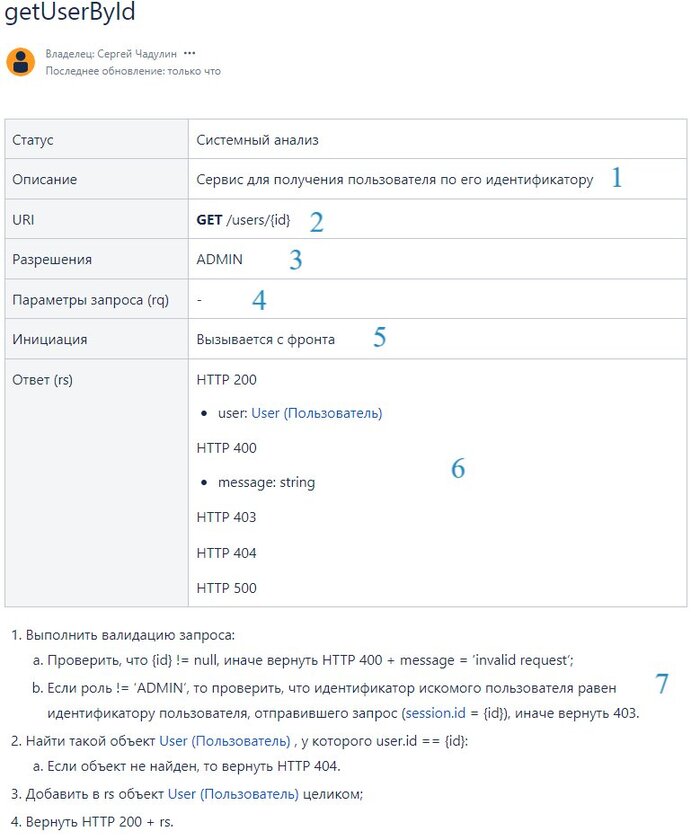
Предыдущая часть привлекла много внимания и активности (более 200 комментариев, ого) - спасибо всем тем, кто комментировал, оставлял дельные советы и дельное же мнение по поводу сабжа и около него. Особенно интересно было почитать некоторые ветки комментариев, которые жили сами по себе и были сугубо техническими - достаточно развивающе было для меня, почитать про то, как это всё видят разработчики со своей стороны.
В следующем посте разберу какой-нибудь чуть более сложный пример ТЗ для POST метода, заодно покажу один из шаблонов того, как можно описывать модель данных. И когда-нибудь созрею и расскажу про то, как мы использовали связку asciidoc + git для ведения документации.
А сегодня немного отвлечемся от прикладных навыков, отдохнем, и поговорим про то, как вообще должна жить задача на разработку и какой путь она должна пройти для того, чтобы внедрение получилось как можно более качественным.
Всё должно начинаться с ключевого лица в данном процессе - заказчика. Он должен сформулировать постановку задачи и ее цель (хотя бы попытаться). На одном из проектов бизнес-заказчики писали BRD (Business Requirements Document), в котором излагались ключевые требования к задаче, ее экономическое обоснование и различные пожелания к итоговому результату.
На самом деле очень полезная история для всех участников процесса разработки, по крайней мере мне - как системному аналитику было это интересно, и я лучше понимал то, зачем вообще нужна эта фича и как я помогу компании, реализуя ее (это, в том числе, помогало выбирать более правильные пути решения задачи).
Бизнес-анализ
Дальше должен идти этап бизнес-анализа задачи, в результате которого должны появится качественные БТ (бизнес-требования), в которых детально описано то, как процесс нужно изменить, чтобы выполнить цели задачи. Как именно это будет описано - уже не важно, хоть через AS IS\TO BE, хоть простым русским языком.
Если же задача сугубо техническая или небольшая, то, в целом, можно этот этап опустить - нужно всё-таки рационально тратить ресурсы.
