Как я разрабатываю агентские ИИ системы для извлечения признаков (feature-extraction) из мультимодальных данных
Извлечение признаков (feature extraction) из текстов — ключевой шаг при анализе документов: он является основной практической частью таких задач по обработке данных, как классификация, тематическое моделирование, NER, QA. Если раньше почти что для каждой из таких задач, и в особенности для разных модальностей данных использовались специализированные архитектуры нейронных сетей, то сейчас подобные системы обычно строятся вокруг LLM/VLM. Однако и современные модели на практике настраиваются под конкретные задачи через fine‑tuning или distillation, в связке с retrieval (RAG) и агентскими архитектурами.
В этой статье я рассматриваю свой опыт проектирования и разработки агентов для выполнения feature-extraction. При наличии мультимодальных данных с разнородной структурой - тексты, PDF, изображения - мне приходится извлекать нужные пользователю фрагменты информации. Для этого я перебрал различные подходы - в зависимости от сложности задачи - и теперь пора сравнить их эффективность и отметить сложности реализации.
Традиционный подход: LLM + RAG, которого уже не достаточно
Retrieval‑Augmented Generation (RAG) — тандем LLM и векторных баз для поиска релевантных фрагментов, вставляемых в контекст перед генерацией, который обрел популярность в последние год-полтора благодаря нескольким безусловным преимуществам.
