


АйТи на удаленке
50 постов
50 постов
2 поста
5 постов
1 пост
1 пост
2 поста
3 поста

3 поста


Вот учим людей кодить на Python, чтобы стать мега разработчиком, работать удаленно и пить вкусный чаек с печеньками, обдумывая очередную задачку на кодинг ☕️☕️☕️ Ух как приятно все таки, чего нить эдакое закодить, и радоваться когда оно заработает 🎉🎉🎉

Но иногда забываемся, думаю что "очевидные" не относящиеся к изучаемому материалу темы давать не нужно. Но обучать людей кодить, и кодить это две разные штуки 👆

Поэтому если использовал любую новую функцию или библиотеку - будь любезен, объясни как оно работает 👆 Справедливо, исправилиcь 😎😎😎

Детали по нашему комьюнити в профиле.

Надо помнить - в Python некоторые вещи могут зависеть от настроек инстанса интерпретатора.
Например вот такой случай, "print(a, b)" может выдавать разный вывод на Stepik и на вашем локальном Python. И не смотря на то, что при сравнении результата кода с expected здесь используется strip(), который должен срезать все пробелы спереди и сзади, вот в этом конкретном случае сравнение идет целиком всех букв сразу, и будет разница и fail при "print(a) print(b)" vs "print(a, b)", поэтому ВАЖНО использовать конструкции, которые не зависят от настроек интерпретатора, например "print(a + b)", вместо "print(a, b)".
Как понять что зависит, а что нет? 🤨 С этим сложнее - например достаточно знать синтаксис языка C, и его аналоги переиспользовать даже в Python, тогда все будет ok.

Тем не менее незнание С не особождает от ответственности 🧐 Если столкнулись с ситуацией когда визуально все ok, а оно говорит не совпадает 🤷 Надо прокачивать другой важный скилл разработчика - debugging и root cause analysis. Надо пойти в "любой" online diff checker и сравнить два текста, и увидеть что разница все таки есть. Кстати diff чекеру тоже доверять на 100% не надо, вот как в этом случае он показывает, что посимвольно разницы нет (снизу должен был показать красным добавленые пробелы), но кол-во символов то разное👆Вот тут мы все и поняли 😀
Учим Python каждый день по чуть-чуть, ссылка в профиле 🔥 🔥 🔥
Вот иду - красивая машинка дорожного патруля ЦОДД стоит. Кому-то помогают. Мне один раз сильно помогли, у меня каршеринг отключился прямо по среди перекрестка (машину система просто вырубила удалено). Дык сразу откуда не возьмись, появилась красивая машинка ЦОДД, и два чувака в желтых жилетах, оттолкали машину метров 50 на стоянку, где я ее в приложении и сдал. Все это произошло быстрее, чем я дозвонился до саппорта каршэринга. А так вообще не знал че делать, машина не моя, капот не открыть ... И цвет выбрали очень удачно, когда вижу их машины возникает чувство спокойствия и безопасности, которое не возникает, когда видишь машину ГИБДД. Хорошо, что другой цвет выбрали ;-)