Проработка архитектуры
На этом этапе, очень желательно, чтобы архитекторы дали своё заключение по задаче и указали, как минимум то, какие системы требуется доработать (потому что со стороны системного анализа это не всегда явно видно). А если задача комплексная и кроссфункциональная - то написать полноценное AR (архитектурное решение), в рамках которого будут расписаны верхнеуровневые требования к системам, схемы интеграции, на основе которых уже системные аналитики конкретных команд будут писать свои ТЗ.
Опять же, на одном из проектов был процесс, когда архитекторы системы оценивали КАЖДУЮ задачу и даже если она была небольшой, то не писали больших документов, а прям в JIRA писали краткое архитектурное заключение о том, какие процессы требуется доработать (и это было прям хорошо, заметно снизило количество кросскомандных недоработок).
Системный анализ
На этом этапе у аналитика уже есть все документы и информация для того, чтобы понять нюансы задачи, сделать правильные выводы, выбрать оптимальное решение и написать качественное ТЗ.
Потому что если такой предварительной подготовки нет, то СА приходится самостоятельно эти приседания выполнять: уточнять какие-то нюансы у заказчика, ходить к архитектору (если он вообще есть)\смежным командам и спрашивать нет ли влияния твоей доработки на их системы (хотя на опыте, ты уже и сам зачастую это знаешь).
И вместо того, чтобы сделать задачу за неделю, ты тратишь две (а потом еще два месяца на круговые согласования. Не буду говорить где - кто знает, тот знает). А если потом еще что-то вскрывается на этапе тестирование - становится еще веселее)
Разработка
Разработчику также много проще разрабатывать задачу, когда есть не только ТЗ, но и различные документы более верхнеуровневого характера (сужу по фидбекам коллег).
Как минимум потому, что многим разработчикам (по крайней мере из тех, с кем я работал) тоже интересно если не погружаться глубоко в бизнес-процессы, то хотя бы просто понимать зачем он делает эту доработку и какую пользу она принесет. Иногда, это также помогает в выборе более правильного решения в том числе.
Тестирование
А вот тут интересно. Потому что хороший тестировщик не будет ориентироваться только на ТЗ - он еще просмотрит BRD, БТ - сверит то что там написано с тем, что написано в ТЗ, потенциально выявит недостаток требований или их некорректность (было такое на практике) и только потом уже приступит непосредственно к тестированию.
Но это прям должен быть очень хороший тестировщик, с большим опытом в целом и особенно на проекте в частности, и, что самое главное, с желанием это всё делать а не просто жмакать на кнопочки в интерфейсе и postman'е.
Соответственно - чем глубже проработка задачи по всем уровням ее проектирования, тем лучше для тестировщика и конечного результата в целом.
Заключение
Конечно, весь этот путь возможен (и нужен) только для больших команд, где есть отдельно выделенные позиции и только для достаточно комплексных и сложных задач. На обычную мелочь хватает и небольшого бизнес-анализа с полноценным системным анализом.
Если же проект маленький или просто нет позиций PO\БА\АР и вот этого всего многообразия ролей, то вспоминаем что я говорил в самом начале серии постов про системного аналитика - что это человек, который может совместить в себе все эти роли и обязанности, проделать сбор требований, бизнес-анализ, архитектуру и системный анализ самостоятельно и потом выдать удобоваримое, комплексное ТЗ разработчику. И сначала это даже интересно, сильно прогрессируешь в компетенциях, но только сначала)
Можете поделиться в комментариях своим опытом того, какой путь обычно проходит задача до выхода в прод на вашем проекте (херак-херак и в продакшен это тоже путь) и как вам хотелось бы, чтобы это происходило - обсудим.
P.S.: По традиции - буду признателен за вопросы про карьеру\профессию\чему угодно связанному со сферой IT - постараюсь ответить на всё.
P.P.S.: Также веду телеграмм-канал, в котором делюсь разным про профессию и про свой путь в ней. Есть и хардовая информация (асинхронные, синхронные интеграции, примеры ТЗ\шаблонов написания микросервисов), так и более софтовая - см. закрепленный дайджест.