Этот подход позволяет использовать модели общего назначения на узкоспециализированных доменах без полного дообучения. Он и сейчас является самым надежным и дешевым способом снизить галлюцинации, даёт ссылки на документы и улучшает точность ответа. RAG используется в цепочке следующих логических шагов, через которые проходят данные в системе: векторизация → recall → prompt → LLM → извлечение структурированных данных.
Теперь о минусах RAG. Описанная методика только дополняет контекст модели релевантными данными, но не повышает способность самой LLM к извлечению нужных признаков. Эта способность зависит от того, каким задачам и на каких данных модель была обучена. К тому же RAG добавляет несколько архитектурных и прикладных сложностей - пайплайн с векторной базой, embedding, поиск по индексу, чанкинг данных, который может быть нетривиальным процессом с применением различных методик (таких как Semantic Chunking).
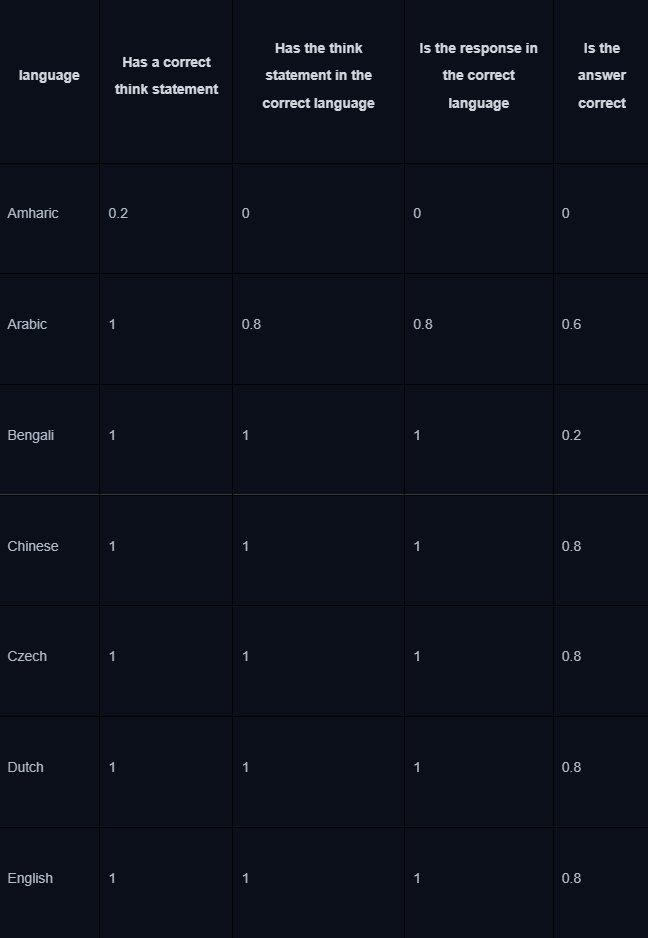
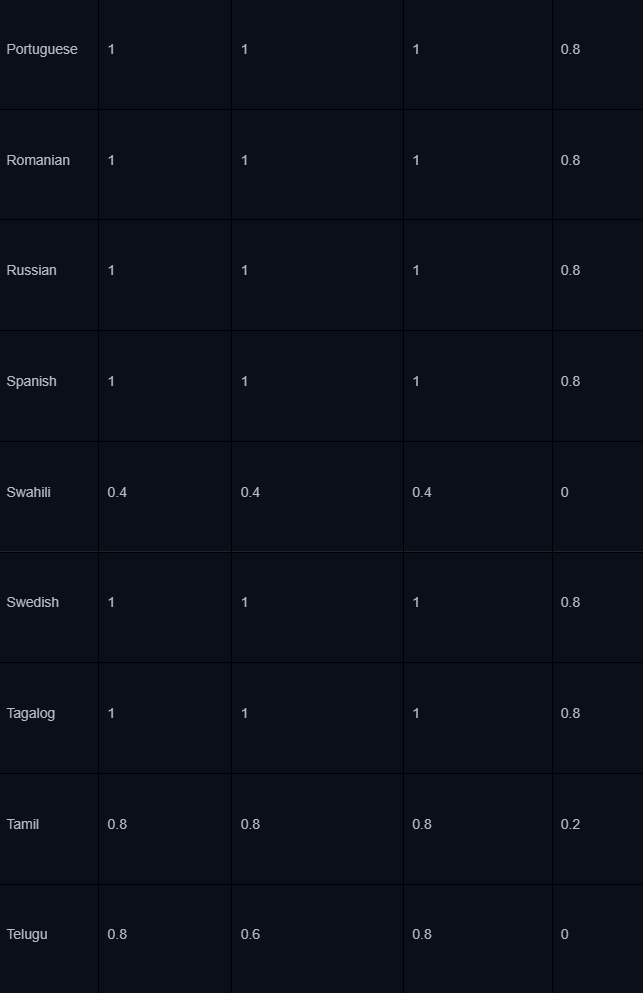
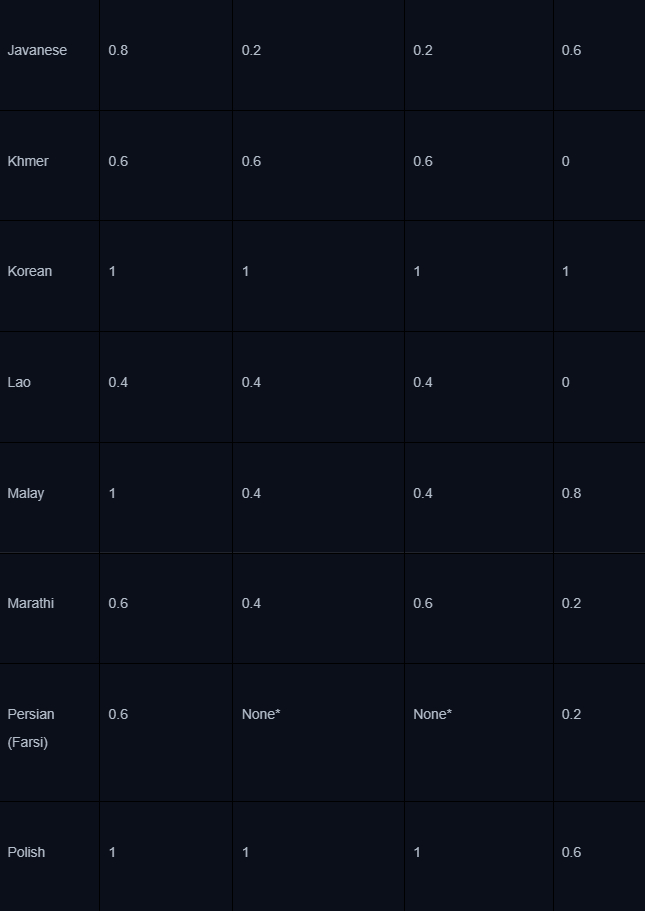
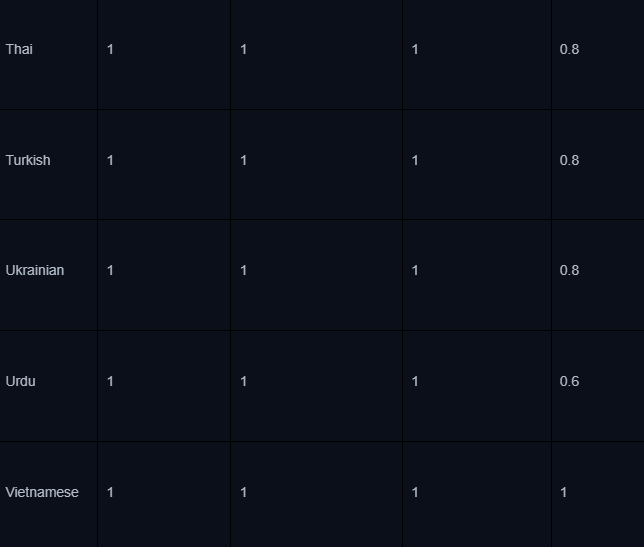
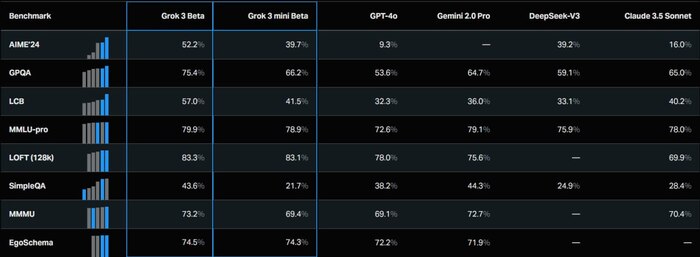
Сейчас контекстное окно модели позволяет вместить намного больше данных, чем раньше - взять хотя бы 1 млн токенов у Llama 4, так что необходимость в чанкинге и самом RAG уже не настолько острая. Есть, конечно, проблема понимания длинного контекста. Важно понимать, что при решении практических задач точность LLM может падать пропорционально длине контекста - на эту тему есть интересный бенчмарк:
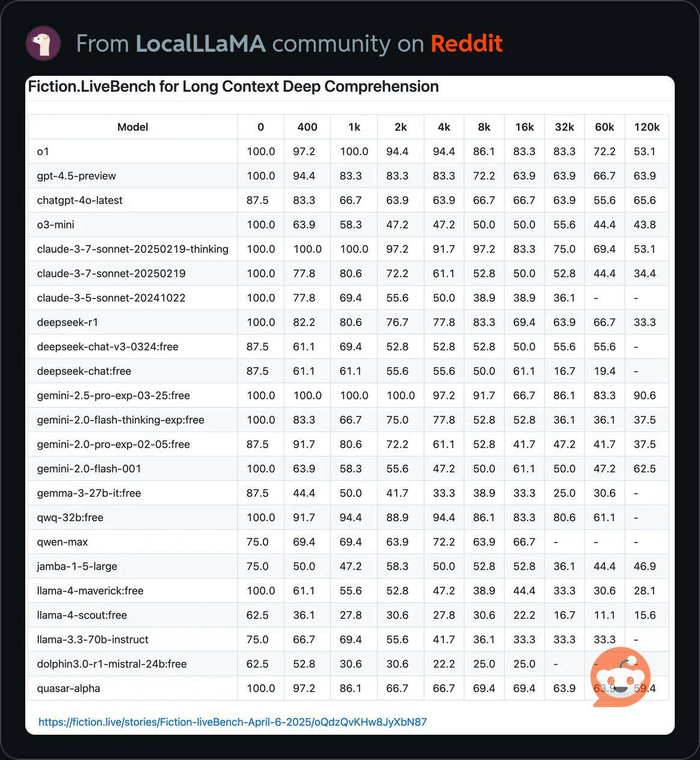
Разные модели имеют разные показатели long context understanding, как видно из таблицы выше. Их точность для определенных задач можно увеличить двумя способами - SFT-файнтюнингом на размеченных данных и дистилляцией - передачей знаний от более сильной модели.
