

Нейро Пушка
94 поста
Название: 360 Orbit Camera Motion (Wan2.1 I2V LoRA)
Ссылка на модель: https://civitai.com/models/1620257/360-orbit-camera-motion-wan21-i2v-lora?modelVersionId=1833691
Тип модели: #LoRA
Количество скачиваний: 600+
Дата загрузки: 26 мая 2025
Базовая модель: Wan Video 14B i2v 480p
Триггерные слова: 0rb4it 360 degree orbit
Теги: #concept, #motion, #video, #cinematic, #360, #camera
Описание модели/Комментарий разработчика:
Модель создаёт реалистичное вращение камеры вокруг объекта на 360 градусов. Работает идеально для демонстрации предметов, сцен с движением или сюжетных кадров с кинематографичной подачей.
Поддерживает точный контроль и синхронизацию с анимацией — полезный инструмент для визуального сторителлинга в видеоформате.
Источник: 🤖 НЕЙРО-СКЛАД — всё, что нужно, для твоей нейронки!
Погонял тут Veo 3 от Google – нейронку для видео. Делюсь первыми впечатлениями и советами по промптам!
🤯 Штука крутая, видосы генерит интересные, но не всегда с первого раза получается именно то, что задумал. Так что толковый промпт – реально решает. Вот какие выводы и советы у меня есть для вас.
🤔 На каком языке пишем? RU vs EN?
🇬🇧 English часто стабильнее, особенно для сложных стилей и деталей. ИИ на нем больше учились. Если хотите максимум контроля – это ваш выбор.
🇷🇺 Русский тоже работает, но:
Формулируйте МАКСИМАЛЬНО просто и четко.
Если ИИ "тупит" на русском, попробуйте ключевые термины стиля/техники на английском.
📝 СУПЕР-БАЗА для промпта (чтобы ИИ не гадал):
КТО/ЧТО? (Субъект)
ЧТО ДЕЛАЕТ? (Действие)
ГДЕ & КОГДА? (Контекст)
СТИЛЬ! (Критично!)
КАМЕРА? (Движение, ракурс)
АТМОСФЕРА? (Свет, цвет)
ЗВУК! (SFX, музыка. "Без диалогов" – если речь не нужна).
ГЛАВНЫЙ ЛАЙФХАК: Чем БОЛЬШЕ ДЕТАЛЕЙ в промпте – тем круче и точнее результат!
💡 Пара примеров промптов на английском (как я делал для своих тестов):
1️⃣ Птичка в парике (Bird with wig):
Subject: A small, cute light-blue bird wearing a vibrant, glossy rainbow-colored wig and a sparkling gold star-shaped hair clip.
Context: Clean, minimalist light grey studio background.
Action: The bird slightly ruffles its feathers and tilts its head curiously. The rainbow wig gently sways, and the strands catch the light. The gold star clip emits a subtle twinkle.
Style: Whimsical, charming, highly detailed, photorealistic.
Camera Motion: Very slow, subtle zoom in, maintaining focus on the bird's eye and the star clip.
Ambiance: Bright, playful, magical.
Sound FX: Soft feather rustle, a tiny magical shimmer/twinkle sound, a gentle curious chirp. No dialogue.
2️⃣ Человек-аквариум (Character with water bag head):
Subject: A surreal character whose head is a transparent plastic bag filled with light blue water, seamlessly attached to a body wearing a black t-shirt. A smiley face with 'X' eyes is drawn on the front of the water-bag head. Inside the water-bag head, a small, bright orange goldfish gracefully swims around.
Context: Solid, bright yellow studio background.
Action: The water inside the bag-head gently sloshes and ripples, causing the drawn face to subtly distort. Small air bubbles slowly move within the water. The goldfish swims in smooth circles, its fins gently swaying. The character's shoulders show an almost imperceptible breathing movement.
Style: Surreal, conceptual art, minimalist, unsettling, high contrast.
Camera Motion: Extremely slow, almost imperceptible zoom towards the water-bag head, closely following the movement of the goldfish, or a slight, unnerving drift from side to side.
Ambiance: Odd, intriguing, slightly tense, whimsical.
Sound FX: Soft, muffled sloshing sound of water from within the bag-head, a faint, subtle crinkle of plastic as the bag-head might subtly shift, the almost inaudible sound of water displacement as the goldfish swims. No dialogue.
🚫 ЧТО НЕ НАДО? Если хотите чего-то избежать, так и пишите (на английском будет надежнее): "no people", "not cartoonish style", "avoid red color".
