

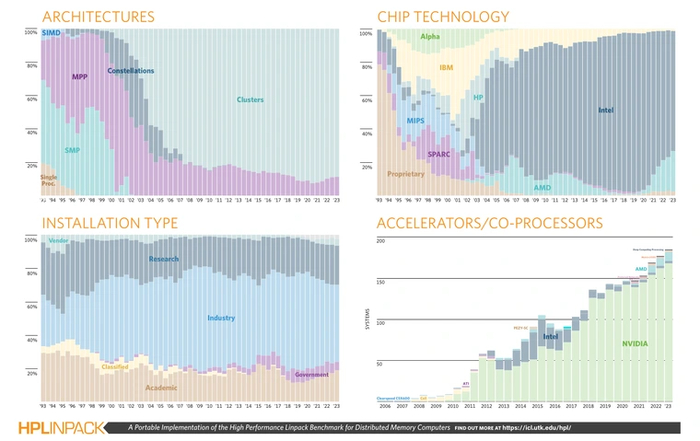
Немного истории
47 постов
47 постов
10 постов
180 постов

4 поста

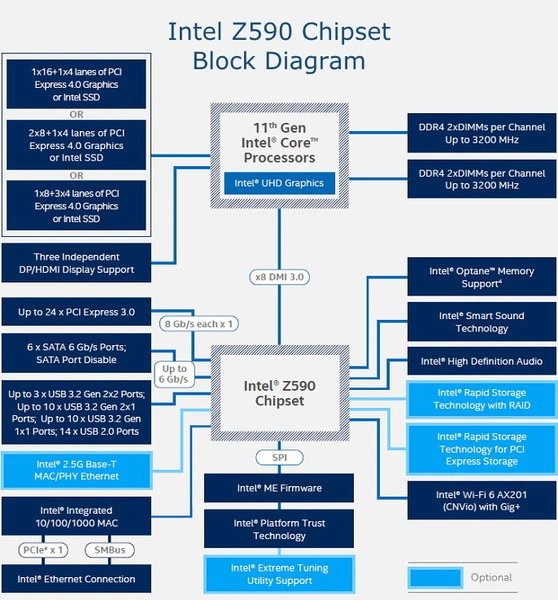
Выпуск серии видеокарт RTX20 в свое время стал важнейшим событием в сфере компьютерных технологий. Десктопные видеокарты впервые получили отдельные тензорные ядра. Что это такое? Как работают эти ядра и для чего используются?
Работа с графикой — специфическая задача для компьютерного «железа». Здесь требуется выполнять довольно однообразные команды с большим объемом данных. Архитектура CPU для этого подходит плохо. Из-за ограниченного числа ядер и АЛУ (арифметико-логических устройств) процессоры не могут быстро делать объемные операции по сложению и умножению.
Был необходим максимальный параллелизм — одновременная обработка данных. Одним из решений стали CUDA-ядра — технология, созданная Nvidia больше десяти лет назад. Эти ядра создали специально для параллельной работы. На чипе помещались сотни и тысячи CUDA-ядер, а их число стало одним из критериев оценки производительности видеокарты.
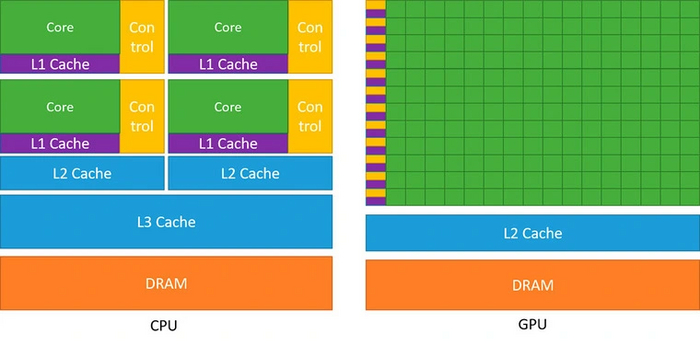
CUDA-ядра имеют высокоскоростной доступ к видеопамяти, так что обработка выполняется с минимальными задержками. Это важнейший показатель для быстрого вывода подготовленных кадров на монитор.
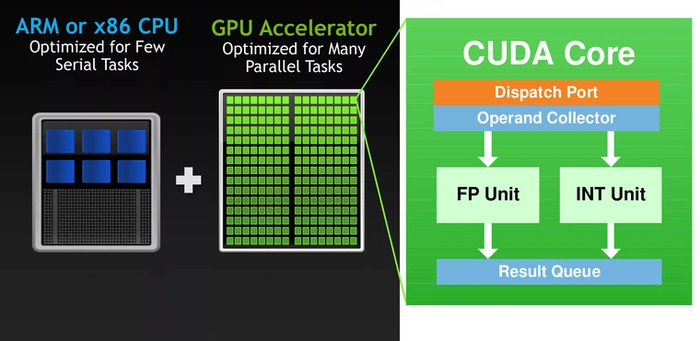
Однако обработка больших объемов данных нужна не только при выводе графики. Она требуется для научных вычислений, моделирования физических процессов и машинного обучения. Во всех этих задачах одна из главных операций — перемножение матриц.
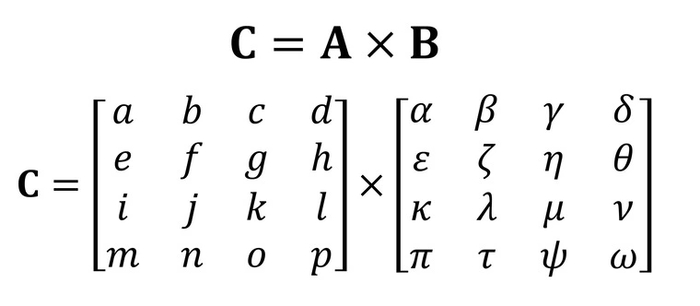
Задача непростая. Скажем, для решения вышеописанного примера нужны целых 64 умножения и 48 сложений. Не говоря о том, что промежуточные результаты нужно еще где-то хранить. Для операций чтения и записи нужны дополнительные регистры и достаточно скоростная кэш-память.
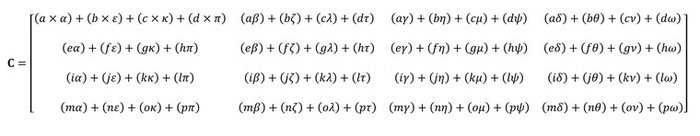
Может ли с этой задачей справиться CPU? Вообще-то, да. Специально для таких вычислений в процессорах начали появляться инструкции MMX, SSE и (самые совершенные) AVX. Однако видеокарты с их многочисленными CUDA-ядрами — более предпочтительный вариант. Они могут распараллелить большую часть простых операций сложения и умножения. Но даже для них задача просчета матриц оставалась трудоемкой. Решением стали тензорные ядра.
Одно такое ядро способно перемножить две матрицы за один такт. В то время как CUDA-ядрам требуется несколько тактов.
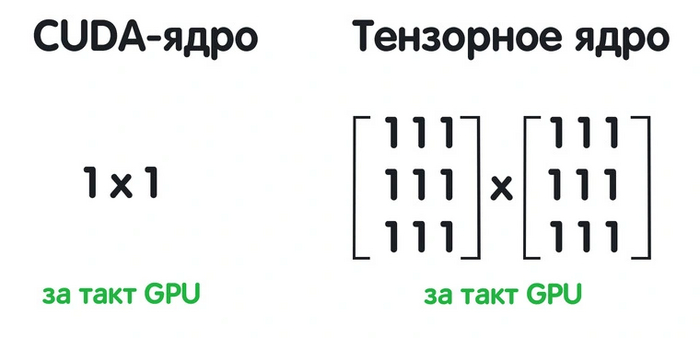
Первое тензорное ядро представляло собой микроблок, выполнявший суммирование-произведение матриц 4x4. Могли использоваться значения FP16 (числа с плавающей запятой размером 16 бит) или умножение FP16 с добавлением FP32.
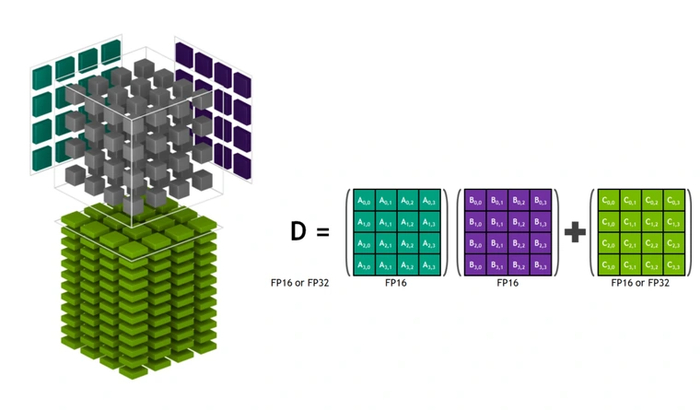
Размерность рабочих матриц невелика. Ядра при обработке реальных наборов данных обрабатывают небольшие блоки более крупных матриц, в итоге формируя окончательный ответ.
Решение оказалось крайне эффективным. Специалисты из Anandtech провели замеры производительности топовых решений от Nvidia — без тензорных ядер и с ними.

