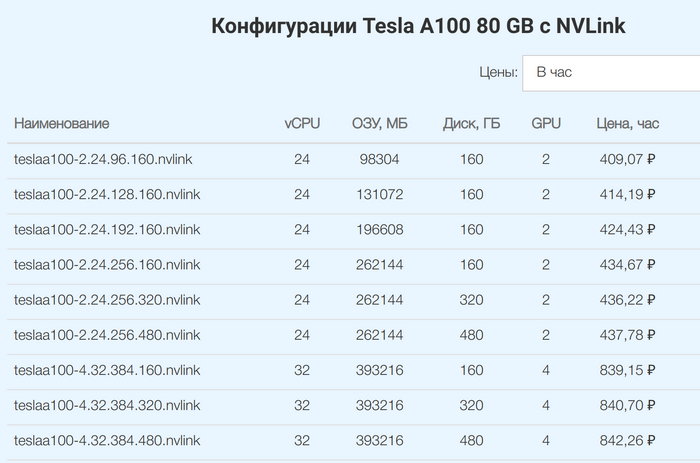
Квантизация позволяет запускать Llama 3.2 на мобилках
Квантизация помогла портировать последнюю версию LLM Llama 3.2 на мобильные платформы - iOS и Android. Для этого разработчики выпустили квантованные версии Llama 3.2 1B и 3B, которые при тестах на ARM-процессорах показали высокую скорость инференса, по сравнению с несжатыми весами в формате BF16.
Как вообще получилось, что Llama работает на мобильных процессорах, ведь для ее запуска нужен определенный программный стек, чаще всего библиотека Pytorch и CUDA на операционной системе Linux?
Дело в том, что Meta* (признана в России экстремистской организацией) используют ExecuTorch - это фреймворк, который является частью Pytorch-платформы и предназначен для запуска Pytorch-программ на мобильных девайсах. ExecuTorch поддерживается фреймворком Llama Stack для запуска моделей Llama, а именно легковесных Llama 3.2 1B и 3B, на iOS и Android. Для разработки мобильных приложений под эти платформы Llama Stack предоставляет клиентский SDK на Swift для iOS и Kotlin для Android, оба написаны под ExecuTorch бэкенд.
Какого именно уровня производительности удалось добиться новым квантованным моделям Llama?
В среднем это ускорение инференса от двух до четырех раз по сравнению с весами в формате BF16, при сохранении практически сопоставимого качества. Уменьшение размера модели на 56% - что важно для мобильного приложения, чтобы меньше места на телефоне занимало - и уменьшение объема потребляемой памяти на 41% процент. Все это согласно результатам бенчмарков, приведенных на сайте Llama.
Сразу стоит отметить важную деталь: речь идет не об обычной post-training квантизации, когда вы берете веса в FP16 и квантуете в GGUF или GPTQ. Хотя такие веса, безусловно, имеют практическое применение для множества задач, они страдают падением качества, это хорошо заметно на бенчмарках ниже.
Традиционный путь - QLoRA
Для квантизации применили два разных подхода, во-первых, QLoRA - знакомую методику, когда после квантизации матриц весов в 4bit к ним применяется low-rank-adaptation. Этот подход по-прежнему является очень эффективным и показал лучшие результаты на бенчмарках.
QLoRA достаточно легко выполнить самому, но для этого нужен подходящий графический процессор, базовая модель с весами в 16 битном разрешении и датасет. То есть веса модели сжимают в 4bit и файнтюнят на данных с применением LoRA, low-rank adaptation. Иными словами, обучаются только параметры LoRA-адаптеров - матриц более низкого порядка. Такой умный файнтюнинг дает то, что вы увидите ниже на приведенных бенчмарках - QLoRA-модель по качеству очень близка к весам в оригинальном разрешении.
Тем не менее, для этого метода все-таки необходима видеокарта - она должна иметь достаточно памяти, чтобы вместить веса в четырехбитном формате. Я арендую GPU в облаке для файнтюнинга с использованием QLoRA, и чаще всего я работаю с 8B моделями, так что мощности не такие уж огромные.
Усовершенствованная post-training квантизация: SpinQuant
Другой подход, альтернативный QLoRA - SpinQuant, который позволяет квантовать модели после обучения. То есть для выполнения квантизации вам не нужен датасет и видеокарты для обучения, в отличие от QLoRA. Вернее, видеокарта нужна, но по-настоящему обучать не придется. SpinQuant предполагает две манипуляции с весами модели - ротацию матриц активации и весов и обычную PTQ-квантизацию.
Проблема квантизации - это значения-аутлаеры, которые сильно выбиваются из среднего диапазона датасета. Они могут быть причиной потери точности предсказания после квантизации. Для борьбы с ними применяют различные способы уменьшения разброса значений в матрице X - таких как нормализация или перемножение X на матрицу ротации. Подробнее об этом читайте в статье по SpinQuant.
Есть открытый репозиторий на Python и Pytorch, который предлагает реализацию SpinQuant, совместимую с ExecuTorch и Llama Stack. С его помощью удобно квантовать веса под разные платформы, включая мобильные.
Вот результаты подробного сравнения моделей с разными типами квантизации. Представлены метрики, полученные на несжатых весах в BF16, на весах после обычной post-training квантизации - здесь заметно падение качества - и на весах после SpinQuant и QLoRA. Последние, особенно QLoRA, на бенчмарках показывают результаты очень близко к оригинальной модели.
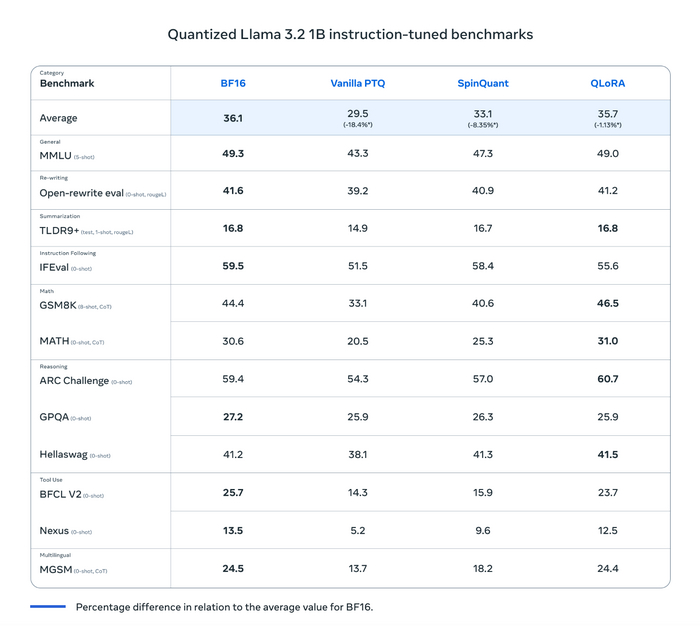
У SpinQuant и QLoRA примерно одинаковая скорость инференса, хотя QLoRA потребляет чуть больше памяти. Скорость более чем в два раза выше, чем у несжатых BF-16 весов.

Квантизация дает нам кроссплатформенность и делает большие языковые модели доступнее для разработчиков. Допустим, кто-то не смотрел в сторону Llama и других моделей, потому что они не работали на привычной для него платформе. Не все любят писать программы для запуска в облачной среде.
Но теперь даже мобильные разработчики получили инструменты, которые позволят им начать исследовать возможности Generative AI.