется (тут разработчики могут меня поправить или дополнить, буду благодарен).
Что-то вроде того:
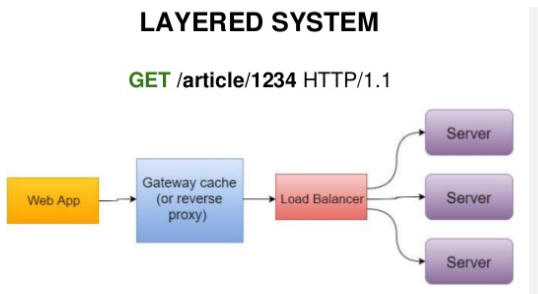
Еще есть отдельный принцип "Код по требованию", который подразумевает то, что клиент может получить с сервера прям "кусок кода" (условно), который ему необходимо выполнить у себя.
Звучит интересно, но честно, ни разу не сталкивался, поэтому не могу что-то детальное рассказать.
P.S.: В следующих постах расскажу про best practices, связанных с именованием эндпоинтов и прочими полезными штуками для проектирования своих апишек.
По традиции - буду признателен за вопросы про карьеру\профессию\чему угодно связанному со сферой IT - постараюсь ответить на всё.
P.P.S.: Также веду телеграмм-канал, в котором делюсь разным про профессию и про свой путь в ней. Есть и хардовая информация (асинхронные, синхронные интеграции, примеры ТЗ\шаблонов написания микросервисов), так и более софтовая - см. закрепленный дайджест.
Всем привет.
В прошлом посте рассказал про HTTP в целом и много раз упоминал различные методы, но еще не рассказал что это такое - разбираемся.
Как я уже писал, метод - это название запроса, которое определяет то действие, которое будет совершаться в результате его выполнения.
Их всего 6 основных:
Метод GET предназначен для получения информации о каком-то конкретном ресурсе или массиве ресурсов. Он никак не изменяет эту информацию.
Похож на GET, но не возвращает тело ответа, а только стартовую строку и заголовки. Используется для получения метаданных, а также проверки и валидации ресурса.
Честно говоря - ни разу не приходилось использовать его на практике или даже просто видеть. Но могу предположить, что его можно использовать в том случае, когда нам нужно ткнуть какой-то ресурс палочкой и спросить - а ты вообще существуешь? Ну и, возможно, получить по нему какую-то метаинформацию.
Условно, можно вызвать HEAD /users/127 - мы получим в ответе HTTP 200, в том случае, если этот пользователь с идентификатором = 127 существует. И 404 - если нет.
Если же вызвать GET /users/127 - то мы получим HTTP 200 + тело ответа, в котором будет содержаться вся информации о пользователе с идентификатором 127 (ну тут смотря как реализовать, но по дефолту будет так).
Создает новый ресурс из переданных данных в запросе. Но это лишь по дефолту.
На самом деле POST самый универсальный метод и им возможно делать всё - и получать информацию, и создавать, и редактировать, и удалять, и запускать какие-то процессы. Тут важно понимать - почему именно так.
Например, мы можем использовать POST для поиска в том случае, если нам нужно зашифровать поисковые параметры в теле запроса, а не оставлять их в открытом виде в query-параметрах (прям в строке запроса). Либо использовать для поиска в том случае, если поисковых параметров слишком много и строка запроса получается слишком огромной - а у нее есть определенное ограничение по длине (очень больше, но всё-таки есть).
Можно использовать для запуска различных команд в оркеструющих микросервисах или коммандерах. Т.е. напрямую у нас никакой объект не создается, физических и лежащий в БД - но у нас создается (запускается) какой-нибудь бизнес-процесс.
Применений у этого метода очень много.
Изменяет содержимое ресурса по-указанному URI. PUT полностью заменяет существующую сущность.
Похож на PUT, но применяется только к фрагменту ресурса (заменяет точечно только часть ресурса)
Для понимания: Например, у вас есть объект user, у которого 5 атрибутов - Ф, И, О, дата рождения и пол. Если у вас поменялась информация о пользователе №5, например изменилась фамилия - и вы вызовете метод PUT /users/5, и передадите в теле запроса только фамилию, то на выходе у вас останется объект user с id = 5, и фамилией = тому, что вы передали в запросе. Все остальные атрибуты затрутся. Поэтому для обновления необходимо передавать все объект целиком, включая те атрибуты, которые не менялись.
Если же вы вызовете метод PATCH /users/5 с таким же запросом, то у вас обновится только фамилия, остальной объект останется не тронутым.