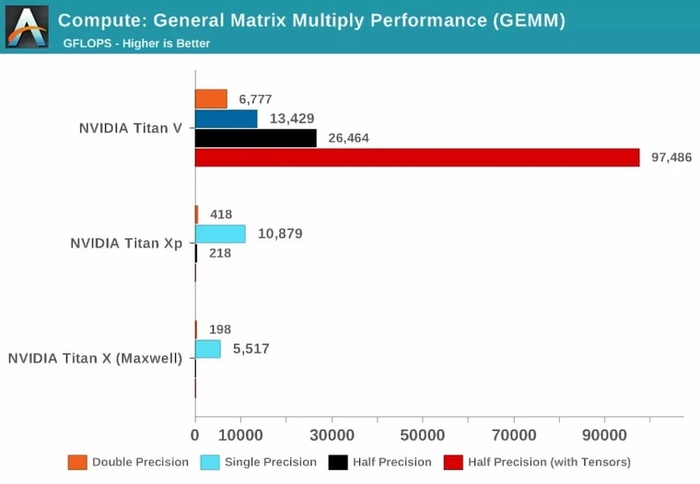
В операциях перемножения матриц (GEMM) прирост производительности с использованием тензорных ядер колоссальный.
Тензорная математика активно используется в физике и инженерии для решения всех видов сложных вычислений. Например, в механике жидкостей, электромагнетизме, астрофизике, медицине и климатологии. В суперкомпьютерах для этих задач обычно используют крупные кластеры с тысячами высокопроизводительных процессоров уровня Xeon Platinum или AMD Epyc. Однако видеоускорители стали неотъемлемой частью практически любого суперкомпьютера. Подавляющее число машин из рейтинга Top500 работают на базе решений от Nvidia.

Задача глубокого обучения в самом простом смысле — это работа с математическими выражениями. Простейший вариант — нейронная сеть, состоящая из одного слоя с двумя нейронами и линейными функциями активации. Представлена она вот таким умножением вектора на матрицу:
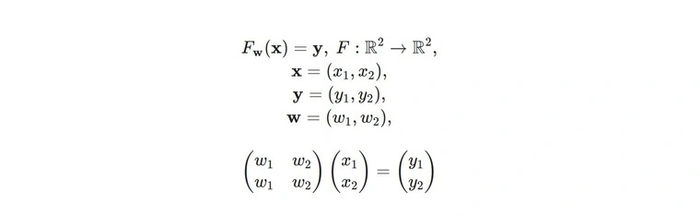
Задача обучения сводится к поиску наилучших коэффициентов W. То есть предполагаются матричные операции.
На практике нейросети чаще всего многослойные, и математические выражения получаются куда сложнее. Однако принципиально используются все те же действия — умножение и сложение матриц. Тензорные ядра как раз ориентированы на эти действия.
Самый яркий пример — суперкомпьютер, созданный Microsoft совместно c OpenAI. В нем использовали 10 тысяч графических процессоров Nvidia V100. Именно этот компьютер применили для обучения ChatGPT-3. Продукты Nvidia можно найти в Microsoft Azure, Oracle Cloud и Google Cloud.

Илон Маск для своего ИИ Grok также задействует продукцию Nvidia. Изначально это был кластер на 20 тысяч графических процессоров H100. Недавно для обучения версии GROK 3 миллиардер запустил суперкомпьютер с сотней тысяч NVIDIA H100! Теперь вы можете понять, почему NVIDIA стала самой дорогой компанией и продолжает наращивать прибыль.
Инференс — это запуск уже обученной модели, «скармливание» данных и получение результата. Процесс менее требователен к вычислительной мощности. Но здесь все так же используются матричные операции. Сюда входит распознавание текста (например, в голосовых помощниках), поиск объектов на изображении (распознавание лиц, номерных знаков), шумоподавление и не только.
Тензорные ядра и здесь предлагают высокую производительность. Они позволяют запускать «легкие» нейросети прямо на домашних видеокартах средневысокого ценового сегмента. Например, запустить Chat with RTX — тут достаточно RTX 30 или 40 серии с минимум 8 ГБ видеопамяти. Stable Diffusion также можно запустить локально на видеокартах. Однако производительность каждой модели зависит еще и от ПО. Оно не всегда в полной мере задействует те же тензорные или CUDA-ядра.
Один из самых доступных вариантов инференса нейросетей — технология DLSS. Специально обученная на игре нейросеть запускается на тензорных ядрах видеокарты, повышая разрешение картинки в реальном времени. Игрок, в свою очередь, получает более высокий FPS. DLSS 3 работает только на видеокартах серии RTX40.
Поскольку это авторская разработка «зеленых», то именно «тензорные ядра» можно найти лишь в продукции этой компании.
Впервые появились в Nvidia TITAN V в 2017 году — карта имела 640 ядер. После этого ядра стали неотъемлемой частью профессиональных ускорителей


