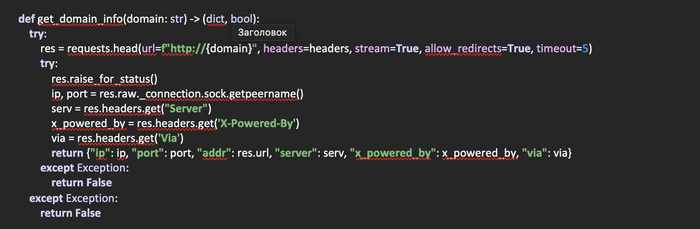
Получение закладок из chromium-based браузеров с помощью Python
Почти все браузеры, основанные на chromium, хранят закладки похожим образом. Меняются только директории, в которые эти браузеры установлены. Исключением является только Mozilla Firefox. При этом закладки хранятся в открытом виде, так что, любой желающий может получить к ним доступ. Не сказать, чтобы это была супер секретная информация. Но все же, стоило бы продумать этот момент. В данной статье мы рассмотрим код, который в автоматизированном режиме получает все закладки из распространенных браузеров с помощью Python.

Поиск установленных браузеров
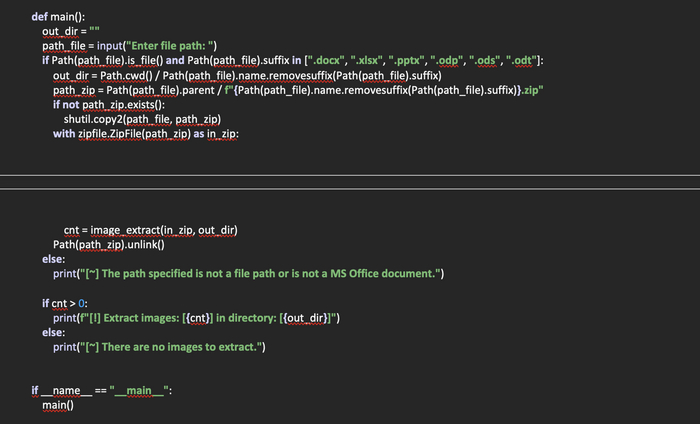
Создадим файл browser_check.py. В нем, напишем код, который будет производить поиск браузеров по пути указанному в одном из словарей.
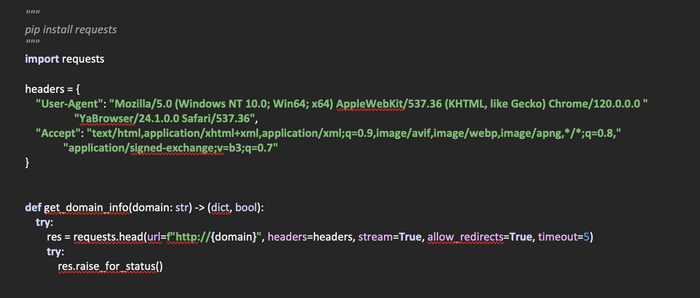
Импортируем необходимые библиотеки для работы скрипта и определим список, в который будем помещать словари с найденными браузерами:

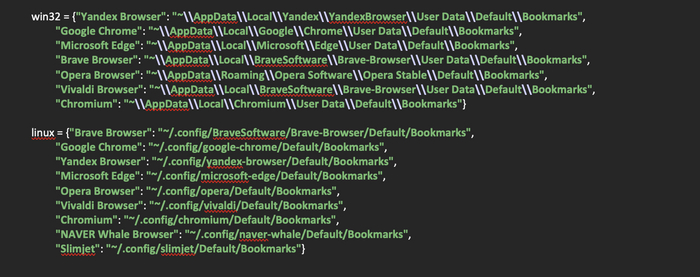
Следующим шагом будет создание двух словарей, в которые поместим пути к распространенным браузерам на операционных системах Windows и Linux, так как поиск браузеров будет производиться по путям, которые специфичны для каждой из операционных систем.
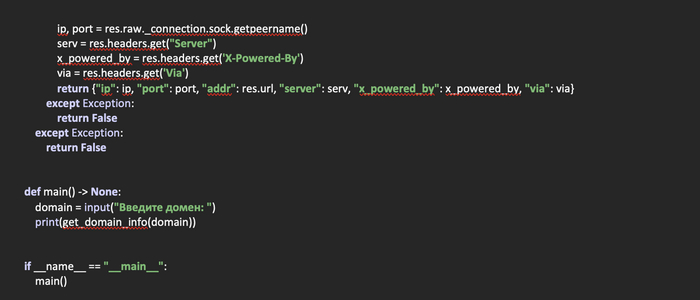
Создадим функцию browser_find(platform: dict) -> None, которая на входе будет получать словарь с путями к закладкам браузеров и проверять их существование. Если путь существует, в объявленный ранее список browser будет добавляться словарь с названием браузера и путем к его закладкам.