Логичный вопрос - а зачем тогда вообще использовать PUT? Ответ достаточно простой - он намного проще в реализации. Куда проще передать объект целиком ценой нескольких байт трафика и подменить его, чем обновлять каждый атрибут по отдельности, маппить их и т.д. Особенно если у вас какой-нибудь огромный объект, типа "Заявка на кредит", у которой под тысячу атрибутов, а вам нужно обновить 200 из них.
Тут разработчики могут меня поправить, но объясняли мне в свое время так.
Удаляет конкретный ресурс по-указанному URI.
Интересное: на самом деле нет никаких проблем с тем, чтобы заставить метод GET создавать какой-нибудь ресурс или заставить метод DELETE обновлять. Т.е. это не технические ограничение, это "лишь" концептуальная идеология того, как правильно (и для чего) использовать различные методы.
Чтобы на всех проектах, все участники разработки были в едином контексте. И когда вы будете видеть какой-нибудь метод, типа POST /loanApplication/{loanApplicationId}/offers - вы явно поймете, что это метод предназначенный для добавления новых офферов конкретной заявке на кредит.
P.S.: По традиции - буду признателен за вопросы про карьеру\профессию\чему угодно связанному со сферой IT - постараюсь ответить на всё.
P.P.S.: Также веду телеграмм-канал, в котором делюсь разным про профессию и про свой путь в ней. Есть и хардовая информация (асинхронные, синхронные интеграции, примеры ТЗ\шаблонов написания микросервисов), так и более софтовая - см. закрепленный дайджест.
Всем привет.
Сегодня рассмотрим такой важный протокол, как HTTP. Важный потому, что именно его используют в качестве протокола передачи данных современные технологии интеграции (REST, gRPC).
HTTP расшифровывается как HyperText Transfer Protocol, «протокол передачи гипертекста». Изначально этот протокол использовался для передачи гипертекстовых документов в формате HTML. Сегодня он используется для передачи произвольных данных - c помощью него можно передавать хоть JSON, хоть XML.
В основе HTTP - клиент-серверная структура передачи данных․ Клиент формирует запрос (request) и отправляет на сервер; на сервере запрос обрабатывается, формируется ответ (response) и передается клиенту.
HTTP не шифрует передаваемую информацию. Для защиты передаваемых данных используется расширение HTTPS (Hyper Text Transfer Protocol Secure), которое “упаковывает” передаваемые данные в криптографический протокол SSL или TLS. Но это совсем другая история)
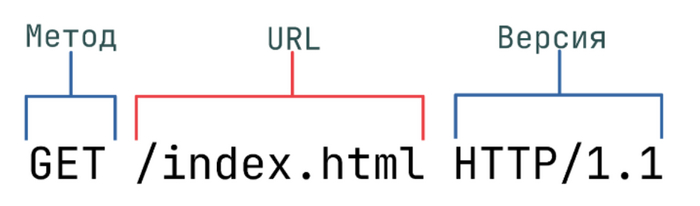
HTTP запрос состоит из трех основных частей: строка запроса (request line), заголовок (message header) и тело сообщения (entity body). Тело сообщения не является обязательным параметром. Между заголовком и телом есть пустая разделительная строка.
В строке запроса указывается:
Метод – название запроса (определяет действие), одно слово из стандартного списка, заглавными буквами;
URI определяет путь к запрашиваемому ресурсу;
Версия – пара разделённых точкой цифр. Например: 1.0.
Пример HTTP запроса:
Заголовок запроса добавляет некоторую дополнительную информацию к сообщению запроса, которое состоит из пар «имя / значение», по одной паре на строку, а имя и значение разделяются двоеточием.
Обычно в заголовках передается какая-либо мета информация. Например, токен.
Последней частью запроса является его тело. Оно бывает не у всех запросов: запросы, собирающие (fetching) ресурсы, такие как GET, HEAD, DELETE, или OPTIONS, в нем обычно не нуждаются и тела запроса у них быть не должно (так реализовать метод можно, но это не правильно).
В то же время для методов POST, PUT, PATCH - тело использовать можно и нужно.
Структура ответа, в целом, идентична структуре запроса. Также есть строка статуса, заголовок и тело.
Стартовая строка ответа HTTP, называемая строкой статуса, содержит следующую информацию:
Пример строки статуса: HTTP/1.1 404 Not Found.
Более подробно про коды состояния и как их использовать расскажу как-нибудь в другой раз.