🔄 НЕ СРАБОТАЛО? НЕ БЕДА!
Это нормальная тема с нейронками. Меняйте слова, добавляйте конкретики, пробуйте другие стили. Терпение и эксперименты!
Пару моих экспериментов и то, что получилось, прикрепил к этому посту – зацените!
👀 Хотите сами пощупать Veo 3?
Google сейчас дает возможность потестить через подписку на Gemini. Доступно 10 генераций видео в течение 10 дней, затем лимит обновляется.
🔗 Пробовать тут:
(И да, не забываем про три веселые буквы с входом из Америки)
Источник: 📼 @txt2vid
Собираем презентацию по текстовому запросу и референсам. Manus сам добавит инфу, нужные картинки, видео и даже цитаты из книг.
Это ИМБА для студентов и маркетологов. Не нужно тратить часы и париться с шаблонами.
Результат можно редактировать — просто жмем в нужное место и правим.
Юзаем тут.
Источник: 🎯 НЕЙРО-ПУШКА ● НОВОСТИ И ОБЗОРЫ НЕЙРОСЕТЕЙ
Perplexity выпустили Deep Research 2.0 — Это Deep Research на стероидах, который может создавать и выполнять Python-код.
Теперь в отчетах будут графики, изображения и разные диаграммы. Или даже целый сайт, который сгенерируют на основе собранных данных.
Юзаем — здесь
Источник: 🎯 НЕЙРО-ПУШКА ● НОВОСТИ И ОБЗОРЫ НЕЙРОСЕТЕЙ
Название модели: Bouncing Boobs – Wan 14B
Ссылка на модель: https://civitai.com/models/1343431?modelVersionId=1517164
Тип модели: #LoRA
Количество скачиваний: 25,4 k
Дата загрузки: 11 марта 2025
Базовая модель: Wan Video 14B i2v 720p
Триггерные слова: her breasts are bouncing
Теги: #concept #boobs #bouncing
Описание модели | Комментарий разработчика:
LoRA добавляет реалистичную физику груди в роликах Wan 14B. Достаточно включить модель и использовать триггер-фразу, чтобы персонажи получили убедительное движение тела без артефактов. Автор обучал сетку на коротких фрагментах высокого разрешения, провёл 32 эпохи на RTX 4090 — всего около получаса.
На той же странице доступны упрощённая LoRA-версия для 480p и экспериментальная вариация txt2video — пригодится, если нужен быстрый результат или работа с текстовыми подсказками.
⚠️ NSFW-контент
Источник: 🤖 НЕЙРО-СКЛАД — всё, что нужно, для твоей нейронки!
Пока Veo-3 демонстрирует новый уровень видео генерации, другие площадки не сдают позиции и предлагают улучшенные варианты своих инструментов. Kling выпустил сразу две модели: Standard и Master.
❗️доступно в режиме Image-to-Video , Text-to-Video - в перспективе
Цифры:
— Kling 2.1 Standard (720p) — 20 кредитов за 5 секунд
— Kling 2.1 Pro (1080p) — 35 кредитов за 5 секунд
— Kling 2.1 Master (1080p) — 100 кредитов за 5 секунд
По прежнему дают 166 кредитов в месяц.
Улучшена динамика, точность и логичность следования подсказке.
Обновление выглядит уверенно — особенно для тех, кто уже работает с генерациями и может оценить прогресс на фоне предыдущих версий. будем следить за готовыми результатами пользователей.
Вход здесь
Источник: 📼 @txt2vid
Название: Video zoom out
Ссылка на модель: https://civitai.com/models/1603842/video-zoom-out?modelVersionId=1814970
Тип модели: #LoRA
Количество скачиваний: 600+
Дата загрузки: 21 мая 2025
Базовая модель: Wan Video 14B i2v 480p
Триггерные слова: layuan,场景描述+镜头拉远+场景描述【越丰富越好,但描述不可与图像相冲突】
Теги: #objects, #video, #zoom, #zoomout, #cinematic, #effect
Описание модели/Комментарий разработчика:
LoRA имитирует эффект классического киношного zoom-out — от крупного плана к широкой сцене. Позволяет показать окружение персонажа, усилить эмоциональный переход и придать кадру повествовательную динамику.
Подходит для арт-фильмов, сюжетных вставок и видеороликов с кинематографичной подачей.
Источник: @neurosklad 🤖 — все, что нужно, для твоей нейронки!