С каждой новой архитектурой появлялось усовершенствованное поколение тензорных ядер. Так что сравнивать их число в рамках разных поколений некорректно. Есть и различия в поддерживаемых форматах данных. Первые ядра могли складывать матрицы с данными только FP16, а современные имеют поддержку куда больших форматов.
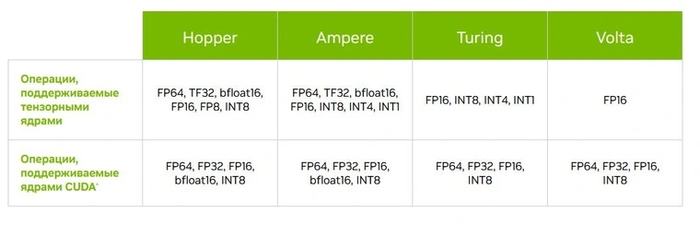
В десктопных и мобильных видеокартах технология стала доступна с приходом серии RTX20.
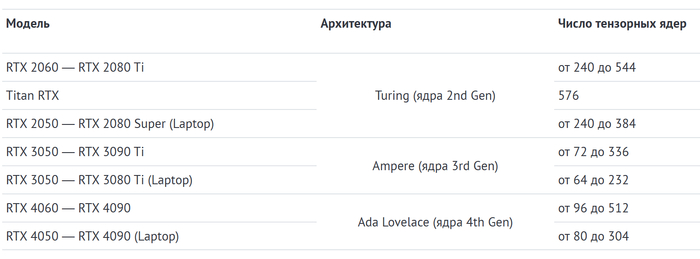
Именно благодаря тензорным ядрам пользовательские карты RTX можно использовать для работы с нейросетями. А также получить апскейл с использованием ИИ. Альтернативные технологии вроде XeSS и FSR базово специальных ядер не требуют.
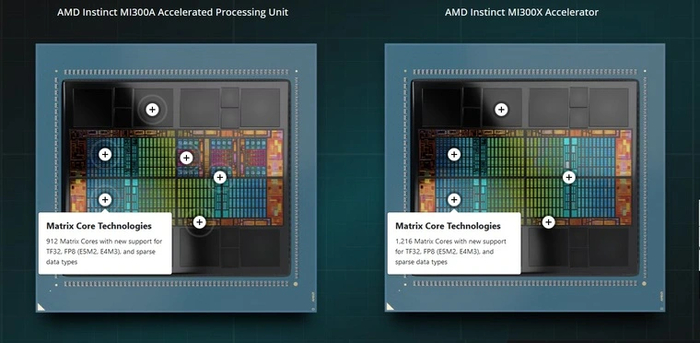
Компания «красных» на рынок ИИ вышла относительно недавно. Аналогом тензорных ядер у них является Matrix Core Technologies, которая появилась в архитектуре CDNA 3.

Ядра Matrix Core Technologies пока встречаются только в AMD Instinct MI300A (912 штук) и MI300X (1216 штук). Новые ИИ-ускорители планируют поставить в немецкие суперкомпьютеры Hunter и Herder — в 2025 и 2027 годах соответственно. Сейчас же у немцев работают суперкомпьютеры Hawk и JUWELS на базе Nvidia A100.
У «синих» используются ядра XMX (Xe Matrix Extensions), созданные специально для матричных вычислений. На них аппаратно работает и фирменный апскейлер Intel XeSS. Встретить ядра XMX можно в линейке видеокарт ARC.
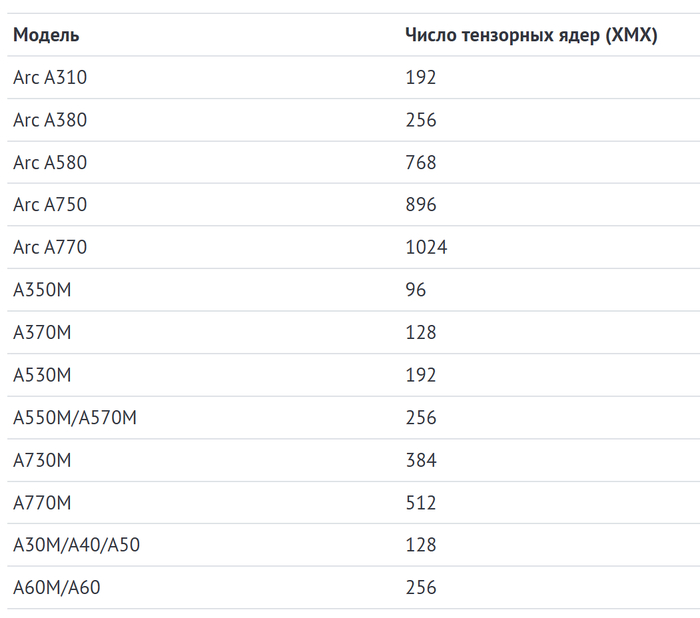

Ядра XMX используются и в Intel Xᵉ HPC 2, установленных в Data Center GPU Max. Графика Xe2-LPG будет встроена в процессоры Lunar Lake. Там также будут использоваться XMX-ядра для задач, связанных с работой ИИ.
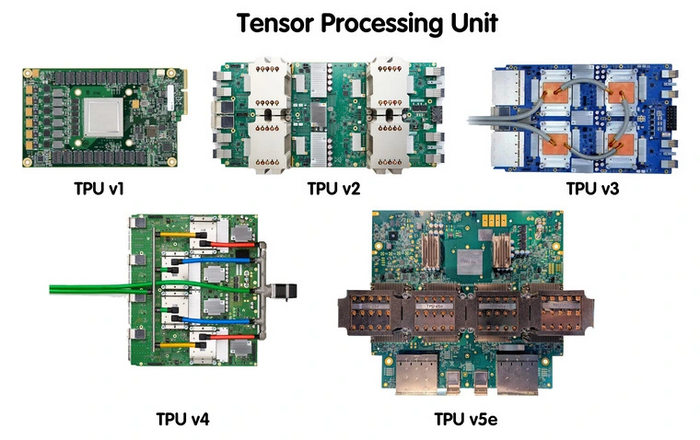
В компании не стали изобретать отдельные ядра, а нацелились сразу же на разработку полноценных плат. Они получили название TPU — Tensor Processing Unit. Эти платы специализируются на обработке матриц. Они подходят как для тренировки, так и выполнения нейросетей.