Пример ответа:
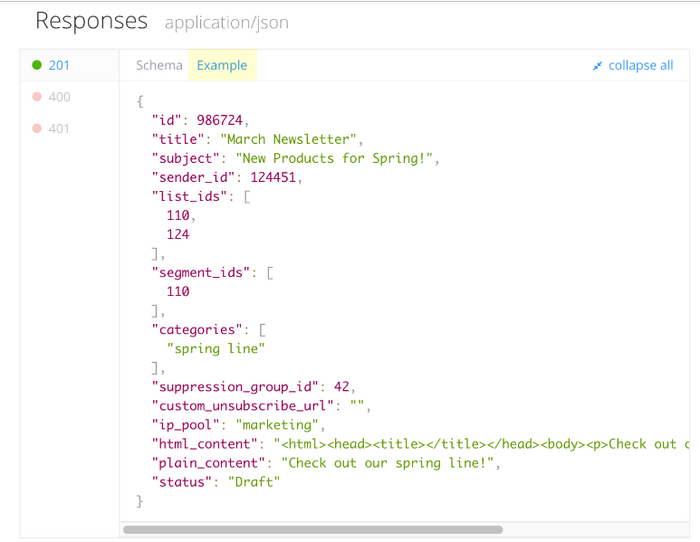
Заголовки ответов HTTP имеют ту же структуру, что и все остальные заголовки: не зависящая от регистра строка, завершаемая двоеточием (':') и значение, структура которого определяется типом заголовка. Весь заголовок, включая значение, представляет собой одну строку.
Тело присутствует не у всех ответов. Например, если мы вызываем метод DELETE, чтобы удалить какую-либо сущность, то в ответ нам вернется лишь строка статуса с HTTP-кодом 204.
Как правило тело ответа используется в том случае, когда нам нужно вернуть вызывающей стороне информацию о ресурсе. Например, если мы вызываем метод GET /users/25, то в ответе вернется полная информация о пользователе с идентификатором = 25.
P.S.: По традиции - буду признателен за вопросы про карьеру\профессию\чему угодно связанному со сферой IT - постараюсь ответить на всё.
P.P.S.: Также веду телеграмм-канал, в котором делюсь разным про профессию и про свой путь в ней. Есть и хардовая информация (асинхронные, синхронные интеграции, примеры ТЗ\шаблонов написания микросервисов), так и более софтовая - см. закрепленный дайджест.
Всем привет.
Сегодня продолжим погружаться в системный анализ, в его техническую часть.
Перед тем как начать изучать REST, API и все что с этим связано - нужно изучить, хотя бы верхнеуровнево, архитектуру, на базе которой строятся все современные приложения. Для этого рассмотрим клиент-серверную архитектуру.
Архитектура «клиент-сервер» определяет общие принципы организации взаимодействия в сети, где имеются серверы, узлы-поставщики некоторых специфичных функций (сервисов) и клиенты, потребители этих функций.
В клиент-серверной архитектуре одним из основных вопросов является вопрос о том, как разделить клиентов и серверы. Так, приложения типа клиент-сервер разделяют на три уровня:
уровень представления - на уровне представления обеспечивается взаимодействие с пользователем приложения с помощью пользовательского интерфейса. Его основное предназначение состоит в отображении информации (все формочки, кнопочки и т.д.) и получении информации от пользователя. Этот уровень может работать в веб-браузере или как графический пользовательский интерфейс компьютерного или мобильного приложения.
уровень бизнес-логики - центральное звено приложения, на котором реализованы все основные функции системы. Обрабатывается вся информация, собранная на уровне представления согласно бизнес-правилам для выполнения конкретных бизнес-целей системы. Кроме того, уровень приложения может добавлять, изменять и удалять данные, расположенные на уровне данных;
уровень данных - функции управления ресурсами. На данный момент в современных приложениях его роль зачастую выполняет реляционная (или нереляционная) система управления базами данных.
Т.е. система реализована таким образом, что собирает всю ту информацию, которую пользователь ввел на интерфейсном уровне, затем передает ее на уровень бизнес-логики, каким-то образом обрабатывает с учетом всех бизнес-правил и затем либо возвращает обогащенную информацию обратно, либо сохраняет ее в базу.
Клиент-серверная архитектура делится на двухзвенную и трехзвенную.
Двухзвенная архитектура
Двухзвенной (two-tier, 2-tier) она называется из-за необходимости распределения трех базовых компонентов между двумя узлами (клиентом и сервером). Двухзвенная архитектура используется в клиент-серверных системах, где сервер отвечает на клиентские запросы напрямую и в полном объеме, при этом используя только собственные ресурсы. Т.е. сервер не вызывает сторонние сетевые приложения и не обращается к сторонним ресурсам для выполнения какой-либо части запроса.