Следует обратить внимание на тот факт, что пути к закладкам браузеров указаны при установке их в директории по умолчанию. Если же пользователь поменял расположение директории с браузером, то он найден не будет.
Двигаемся далее и создадим функцию main, в которой будем определять платформу, на которой запущен скрипт. В принципе, если у вас MacOS, то нужно добавить еще один словарь с путями и условие, в котором определяется ваша система. Но, в данном случае детектируются только две операционные системы: Windows и Linux.
В зависимости от того, какая из систем установлена на компьютере с запущенным скриптом, забираем нужный словарь с путями к закладкам и передаем его в функцию browser_find, которую напишем в отдельном файле.
После этого проверяем, есть ли что-то в списке с браузерами. Если список пуст, выводим сообщение для пользователя, что браузеры не найдены. Если же список не пуст, итерируемся по нему в цикле, забираем словари и получаем название браузера, которое содержится в переменной key и путь к закладкам, содержащийся в переменной value.

Передаем полученное значение в функцию по парсингу json. На самом деле, файл с закладками, это json-файл с достаточно большой структурой вложенности.
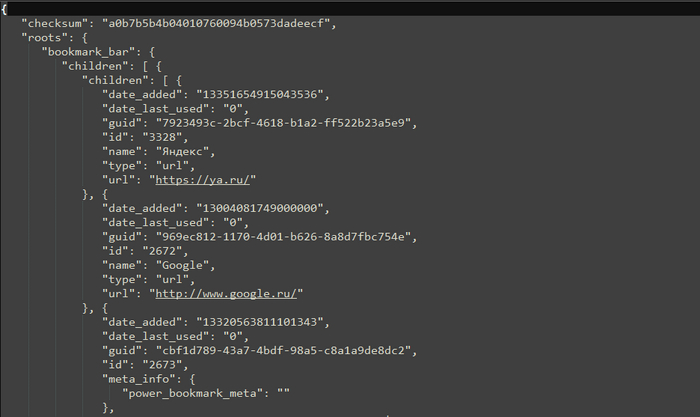
Часть структуры файла закладок
В зависимости от того, что вернет функция парсинга, а возвращает она или список со словарями, в которых содержаться полученные значения или False, двигаемся дальше. Если мы получаем список, то открываем файл с названием браузера на запись. Обратите внимание на то, что в данном случае файл открыт в режиме дозаписи, о чем свидетельствует параметр «a». Затем итерируемся по полученному списку, забираем из словарейОбратите внимание на ветку «roots», в которой и находятся все закладки. Так как закладки в браузере, это не просто последовательный набор названий и ссылок, то их группировка происходит по директориям создаваемым пользователем. Данные директории имеют название «children» и имеют тип «folder». Также, к примеру, на Панели закладок могут быть как директории с закладками, так и просто закладки для быстрого доступа. Тип закладок без папок «url».
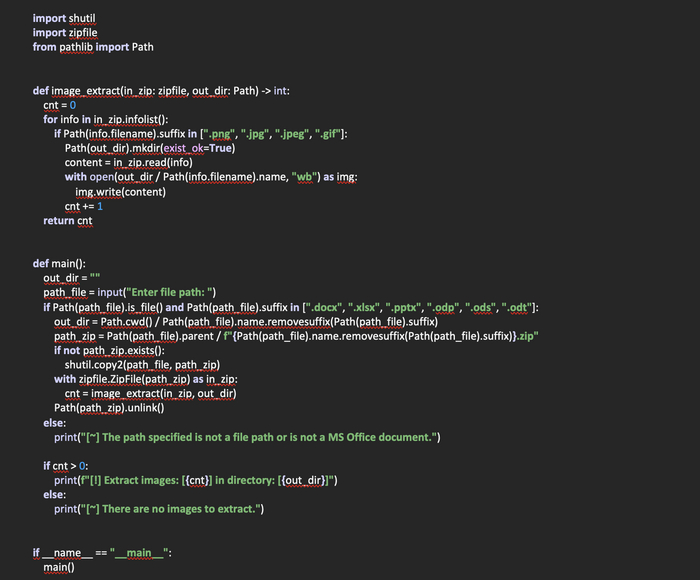