В марте 2025 года состоялся выход первых видеокарт AMD из долгожданной линейки Radeon RX 9000. Их основой стала архитектура RDNA четвертого поколения, в которой было сделано множество доработок как для улучшения производительности, так и для поддержки современных графических технологий.
Направление развития технологий, использующихся для 3D-графики реального времени, не раз менялось. Его последний крупный поворот был совершен компанией NVIDIA в 2018 году, когда была представлена графическая архитектура Turing. Ориентация на трассировку лучей и сопутствующие технологии для ее адекватной работы потребовали добавления в графические процессоры новых блоков, которые не участвовали в традиционной растеризации.
Подобный подход был встречен прохладно. Линейку видеокарт RTX 2000 критиковали за низкий прирост «чистой» производительности, а первые реализации трассировки лучей в играх выглядели не очень впечатляюще. Многие сходились во мнении, что «Транзисторный бюджет, выделенный на RT-ядра и тензоры, потрачен зря. Лучше бы шейдеров добавили».
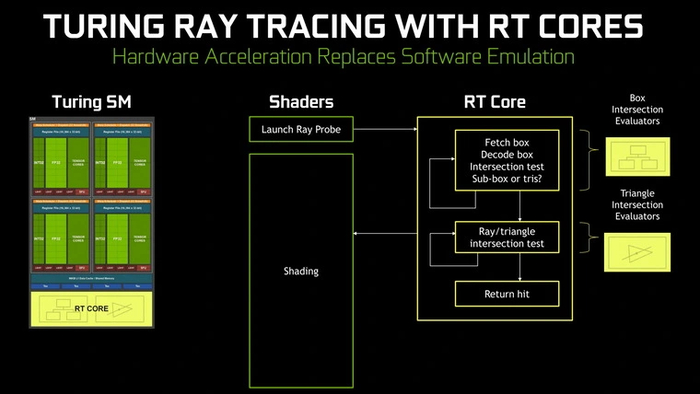
За этой ситуацией наблюдал и давний конкурент в лице AMD, который тогда разрабатывал новую графическую архитектуру под названием Radeon DNA. Решив, что для аппаратной трассировки лучей слишком рано, компания не стала наспех вносить какие-то изменения в RDNA. Летом 2019 года она выпустила первые видеокарты серии RX 5000, у которых поддержки этой новомодной технологии еще не было.
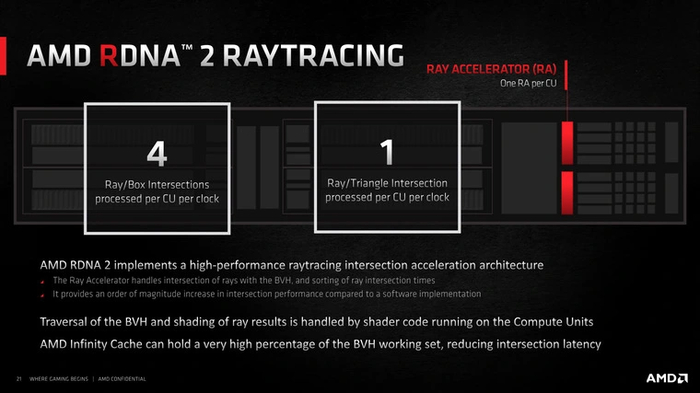
Но время шло, и менее чем через год после выхода RX 5000 появились слухи о следующей линейке NVIDIA — RTX 3000. Поняв, что для конкуренции без трассировки лучей никак, AMD стала работать над интеграцией технологии в архитектуру RDNA второго поколения. Но, в отличие от конкурента, компания не стала тратить на это огромный транзисторный бюджет. Она сделала собственные блоки Ray Accelerator проще, переложив часть работы по трассировке на универсальные шейдерные процессоры.
С выходом серий RTX 3000 и RX 6000 конкурирующие карты «зеленых» и «красных» явно отличались только производительностью трассировки — у решений от AMD она была заметно меньше. В 2022 году ситуация повторилась: хотя в линейке RX 7000 на архитектуре RDNA 3 производительность трассировки была улучшена, конкурировать в этом плане с RTX 4000 она не могла. А одновременное появление на рынке видеокарт третьего игрока в лице Intel, с ходу показавшего неплохие достижения в рейтрейсинге, усугубило ситуацию еще больше: AMD в этой тройке «лучистых» была явным аутсайдером.
Но компания понимала, что рано или поздно придется «раскошелиться» на производительное решение для трассировки лучей. Главной дилеммой было то, как при ограниченном транзисторном бюджете добиться в этом высокой производительности. И, похоже, AMD наконец ее решила. Встречайте — Radeon RX 9000 на новой графической архитектуре RDNA 4.

Базовым элементом в графических процессорах AMD являются вычислительные блоки Compute Unit (CU). В состав CU RDNA 4 входят 64 универсальных шейдерных процессора (SP), два планировщика исполнения, кэш нулевого уровня (L0), регистровый файл, блок трассировки лучей (RA), четыре текстурных блока (TMU), два ускорителя вычислений искусственного интеллекта (AI Accelerator) и другие вспомогательные блоки.
Как и прошлые поколения ГП AMD, графические чипы RDNA 4 состоят из шейдерных движков Shader Engine (SE). В каждом из них находится 16 CU, объединенных попарно в более крупные блоки Compute Engine (CE), а также блоки растеризации (ROP) и прочая обвязка. Всего один такой движок содержит:
16 вычислительных блоков CU (объединенных попарно в 8 блоков CE)
1024 шейдерных процессора SP
64 текстурных блока TMU
32 растровых блока ROP
16 RA-блоков для трассировки лучей
32 блока матричных вычислений AI Accelerator
Первым ГП на базе новой архитектуры стал Navi 48. Он включает в себя:
4 шейдерных движка SE
64 вычислительных блока CU
4096 шейдерных процессоров SP
256 текстурных блоков TMU
128 растровых блоков ROP
64 RA-блока для трассировки лучей
128 блоков матричных вычислений AI Accelerator
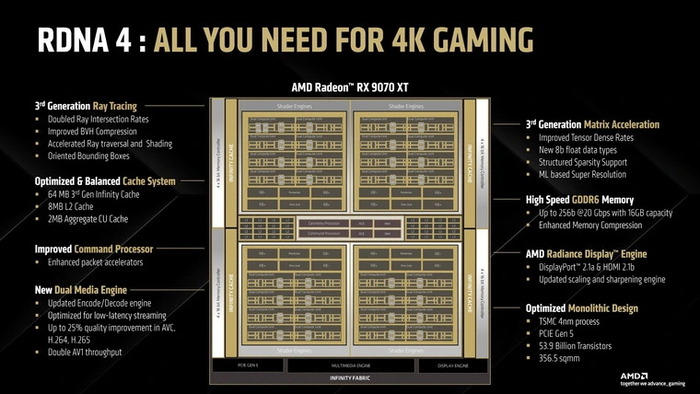
Как можно видеть по характеристикам, Navi 48 не является заменой флагманскому чипу Navi 31, на котором основаны модели серии RX 7900. Этот ГП — прямой последователь Navi 32, на базе которого в прошлом поколении видеокарт были выпущены RX 7700 XT и RX 7800 XT. Теперь для их замены предлагаются новинки в лице RX 9070 и RX 9070 XT. Обе оснащены 16 ГБ видеопамяти.