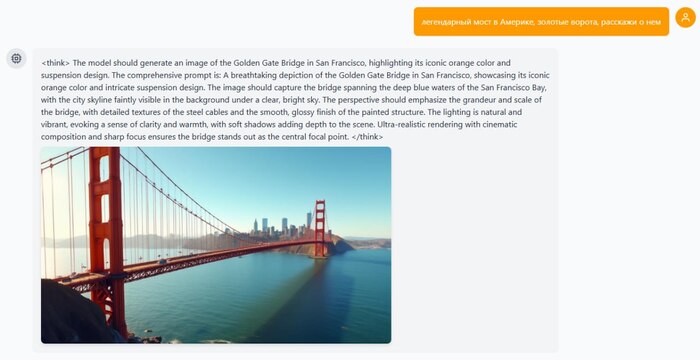
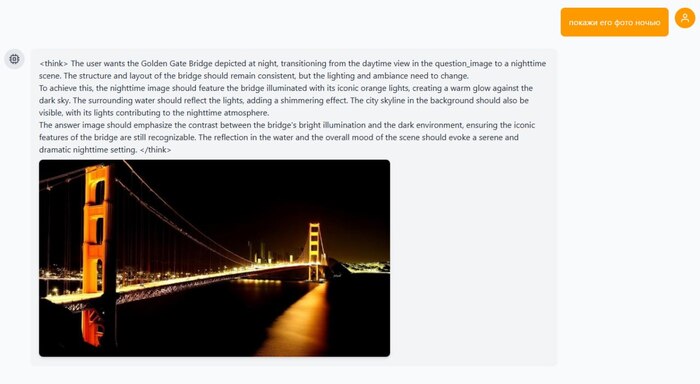
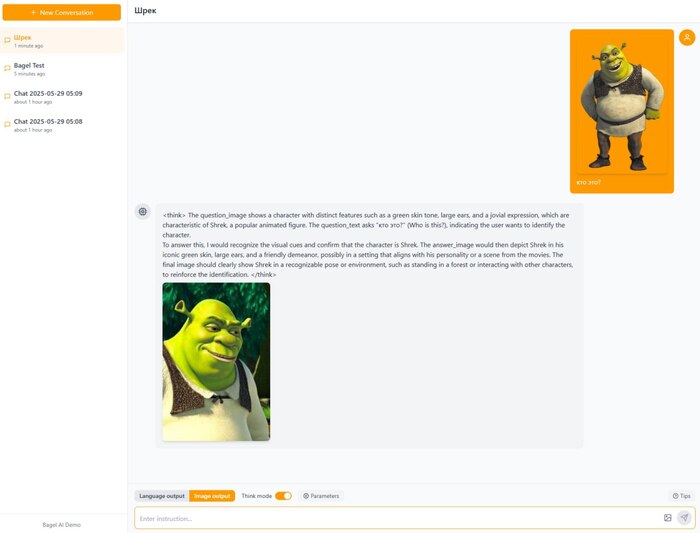

ByteDance опять роняет запад! Они открылм код BAGEL — единой мультимодальной модели нового поколения, которая «видит», «читает» и «рисует» в одном флаконе. Проект вышел 20 мая 2025 года и сразу доступен под Apache 2.0 — можно дообучать и использовать коммерчески.
Что умеет
🔘 принимает текст + изображения и отвечает тем же смешанным форматом;
🔘 генерирует, редактирует, переносит стили;
🔘 разворачивает краткие запросы в режиме <think>;
🔘 лидирует среди open-source VLM: MME-P 1687, MMBench 85 %, MMMU 55 %, MMVet 67 %.
🔘мультиязычность, понимает и на русском, но отвечает на английском.
Архитектура
BAGEL построена на Mixture-of-Transformer-Experts (MoT): токены маршрутизируются между «экспертами», что увеличивает ёмкость без заметных задержек. Визуальная часть кодируется двумя энкодерами — ViT отвечает за пиксельные детали, VAE — за семантику. Далее объединённые представления поступают в MoT-декодер, обученный в парадигме Next Group of Token Prediction, поэтому модель одинаково уверенно продолжает как текст, так и визуальные токены.
Уже доступны GGUF-веса (ema)
• q2_k — 5.53 GB
• q4_k_m — 8.85 GB
• q6_k — 12.5 GB
Ссылки
📖 Страница проекта — https://bagel-ai.org/
🌍 Веб-демо — https://demo.bagel-ai.org/
Источник: 🎯 НЕЙРО-ПУШКА ● НОВОСТИ И ОБЗОРЫ НЕЙРОСЕТЕЙ