Создадим файл bookmarks_find.py и приступим к написанию кода. Для начала импортируем библиотеки, которые понадобятся в данном скрипте.
import json
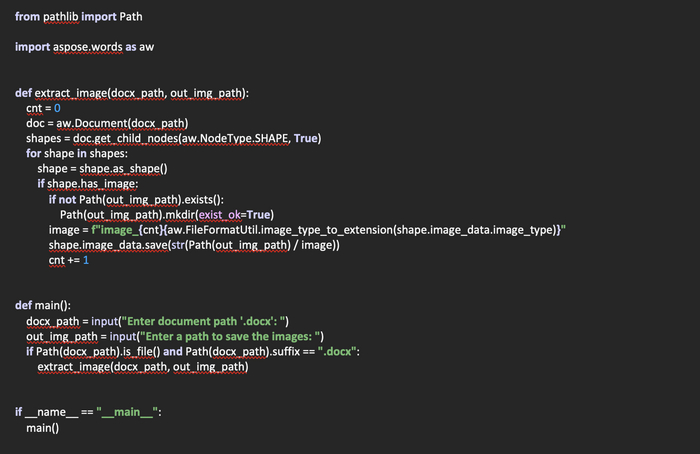
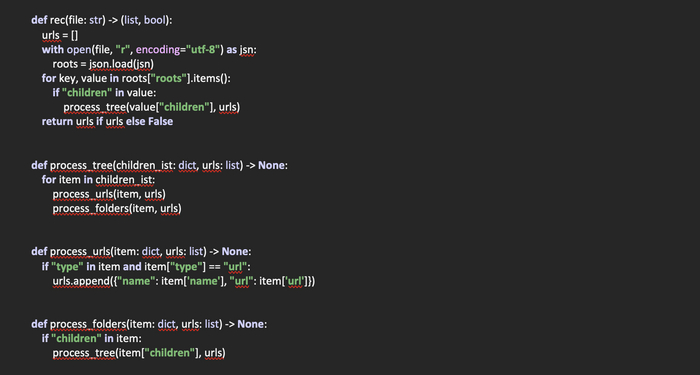
Создадим функцию rec(file: str) -> (list, bool), в которую передается путь к закладкам браузера. Возвращает же данная функция список со словарями, в которых содержится имя и url закладки. В случае же, если закладки найти не удалось, возвращается False.
Объявляем список urls, в который будем помещать найденные закладки в виде словарей. Откроем файл с закладками для чтения, поместим его содержимое в переменную roots.
Так как значение данной переменной будет являться словарем, проитерируемся по нему в цикле, указав ветку «roots» в качестве стартовой. Получим ключ и значение и проверим, есть ли в нем название «children». Если да, передаем полученную ветку в функцию process_tree, которую мы создадим чуть позже для обработки. Также передаем в эту функцию список urls. По сути, при передаче списка, если вспомнить его свойства, мы передаем указатель на оригинальный список, так как его копирования в данном случае не происходит. А значит, при его изменении в других функциях измениться и оригинальный словарь.

После того, как завершим итерацию по файлу, проверяем, пуст или нет список. Если список не пуст, возвращаем его из функции. Если пуст - возвращаем False.
Теперь создадим функцию process_tree(children_ist: dict, urls: list) -> None, которая получает на входе словарь из полученной директории и указатель на список, в котором будут храниться найденные ссылки в виде словарей.

Здесь все просто. Данная функция как переходник, в котором мы итерируемся по полученному словарю и передаем полученные значения в следующие функции для обработки.
Создадим функцию process_urls(item: dict, urls: list) -> None, которая на входе получает словарь со значениями и ссылку на список. У данной функции предназначение – выявить ссылки в переданном словаре. Для этого проверяем, есть ли в переданном словаре ключ «type» и является ли его значение «url». Если да, забираем название ссылки и саму ссылку и добавляем в виде словаря в список urls.