Аналогично чипу Navi 32, Navi 48 имеет 256-битную шину памяти GDDR6 и 64 МБ кэш-памяти Infinity Cache. Скорость работы в последней была увеличена, а кэш второго уровня заметно подрос — с 1 до 2 МБ на SE, что дает общий объем в 8 МБ на весь ГП. Вдобавок к этому появилась поддержка шины PCI-E 5.0 с полноценными 16 линиями, которая позволяет «общаться» видеокарте с системой вдвое быстрее, чем в прошлом поколении. Самое интересное в том, что в этот раз AMD не стала использовать для подобного ГП чиплетную компоновку, как в прошлом поколении. Navi 48 является монолитным чипом с площадью 356 мм2, что сравнимо с Navi 32. Но транзисторов в нем почти вдвое больше — 53,9 млрд против 28,1 млрд у предшественника. Новые вычислительные блоки, о которых мы расскажем далее, сделали ГП заметно сложнее, приблизив его по этому параметру к флагманскому чипу прошлого поколения Navi 31 с 57,7 млрд транзисторов.

Для производства нового ГП используется техпроцесс TSMC N4C — третье поколение 5 нм, оптимизированное для более низкой себестоимости выходной продукции. В связи с этим работа, проделанная AMD, впечатляет вдвойне: Navi 48 обладает рекордной плотностью транзисторов в 150 млн/мм2. Это на четверть больше, чем в чипах NVIDIA Blackwell на схожем техпроцессе TSMC 4N, которые используются в линейке видеокарт RTX 5000.
В основе чипов RDNA 4 лежат обновленные сдвоенные вычислительные блоки, получившие название Compute Engine. В целом, их устройство довольно схоже с Dual Compute Unit в архитектуре RDNA 3. В каждом CU содержится:
64 векторных блока для вычислений с плавающей запятой (FMA)
64 векторных суперскалярных блока, умеющих работать одновременно с целочисленными и плавающими вычислениями (FMA/INT)
16 трансцендентных блоков вычислений (TLU) для выполнения сложных инструкций
Четыре текстурных блока (TMU)
Два блока скалярных вычислений (SU)
Два блока матричных вычислений (AI Accelerator)
Блок загрузки/выгрузки данных (Load/Store)
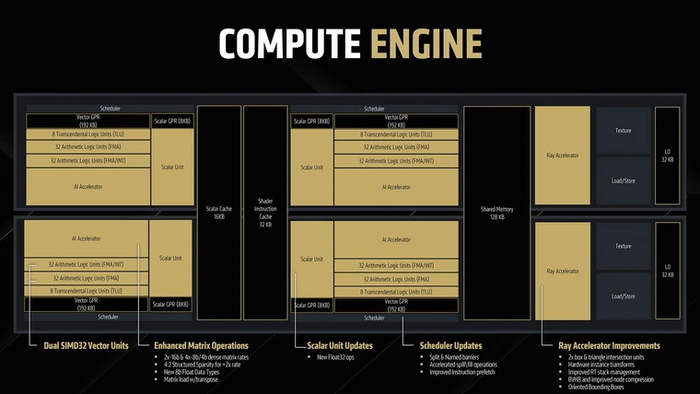
Вычислительные блоки в CU поделены на две части. Каждая из них имеет планировщик исполнения (Scheduler) и собственные регистровые файлы — 192 Кб для векторной и 8 Кб для скалярной вычислительной части. Помимо этого, CU обладает собственным кэшем L0 для данных объемом 32 Кб. При этом кэш шейдерных инструкций объемом 32 Кб и скалярный кэш объемом 16 Кб для обоих CU являются общими. А для эффективного обмена данными в процессе вычислений оба CU связаны 128 Кб общей памяти.
Как видим, AMD все так же считает количество шейдерных процессоров по суперскалярным вычислительным блокам, работающим с двумя типами вычислений — плавающими (FP32) и целочисленными (INT32). На самом же деле, как и в RDNA 3, блоков вычислений с плавающей запятой тут вдвое больше — не 64, а 128 на CU. Поэтому вычислительную мощность в терафлопсах у чипов с этими двумя родственными архитектурами сравнивать можно (без учета улучшений других блоков), а вот с более старыми на базе RDNA 2 — нельзя.
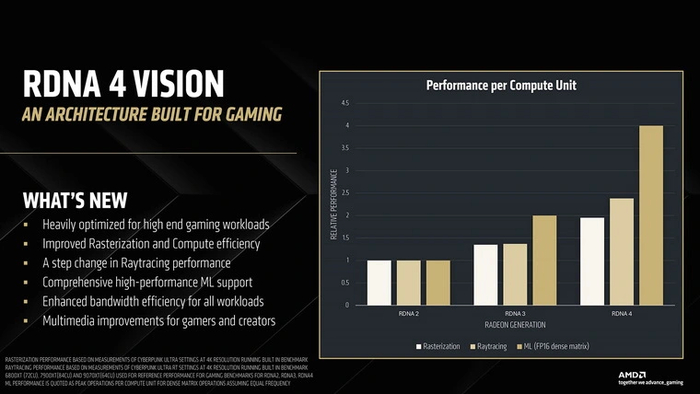
По диаграммам, представленным AMD, CU RDNA 4 до полутора раз быстрее вычислительного блока прошлого поколения в растеризации. А с блоком RDNA 2 разрыв двукратный. Но в этом сравнении стоит учитывать, что ГП RDNA 4 могут работать на заметно более высокой частоте, чем предшественники — до 3 ГГц и выше.
При задействовании трассировки лучей отрыв CU новой архитектуры еще более высокий. Рассмотрим, за счет чего это достигается.
Одна из самых главных и ожидаемых новинок в RDNA 4. AMD долго противилась необходимости делать сложные блоки для трассировки. Но наконец наступил момент, когда для сохранения конкурентоспособности видеокарт компании пришлось на это пойти. Встречайте — Ray Accelerators третьего поколения.
Первая реализация блоков трассировки в RDNA 2 умела просчитывать четыре пересечения луча с боксами иерархии ограничивающих объемов (BVH) либо одно пересечение с полигоном. В RDNA 3 темп расчетов остался тем же, но благодаря новой контрольной логике блоки стали работать до 80 % эффективнее. У RDNA 4 RA-блоки наконец «расширили», позволив им выполнять вдвое больше операций за такт — восемь пересечений с боксами либо два пересечения с полигонами.
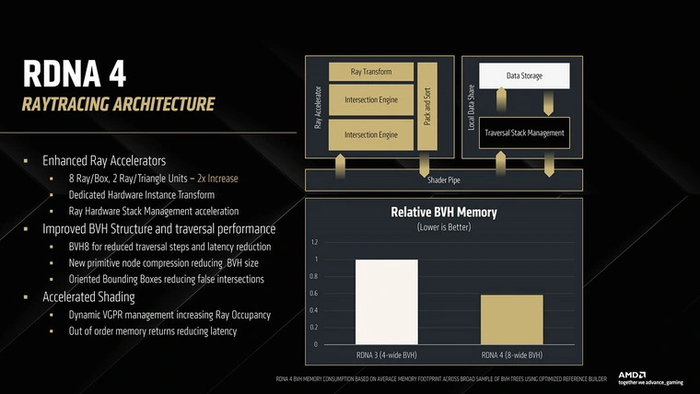
Теперь часть операций, необходимых для рейтрейсинга, ускорена аппаратно — для этого в составе Ray Accelerators появились выделенные блоки для преобразования экземпляров и управления стеком трассировки. Вычислительные ресурсы RA-блоков стали расходоваться экономнее благодаря технологии ориентированных боксов. Она предназначена для уменьшения объемов BVH, в которых необходимо просчитывать пересечения лучей за счет изменения их ориентации. При стандартном подходе эти объемы формируются в виде боксов, находящихся в пространстве строго вертикально или горизонтально. Ориентированные боксы можно размещать под любым углом, подгоняя их под форму и расположение объекта в кадре. Благодаря этому можно избавить RA-блоки от приличного объема ненужной работы.