Образование – важная часть жизни, и подходы к нему могут кардинально различаться. Давайте рассмотрим классическую систему образования и самообучение на необычном примере – обучении пить чай.
Классическая система образования: теория без практики
В классической системе обучения процесс структурирован и разделён на этапы. Учебный план состоит из последовательного изучения всех аспектов. Например:
Что такое ложка?
На протяжении двух часов изучаются её форма, история изобретения, виды материалов. На экзамене нужно назвать 5 типов ложек и их основные отличия.
Что такое кружка?
Ещё три часа посвящаются описанию конструкции кружки, материалов, из которых она изготавливается, а также её роли в культуре и быту.
Как нагревается вода?
Ещё несколько часов обсуждаются различные способы кипячения воды, устройство чайника, безопасность обращения с кипятком.
И так далее. Через два года такой учёбы студент узнаёт массу интересных фактов о чае, кружках, чайниках и ложках, но… пить чай он, возможно, так и не начнёт. Почему? Потому что практика откладывается на потом, а теория часто бывает избыточной.
Самообучение: учимся на ошибках
В самообучении всё иначе. Человек сразу переходит к делу:
Попытка номер один: наливаем кипяток, обжигаем руку, понимаем, что горячее нужно наливать аккуратнее.
Попытка номер два: насыпаем сахар руками прямо в чашку. Половина пролетает мимо. Учимся искать ложку.
Попытка номер три: пробуем чай и обжигаем губы. Узнаём, что стоит подождать, пока он немного остынет.
Через несколько дней таких ошибок и проб человек уже уверенно пьёт чай три раза в день. Он может не знать научного названия процесса нагревания воды или всех видов ложек, но его цель – пить чай – достигнута.
Результаты: теория против практики
Классическая система:
После двух лет обучения студент знает множество определений, частично забывает изученное и… часто разочаровывается. Он так и не начинает пить чай, потому что считает это сложным и неудобным.
Самообучение:
Человек, который начал пробовать сразу, уже пьёт чай регулярно. Более того, освоив чай, он переходит на кофе. А "классический" ученик теперь спрашивает у него: "Как ты научился пить кофе?"
В ИТ и особенно в программировании, лучше работает второй вариант. Уж счету нет людям которые прошли курсы, и не могут на собесе написать простой кусочек кода, потому что теорию и практику в вакууме им дали, а вот самому нафигачить системку, поднять сервак, написать прикольный код, запилить игру они не умеют :-(
Когда команда с горем пополам научилась попадать с разработкой запланированного внутрь спринта, то встает следующий вопрос - а почему мы все равно не успеваем впихнуть то, что уже было разработано в релиз после спринта?
У нас именно так и получилось. Вначале разработчики не использовали никакой системы при планировании спринта - это было больше похоже на индивидуальное планирование, каждый брал себе столько сколько сможет унести, и конечно результат спринта был достаточно рандомным. Что конечно расстраивало заказчиков, никто не понимал - когда же будет доставка конкретной фичи?
После внедрения poker planning и story points, ситуация с прогнозированием разработки улучшилась значительно. Но заказчики (Product Managers в нашем случае) инстинктивно воспринимали завершение разработки как готовность фичи. Это конечно было ошибочное ожидание, более того, когда PM смотрели на каждую фичу и видели:
Фича A -> 3 Story Points
Фича B -> 8 Story points
То ошибочно думали, что тестирование будет занимать пропорциональное количество времени, то есть например:
Фича A -> 1 день?
Фича B -> 2 дня?
Но в реальности объем тестирования никак не был связан с Dev Effort по разработке конкретной фичи. Все могло быть с точностью до наоборот:
Фича A -> 3 дня
Фича B -> 1 день
Дело в том, что тестирование очень часто находит ошибки в новой фиче, что вызывает еще один цикл исправлений (дополнительный Dev Effort), и еще один цикл тестирования/перетестирования. И чем больше объем тестирования конкретной фичи, тем дольше цикл перетестирования. А чем более сложная фича (не равно емкости Dev Effort), тем больше циклов исправлений и перетестирования ожидается.
Можно предложить укладывать циклы тестирования и перетестирования в изначальный Dev Effort в Story Points, но Capacity команды Тестирования не входит в команду Dev, поэтому так не получится.
Поэтому мы решили попробовать следующий подход. Команда тестирования на стадии прототипирования фичи (до начала разработки), пишет предварительные тесты для покрытия этой фичи, и должна давать отдельную оценку Test Effort, включающую риски по возможным багам, и их переработкой.
Чтобы эту оценку не путать и не складывать с Dev Effort, мы решили сделать ее не цифровой, а символьной, в размерах маек S, M, L, XL.
Мы долго думали, должна ли шкала оценки быть нелинейной (фибоначи например), как Dev Effort в Story Points. И решили, что в этом не необходимости. Дело в том, что заказчик (PM), хочет знать, когда он получит фичу в Прод, и при планировании спринта у него есть выбор, состоящий из Dev Effort и Test Effort, который либо "влазит" в спринт, либо нет. Тогда при планировании сразу понятно, что с большой вероятностью будет доставлена, а что потребует больше одного спринта.
Получилась вот такая схема:
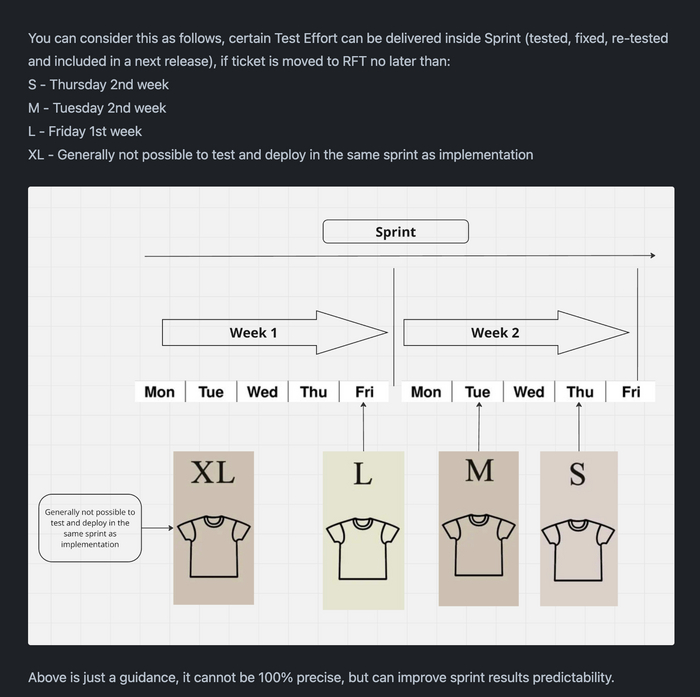
Прогноз усилий по тестированию в размерах маек
То есть, чтобы впихнуть L фичу, надо отдать ее тестировщикам в конце первой недели спринта. Для M, S во вторник, четверг второй недели соотеcтвенно. Для XL зарелизить в рамках одного спринта шансов нет!
А как у Вас с этой проблемой?