И еще одна функция, которая будет необходима для проверки, не является ли полученный словарь директорией со ссылками «children». Создадим функцию process_folders(item: dict, urls: list) -> None, которая на входе получает словарь со значениями и ссылку на список.
Здесь все тоже просто, проверяем, есть или нет «children» в переданном словаре. Если есть, передаем его рекурсивно в функцию process_tree для дальнейшей обработки.

Полный код скрипта:
import json
На этом вроде бы все. Основные скрипты и функции написаны, осталось только проверить, как это будет работать.
Открываем терминал и запускаем скрипт:
Если у вас Windows:
python browser_check.py
Если Linux:
python3 browser_check.py
В процессе работы скрипт выведет несколько сообщений: о том, сколько было найдено браузеров, для какого из браузеров найдены закладки и для какого количества из найденных закладки сохранены.
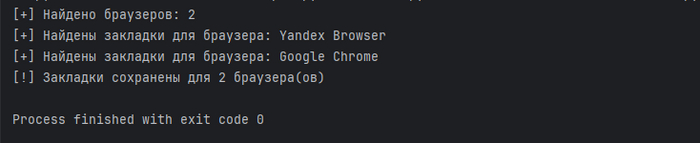
Сообщения в терминале
Если скрипт найдет браузеры в системе, в директории скрипта будут созданы файлы с названиями найденных браузеров, в которых содержатся закладки.
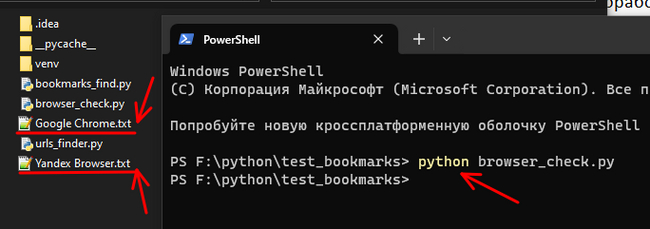
Файлы с найденными закладками
Как видно на скриншоте, у меня установлено два браузера. Давайте откроем один из файлов и посмотрим на часть его содержимого.
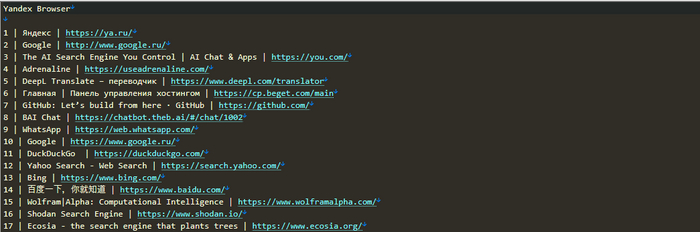
Содержимое файла с найденными закладками
Как видим, закладки найдены. За годы работы в данном браузере их накопилось чуть более 3000. Конечно же, показывать все я не буду, потому, только самое начало, для того, чтобы убедиться, что скрипт работает.
Скрипт работает как на Windows, так и на Linux. Вот скрин с работой скрипта в Fedora Workstation, в которой браузеры установлены по умолчанию, с помощью пакетов.
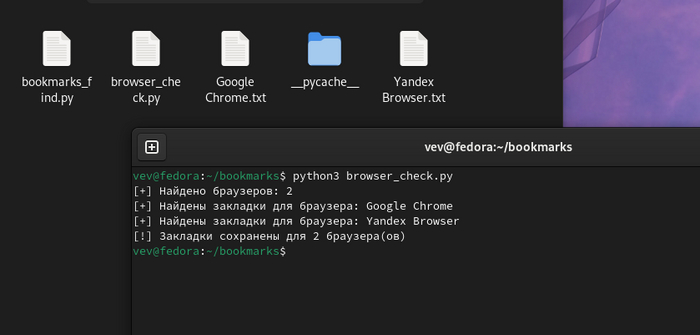
Работа скрипта в Fedora Workstation
Подведем итоги:
В данной статье мы научились рекурсивно парсить файл json, узнали, каким способом можно определить операционную систему, установленную на компьютере, а также сохранять данные из json в текстовый файл.
В перспективе, применений данному скрипту можно найти достаточно много. Все зависит только от вашей фантазии.
А на этом все. Спасибо за внимание.