Несмотря на перевод некоторых операций на отдельные аппаратные блоки, часть вычислений для трассировки все так же выполняется на шейдерах. Но и тут не обошлось без заметных улучшений. Шейдерные процессоры RDNA получили возможность внеочередного выполнения кода и динамические регистры. Благодаря этому они могут комбинировать расчеты для трассировки и выполнение шейдерного кода гораздо эффективнее, чем это было в предшествующей RDNA 3.
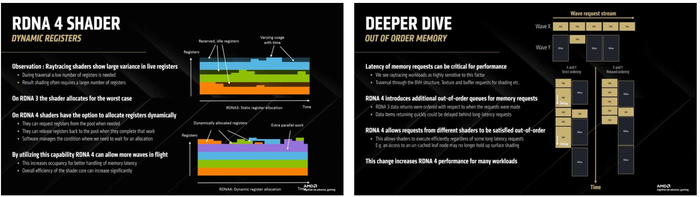
AMD заявляет, что производительность трассировки возросла вдвое благодаря всем улучшениям. На самом деле, учитывая заметную реорганизацию RT-конвейера, реальный прирост при большом количестве лучей в кадре может быть даже больше. Так что на видеокартах AMD наконец с достаточной производительностью можно будет использовать трассировку пути.

Вдобавок к этому подавление шумов, возникающих при трассировке, было переведено с шейдеров на выделенные блоки AI Accelerators. Давайте посмотрим, что они из себя представляют.
Именно так AMD называет новые блоки матричных вычислений. И не зря. В отличие от предшественников в RDNA 3, просто переназначавших SIMD векторных блоков для выполнения подобных операций, AI Accelerators являются самостоятельными вычислительными блоками — аналогично тензорным ядрам в ГП NVIDIA или матричным блокам XMX в ГП Intel.

По сравнению с блоками прошлого поколения, ИИ-ускорители обзавелись вдвое более широким конвейером и поддержкой расчетов низкой точности FP8/BF8. Но, что самое важное, они научились работать с разреженными вычислениями (sparse compute). Это позволяет увеличить темп исполнения расчетов еще в два или четыре раза, в зависимости от точности.

Благодаря этому общий прирост скорости матричных вычислений на одной частоте составляет от четырех до восьми раз. И не забываем, что на такие вычисления теперь не тратятся ресурсы шейдерных процессоров.
За счет совокупности всех улучшений, заметно повысивших производительность тензорных расчетов, блоки AI Accelerators стало возможным использовать не только для подавления шумов при трассировке, но и для работы нового алгоритма фирменной технологии повышения производительности FSR 4.
Технология масштабирования на основе глубокого обучения. Теперь это не только NVIDIA DLSS и Intel XeSS, но и AMD FSR четвертого поколения. Базовые техники ее работы схожи с FSR 2.х: это рендер кадров со сдвигом на основе векторов движения, а затем — комбинация временной информации из нескольких кадров и карты глубин для создания картинки целевого разрешения. Ключевое отличие в том, что для этого используются не расчеты на шейдерных процессорах, а нейросеть, работающая на ИИ-ускорителях.

Такое масштабирование заметно качественнее и гораздо внимательнее к деталям, чем упрощенная обработка FSR второго и третьего поколения.

Нейросеть FSR 4 предварительно обучена на игровых данных с помощью серверных ГП AMD. Это позволяет совершенствовать алгоритм ее работы с каждым новым выпуском драйверов.

Никуда не делась и поддержка генерации кадров, дебютировавшая в FSR 3. FSR 4 Frame Generation, как и ее предшественница, может вставлять один сгенерированный кадр между двумя отрендеренными на основе информации из оптического потока и векторов движения. На данный момент AMD не уточняет, как обрабатываются новые кадры при генерации. Судя по слайдам из официальной презентации, пока для этого используются универсальные шейдеры, как и в FSR 3.x. Но с будущими обновлениями и к этому процессу будут подключены ИИ-ускорители. FSR 4 использует API, обратно совместимый с FSR 3.1. Это значит, что ее интеграция в существующие игры с FSR третьего поколения будет довольно простой. Вдобавок к этому новая технология полностью совместима с нейронным рендерингом.

Чипы архитектуры RDNA 4 получили новый движок дисплея Radiance 2 Display Engine. Им поддерживается вывод изображения с помощью современных интерфейсов DisplayPort 2.1a и HDMI 2.1b. Главные улучшения: сниженное энергопотребление в режиме ожидания при использовании двух мониторов, новый блок повышения резкости и аппаратная поддержка технологии Flip Metering — той самой, которую NVIDIA использует в чипах Blackwell для мультигенерации кадров в DLSS 4. Не исключено, что AMD тоже готовит похожую технологию, но представит ее позже.

Чип Navi 48 получил мультимедийный движок с двумя кодировщиками и двумя декодерами. Качество кодирования популярных форматов H.264 и HEVC было заметно улучшено — на 25 и 11 %, соответственно. Это особенно заметно при низких битрейтах.

Для более «молодого» формата AV1 был увеличен максимальный битрейт и появилась поддержка B-кадров. Общая производительность мультимедийного движка по сравнению с прошлым поколением возросла более чем на 50 %.
Новую графическую архитектуру RDNA 4 можно охарактеризовать короткой фразой: «Все, чего нам так давно не хватало». AMD наконец заметно подтянула скорость работы с трассировкой лучей, оснастила чипы полноценными матричными ускорителями AI Accelerators, разработала собственную технологию масштабирования на основе глубокого обучения FSR 4, а также произвела множество других мелких доработок архитектуры, которые необходимы для эффективной работы с нейронным рендерингом.