Fine‑tuning: точечное улучшение LLM
Файнтюнинг изначально был менее доступен, чем RAG - во-первых, он требует понимания того, как работает оптимизация весов большой языковой модели-трансформера (если мы не говорим про файнтюнинг каких-то других архитектур нейросетей). Во-вторых, он требует набора данных (как правило, размеченных, если мы говорим про Supervised Fine-Tuning), и в третьих, он требует вычислительных мощностей, таких как GPU-кластер.
В результате файнтюнинг позволяет настроить веса модели под конкретные инструкции, задачи, формат данных, что значительно повышает точность модели в определенном специализированном домене.
На своем опыте я сделал следующий вывод: файнтюнинг необходим для разработки агентов, особенно в области feature-extraction задач, это очень эффективная практика, которая должна быть взята на вооружение разработчиками, так как она закрывает недостатки RAG и служит необходимым компонентом прикладных ИИ систем. Перечисленные выше трудности файнтюнинга тоже постепенно решаются - во-первых, облачные провайдеры делают доступными вычислительные мощности. В моих статьях и видео достаточно гайдов по использованию облака для файнтюнинга. Чтобы экономить на GPU, по-прежнему остается актуальной методика Low-Rank Adaptation (LoRA), хотя во многих случаях и полный файнтюнинг, который модифицирует веса модели полностью, тоже возможен и оправдан. Ведь для узко специализированной задачи может быть достаточно обучить модель на совсем небольшом наборе данных - 100-500 примеров.
