Как работает автоматический перевод речи в текст?
Представьте: сотрудник диктует отчёт в машине — и к его приезду в офис на столе лежит готовый документ. Менеджер переслушивает звонки не вручную, а по ключевым словам в расшифровке. Разговоры на Zoom сразу доступны в виде текста, а иностранные коллеги читают перевод в субтитрах. Всё это — автоматическое распознавание речи, технология, которая незаметно стала частью бизнес-процессов.
Чтобы использовать технологию эффективно, важно понимать, как именно она работает. Какие этапы проходит голос, прежде чем стать текстом? Каковы ограничения таких систем? И самое главное — как бизнес может извлечь из этого выгоду?
Что такое автоматический перевод речи в текст?
Автоматический перевод речи в текст (ASR — Automatic Speech Recognition) — это технология, которая принимает аудиосигнал с речью и преобразует его в письменный текст в режиме реального времени или постфактум. При этом важнейшим параметром является точность распознавания, которая зависит от множества факторов: качества аудиозаписи, языковой модели, наличия шумов и диалектов.
Что происходит в момент, когда пользователь начинает говорить?
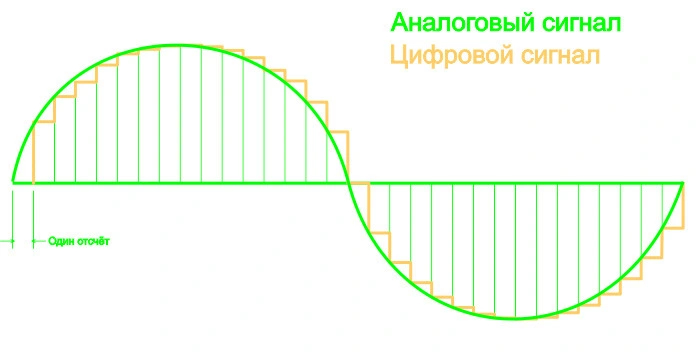
Первый шаг — это захват аудиосигнала. Система записывает звук и делит его на миллисекундные отрезки (обычно 10–25 мс). На этом этапе важна точность микрофона, отсутствие фонового шума и стабильное соединение, если транскрипция происходит на сервере.
Система может работать в реальном времени или постфактум. В первом случае (например, в Zoom или Microsoft Teams) возможна моментальная реакция, во втором — запись и анализ переговоров, звонков, вебинаров.
Как звуковые волны превращаются в слова?
После оцифровки аудиосигнал подвергается преобразованию Фурье, чтобы выделить спектр частот. Из звука извлекаются акустические признаки — мел-кепстральные коэффициенты (MFCC), которые представляют, условно говоря, "отпечаток" каждого звука.
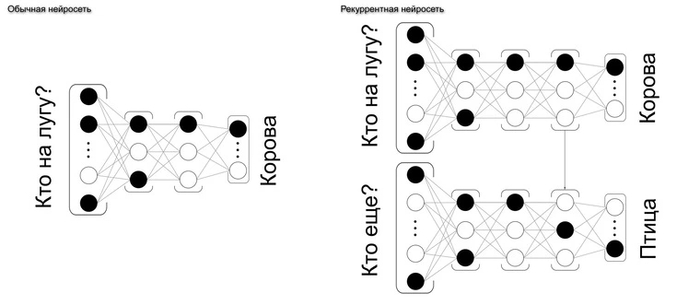
Алгоритмы машинного обучения, чаще всего основанные на рекуррентных нейронных сетях (RNN) или трансформерах, сопоставляют этот отпечаток с базой фонем и слов.
Система распознаёт речь по вероятностной модели. Например, если услышано «пере…», модель может с равной вероятностью продолжить как «перевод» или «перемотка». Здесь вступают в игру языковые модели (LM), обученные на больших корпусах текстов, — они выбирают наиболее вероятную последовательность слов. Комбинирование акустической модели (AM) и языковой модели (LM) в архитектуре ASR (Automatic Speech Recognition) позволяет уточнять гипотезы.