Теперь видеокарты компании и при задействовании современных графических технологий могут практически наравне конкурировать с решениями от NVIDIA и Intel. Стоп, все же чего-то не хватает. Да, флагманского чипа! Но в этом поколении AMD вновь заявила, что «топовых видеокарт не будет». Такое уже было и в 2016 году при появлении видеокарт серии RX 400, и в 2019 году, когда была представлена линейка RX 5000.
Впрочем, как показывает история, каждый раз после подобных заявлений уже через год AMD собиралась и представляла ГП на базе доработанной архитектуры, конкурирующий с топами NVIDIA. И хотя сейчас «зеленые» с огромным чипом GB202 кажутся вне досягаемости, с RDNA 4 шанс у AMD есть. Удвоив возможности Navi 48 (что вполне реально с использованием текущего техпроцесса), она вполне может приблизиться к текущему флагману NVIDIA по скорости.
Вопрос в том, а нужно ли это компании? На данный момент — точно нет. Сейчас AMD сосредоточена на росте новой линейки «вширь». Во втором квартале 2025 года будут выпущены карты серии RX 9060, а затем ожидаются и бюджетные RX 9050. Если ценовая политика компании будет правильной, то за счет линейки RX 9000 к AMD вновь должна вернуться заметная часть рынка видеокарт, как это было несколько поколений назад.