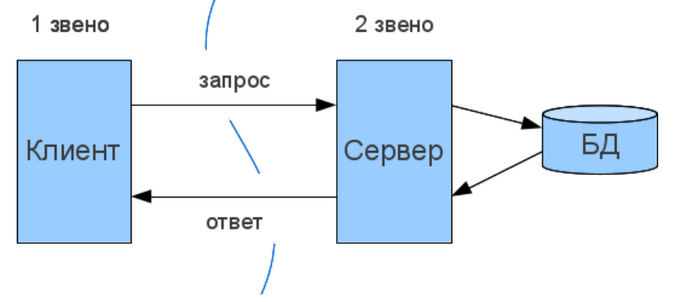
В двухзвенной клиент-серверной архитектуре используется так называемый «толстый» клиент, который выполняет отображение информации и обработку всех данных (порядка 80 % всех работ). Сервер осуществляет только хранение и предоставление данных (порядка 20 % работ).
Толстый клиент - это когда приложение напрямую запущено через условный .exe файл на вашем компьютере и работает в отдельном окне (всякие ERP\WMS системы, те же клиенты 1С и пр. не облачные штуки). Собственно их основной минус в том, что т.к. нет выделенного сервера - все функции реализуются на уровне клиента, который потребляет только те ресурсы, которые доступны компьютеру, на котором это приложение установлено.
А большинство офисных компьютеров, как известно, не отличаются большой производительностью, поэтому необходимость сформировать условный отчет даже из относительно небольшого количества данных заставляет их сильно задуматься. Это если не говорить о необходимость формировать или отображать какие-нибудь таблицы, состоящие из нескольких миллионов строк.
Трехзвенная архитектура
Собственно именно эти недостатки в большей степени послужили толчком к появлению трёхзвенной клиент-серверной архитектуры с отдельно выделенным сервером приложений.
Выглядит это всё схематично следующим образом:
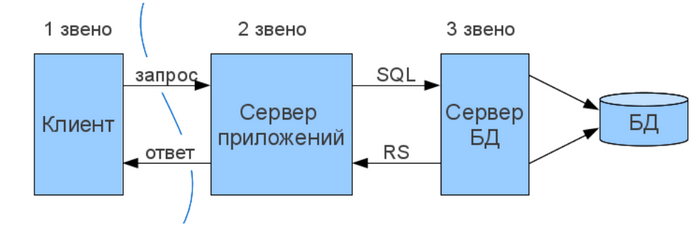
Также в этой архитектуре мы уже можем позволить себе использовать "тонкий клиент", т.е. просто страницу в вашем веб-браузере или мобильное приложение. И с учетом этого, мы просто обязаны вынести из него всю логику (даже простейшую валидацию желательно перенести на уровень бизнес-логики, либо, как минимум, дублировать), потому что у него не остается почти никаких ресурсов для ее выполнения.
Всё, на что способен тонкий клиент - это отображать интерфейс, взаимодействовать с пользователем, посылать запросы на сервер по любому чиху и обрабатывать ответы от него. Ну и иногда, по мере какой-то острой необходимости, горящих сроков или чего-то в этом духе можно запихнуть в него какую-то логику, но стараемся этого избежать.
Но при этом мы получаем монструозный (в плане его мощностей) сервер, который способ обслуживать огромное количество клиентов одновременно, в многопоточном режиме обработки данных и выполнять необходимую бизнес-логику за какие-то доли секунд, даже при большом объем данных.
P.S.: По традиции - буду признателен за вопросы про карьеру\профессию\чему угодно связанному со сферой IT - постараюсь ответить на всё.
P.S. Также веду телеграмм-канал, в котором делюсь разным про профессию и про свой путь в ней. Есть и хардовая информация (асинхронные, синхронные интеграции, примеры ТЗ\шаблонов написания микросервисов), так и более софтовая - см. закрепленный дайджест.

Сначала The Lord of the Rings: Gollum, которая требует RTX 3060 в минималках, теперь появились требования для Immortals of Aveum, где для FHD на средне-низких, вам нужна RTX 2080 Super либо Radeon RX 5700 XT! Рекомендованные требования и вовсе одни из самых высоких на данный момент, RTX 3080 Ti хватит лишь для средне-высоких в 2K 60 FPS.
Разработчики называют игру Call of Duty с магией, выходит 20 июля.

Новости Мой Компьютер
В минималках теперь RTX 3060, а вместо RTX 3080 для 2K появилась RTX 4070. Игра создаётся на Unreal Engine 4 и выходит 25 мая.

Новости Мой Компьютер