После первичного распознавания может применяться дополнительная обработка: исправление ошибок, разметка пунктуации, разделение на предложения.
Какие технологии и алгоритмы лежат в основе?
Основу современных систем распознавания речи составляют глубокие нейронные сети и языковые модели. Раньше широко применялись скрытые марковские модели (HMM), но сейчас они уступили место гибридным архитектурам с глубоким обучением, таким как:
CTC (Connectionist Temporal Classification) — позволяет выравнивать аудиофреймы и символы без необходимости предварительной разметки;
Seq2Seq с вниманием (Attention) — трансформеры, которые эффективнее работают с длинными последовательностями и контекстом;
End-to-End модели — объединяют акустическую и языковую модели в одном обучаемом модуле, что упрощает архитектуру и улучшает производительность.
Почему точность распознавания варьируется?
Точность зависит от:
Качества записи: помехи, реверберация, посторонние шумы снижают качество;
Акцента и произношения: разные диалекты, скорость речи и фонетические особенности усложняют задачу;
Словаря и контекста: чем шире словарь и лучше контекстуальные модели, тем точнее распознавание;
Обучающих данных: чем больше и разнообразнее данные для обучения, тем выше точность.
Проблема акцентов решается обучением модели на аудиокорпусах с вариативной фонетикой. Фоновый шум обрабатывается с помощью алгоритмов шумоподавления и звуковой сегментации. Сложнее всего — с распознаванием нескольких говорящих: для этого применяют диаризацию речи (Speaker Diarization), которая сегментирует аудио по "речевым отпечаткам" каждого участника.
Лучшие системы обучаются на тысячах часов аудио, с реальными голосами и различными сценариями. Однако 100% точности не существует.
При уровне точности 90–95% автоматизация даёт реальную экономию — освобождает людей от рутины, ускоряет документооборот и снижает потери информации.
Какие данные нужны для обучения систем?
Чтобы обучить систему ASR, необходимы параллельные корпуса: аудио + транскрипция. Обычно это тысячи часов речи. В идеале — с маркировкой акцентов, возрастов, половой принадлежности, шумов, контекста. В корпоративной среде полезны отраслевые корпуса, например, записи переговоров или техподдержки.
Mozilla Common Voice — крупнейшая платформа открытых речевых данных. Используется при обучении систем, в том числе внутри проектов вроде ESPnet, Nemo и Coqui STT.
Некоторые компании на рынке, например, Lingvanex, предлагают доступные варианты кастомизации, т.е. могут дообучить модель на ваших данных для вашей сферы деятельности.
Какую выгоду получают компании от внедрения таких решений?
Пять сценариев, где распознавание речи даёт ROI:
Автоматизация документооборота — диктуешь текст, получаешь форматированный документ.
Запись и анализ встреч — протоколы совещаний формируются автоматически, с возможностью поиска по фразам.
Поддержка клиентов — колл-центры получают транскрипты разговоров, легко выявляют тренды, эмоции, проблемы.
Международные команды — синхронный голосовой перевод в реальном времени облегчает работу на летучках и звонках.
Субтитры и доступность — YouTube, курсы, инструкции сопровождаются субтитрами без ручной расшифровки.
Вывод: когда пора внедрять?
Если бизнес работает с большим количеством устной информации, клиентскими звонками, международными командами или продуктами, где голос — часть интерфейса, откладывать не имеет смысла.
Время от внедрения до первых эффектов — от 2 до 6 недель. Вложения окупаются за счет снижения операционных затрат, роста качества сервиса и уменьшения рисков потери информации.
Начните с малого: возьмите один типовой процесс — например, совещания — и протестируйте автоматическую транскрипцию. Через месяц вы увидите, как меняется скорость доступа к информации и снижается нагрузка на сотрудников.
Автоматический перевод речи в текст — не технология ради технологии, а конкретный инструмент роста эффективности. Компании, которые уже встроили его в процессы, сокращают время работы с контентом, автоматизируют рутину и усиливают доступность данных для всей команды.