Динамическая квантизация в сочетании с LoRA (QLoRA) позволяет еще сильнее сократить расход видеопамяти и время обучения модели.
В целом SFT-файнтюнинг можно разделить на следующие шаги: подготовка датасета → формирование train и validation наборов → обучение → оценка. В моем последнем видео я "начал с конца" и разобрал прикладные аспекты оценки (evaluation) при разработке агентских систем. Лишь недавно я обратил внимание на библиотеки для evaluation, такие как openevals в экосистеме Langchain/Langsmith, о которых в знал и раньше, но обходился простым скриптингом. Для тех, кто только начинает знакомство с evals, будет полезен мой ноутбук с экспериментами на Langchain/Langsmith и openevals.
При подготовке данных для feature extraction важно выбрать итоговый формат данных, который будет понятен и человеку, и LLM. При небольшом объеме данных самое важное - качественные примеры ответов (output), которые готовятся обычно человеком, вручную. Это особенно актуально для специализированных случаев feature-extraction - например, если вы разрабатываете систему, которая будет читать технические спецификации изделий, товарные коды и тому подобные типы данных. Для составления такого датасета придется привлекать человека с профессиональными знаниями в соответствующем домене. А для LLM чем проще выходной формат данных, тем меньше вероятность галлюцинаций. Поэтому я руководствуюсь тремя принципами -
1. Не усложнять выходной формат данных применением, например, JSON или XML - простого текста в большинстве случаев достаточно;
2. Выполнять feature-extraction из минимальной единицы входных данных за одну генерацию. Это может быть одна PDF-страница, изображение, параграф текста;
3. Использовать Chain-of-Thoughts для валидации процесса извлечения.
Само обучение, как ни странно, вызывает меньше всего проблем - используйте готовые средства обучения библиотеки transformers или API OpenAI, контролируйте качество чекпоинтов, своевременно используя evaluation, и следите за оверфиттингом.
Distillation: перенос знания
Distillation — это обучение компактных или более слабых моделей на основе поведения более сильной LLM‑«учителя». Это еще один способ повысить качество модели, часто менее затратный, чем SFT-файнтюнинг - достаточно просто сгенерировать датасет с помощью модели-учителя, без участия человека.
Отличным практическим примером перечисленных методик может послужить исследование технологического института Джорджии, опубликованное в январе 2025.
Авторами была реализована следующая архитектура:
DistilBERT + fine‑tuning на 10 000 документов → компактная модель с эффективным временем обучения (4–9 ч на ПК) с 97% качества модели-родителя. Пайплайн извлечения признаков включал следующие шаги:
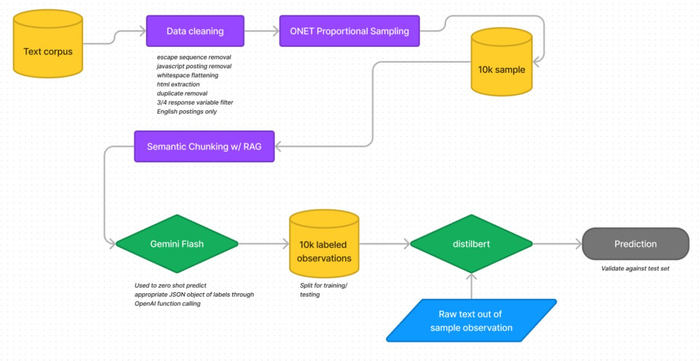
Сэмплинг 10k примеров из тестового корпуса (объявления вакансий) с целью извлечения признаков.
Разбивка на чанки с применением Semantic Chunking
Генерация ground‑truth с помощью LLM (Gemini).
Файнтюнинг DistilBERT - небольшой модели с архитектурой раннего трансформера, которая получена путем дистилляции знаний модели BERT. Дистилляция позволяет сохранить 97% процентов качества, при размере на 40% меньше, чем у исходной модели BERT
Prediction - извлечение признаков.
Логично предположить, что рассмотренные в этой статье методики извлечения признаков из документов можно и нужно комбинировать.
RAG — поиск релевантных фрагментов, Fine‑tuning для улучшения и стабилизации ответов модели, и Distillation в эффективной агентской системе дополняется промпт-инжинирингом и CoT, Chain‑of‑thoughts, для самовалидации системой извлеченной информации и ее автоматического итеративного приближения к ожидаемому результату.