PCIe, он же PCI-Express, представляет собой очень мощный интерфейс, давайте рассмотрим основные принципы его использования в собственных проектах. Поначалу PCIe может немного пугать, но он всё же достаточно прост для экспериментов и вполне пригоден для применения в рамках хобби. В определённый момент вы можете решить использовать микросхему PCIe в собственных проектах или, например, задействовать подключение PCIe на Raspberry Pi Compute Module, так что лучше быть к этому готовым.
Сегодня PCIe можно встретить повсюду. В каждом современном компьютере присутствует ряд устройств PCIe, выполняющих важнейшие функции, и даже в iPhone этот интерфейс внутренне используется для соединения процессора с флеш-памятью и микросхемой Wi-Fi. Нам доступны всевозможные устройства с PCIe: контроллеры Ethernet, высокопроизводительные платы Wi-Fi, графические ускорители и всяческие дешёвые NVMe-диски. Если вы экспериментируете с ноутбуком или одноплатником и хотите добавить в него устройство с PCIe, то можете получить сигнал PCIe от одного из разъёмов PCIe или просто подключиться к имеющейся линии PCIe, если таковых разъёмов нет. С момента появления устройств PCIe прошло уже два десятилетия — сейчас эта технология достигла ревизии 5.0 и однозначно останется с нами надолго.
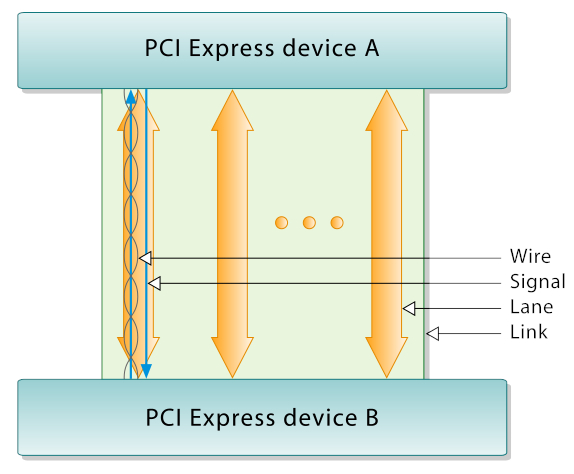
PCIe — это шина, которая соединяет два устройства по типу «точка-точка» — в противоположность более древней PCI, которая могла соединять на материнской плате цепочку устройств. На одной стороне этого соединения присутствует устройство PCIe, а другая выступает хостом. К примеру, в процессоре ноутбука есть несколько портов PCIe — один используется для подключения GPU, другой для платы Wi-Fi, третий для Ethernet, а четвёртый для NVMe-диска.
PCI Express ( Peripheral Component Interconnect Express ), официально сокращенно PCIe или PCI-E ,— это высокоскоростной стандарт последовательной шины расширения компьютера , призванный заменить старые стандарты шин PCI , PCI-X и AGP . PCIe имеет многочисленные улучшения по сравнению со старыми стандартами, включая более высокую максимальную пропускную способность системной шины, меньшее количество контактов ввода-вывода, меньший физический размер, лучшее масштабирование производительности для устройств шины, более подробный механизм обнаружения и сообщения об ошибках (Advanced Error Reporting, AER) и собственную функциональность горячей замены . Более поздние версии стандарта PCIe обеспечивают аппаратную поддержку виртуализации ввода-вывода .
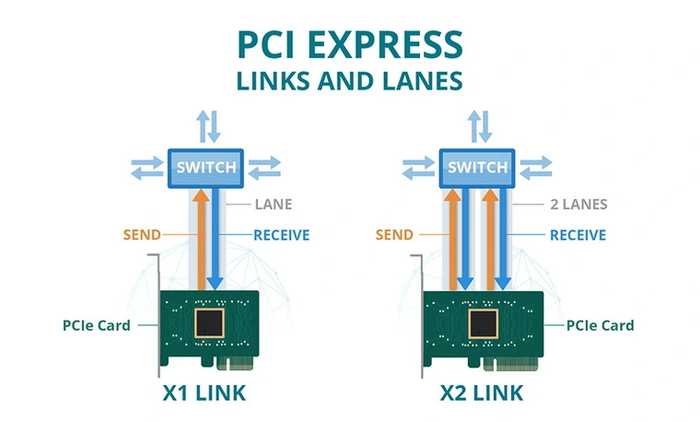
Электрический интерфейс PCI Express измеряется числом одновременных полос. (Полоса — это набор линий передачи и приема данных, аналогичных дороге с одной полосой движения в каждом направлении.) Интерфейс также используется во множестве других стандартов — в частности, в интерфейсе карты расширения ноутбука , называемом ExpressCard . Он также используется в интерфейсах хранения данных SATA Express , U.2 (SFF-8639) и M.2 .
Каждая линия PCIe состоит из как минимум трёх дифференциальных пар — одна представляет тактовый генератор 100 МГц, REFCLK, который (почти) всегда необходим для соединения, а две формируют канал PCIe — одна служит для передачи и вторая для получения. Такая схема называется линией 1x — также бывают линии 2х, 4х, 8х и 16х, в которых используется четыре, восемь, шестнадцать и тридцать две дифференциальные пары соответственно плюс, опять же, REFCLK. Чем шире линия, тем выше её пропускная способность.
Ширина линии PCIe представляет интересную тему со многими важными аспектами, но сначала желательно проговорить, что означает «дифференциальная пара» именно в этом контексте.
Однотактные технологии
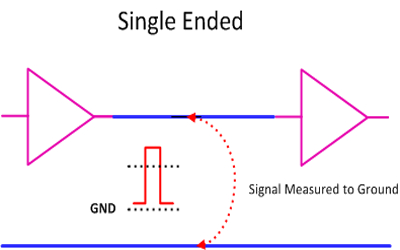
В совокупности такие стандарты, как TTL, CMOS и LVTTL, известны как однотактные технологии, и у них есть некоторые общие нежелательные свойства, а именно: шум заземления напрямую влияет на запас по шуму (бюджет допустимого уровня шума), а любой наведенный шум, измеренный относительно земли, также напрямую добавляется к общему шуму.
Увеличивая перепад напряжения до больших значений, мы можем добиться того, чтобы шум выглядел меньше пропорционально, но за счет скорости, поскольку для создания больших перепадов напряжения требуется больше времени, особенно с учетом того типа емкости и индуктивности, которые мы иногда наблюдаем.
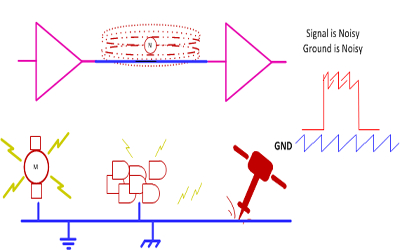
Дифференциальные технологии
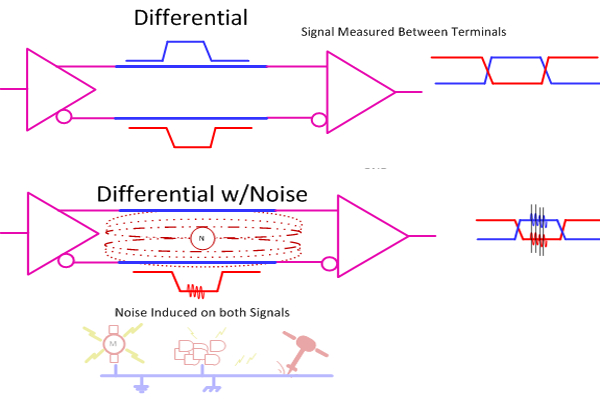
Говоря простым языком, дифференциальная пара — это два противоположных сигнала, положительный и отрицательный. Вы получаете логический уровень передаваемого бита путём сравнения этих двух сигналов друг с другом — вместо сравнения уровня каждого отдельного сигнала с землёй, как мы обычно делаем. Этот метод называется «асимметричной сигнализацией». В случае дифференциальной пары сигналы находятся близко друг к другу, а в кабелях даже переплетаются. В результате этого помехи воздействуют на них в равной степени — так как сигналы для получения информации сравниваются друг с другом, это означает, что накладываемый на оба этих сигнала шум на итоговую полученную информацию не влияет. Дифференциальные пары также обуславливают взаимное гашение магнитных полей обоих сигналов, что ведёт к уменьшению шумов на линии передачи.
В результате дифференциальные пары позволяют повысить скорость передачи, не создавая лишнего шума и не повышая восприимчивость к нему. По этой причине в подавляющем большинстве высокоскоростных интерфейсов используется именно эта технология: Ethernet, PCIe, HDMI, DisplayPort, LVDS и даже в USB, хотя USB2 всё же псевдодифференциален, а вот USB 3 уже в этом смысле полноценен. В отказоустойчивых интерфейсах вроде RS485 и CAN также используются дифпары. Любителю не составит проблем начать работать с этой технологией при реализации интерфейсов вроде CAN и даже USB2 — на коротких расстояниях они будут функционировать, несмотря ни на что, хотя в теории дифференциальные сигналы требуют особого подхода.
Тем не менее при разводке печатной платы или сборке кабеля дифпарам действительно необходимо уделять больше внимания. Если в таких случаях не проявить достаточно стараний, есть риск получить загадочные глюки или полностью нерабочие интерфейсы. В этой связи далее предлагаю разобрать все необходимые требования.
Во-первых, вам нужно держать оба сигнала дифпары рядом по всей их длине. Чем ближе они друг к другу, тем меньше воздействие внешних помех и уровень излучаемого ими шума. Учитывая, что зачастую несколько дифференциальных пар пролегают рядом, это также поможет сохранить целостными сигналы других дифпар. Что касается совместного прокладывания нескольких дифпар, их нужно будет отделить друг от друга и прочих компонентов — будь то заливка полигонами на том же уровне или высокочастотные сигналы. Хорошей практикой здесь будет следовать «правилу 5W», согласно которому между центром дифпары и другими сигналами должно быть расстояние, равное ширине минимум пяти дорожек. К сожалению, соблюсти эту рекомендацию не всегда возможно, но желательно к этому стремиться.
Правило 5W/5S
Перекрестные помехи являются фундаментальным аспектом целостности сигнала как в однопроводных, так и в дифференциальных трассах. Расстояние между сигнальными линиями при каждой конфигурации трассировки определяется с использованием типичных эмпирических правил, которые легко можно задать как правила проектирования в вашем программном обеспечении для проектирования печатных плат. Одно из эмпирических правил для определения расстояния между дифференциальными парами - это правило "5S", иногда называемое правилом "5W" в прикладных заметках и других руководствах по проектированию печатных плат.
Правило 5S гласит, что расстояние между двумя линиями дифференциальной пары должно быть в 5 раз больше ширины каждой трассы в паре. Когда требуется плотная трассировка для нескольких дифференциальных пар, перекрестные помехи между дифференциальными парами становятся важным фактором, и нам нужен способ анализа расстояния между дифференциальными парами. Как оказывается, это функция высоты пар относительно ближайшей земляной плоскости. Давайте более подробно рассмотрим этот вопрос и узнаем, как мы можем определить правильное расстояние между дифференциальными парами, чтобы предотвратить дифференциальные перекрестные помехи.
Как следует из названия, дифференциальный перекрестный помехи является аналогом однопроводного перекрестного помехи в дифференциальном режиме, относясь к формам перекрестных помех между дифференциальными парами или к перекрестным помехам, генерируемым на однопроводной дорожке дифференциальной парой. Два типа перекрестных помех, обнаруженных между однопроводными парами (NEXT и FEXT), также встречаются между дифференциальными парами. Сильные дифференциальные перекрестные помехи могут быть индуцированы как емкостным, так и индуктивным путем, в зависимости от частоты и геометрии структуры.
Общее поле, наблюдаемое на некотором боковом расстоянии от пары, является суммой полей от двух пар. Поскольку между двумя концами дифференциальной пары есть некоторое расстояние, общее поле, наблюдаемое на некотором боковом расстоянии от дифференциальной пары, не равно нулю. Более того, сила электромагнитного поля вдали от двух дорожек больше, когда расстояние между двумя дифференциальными парами больше.
Это побуждает к формулировке некоторого правила, которое используется для определения расстояния между дифференциальными парами. Исходя из вышеизложенного обсуждения, и просто зная, что сила поля уменьшается по мере удаления от пары, естественно сформулировать следующие требования к размещению дифференциальных пар:
Расстояние между двумя дифференциальными парами должно быть пропорционально расстоянию между каждой дорожкой в паре.
Расстояние между двумя дифференциальными парами должно быть в некотором отношении пропорционально расстоянию между каждой парой и ее опорной плоскостью (если таковая присутствует).
Давайте рассмотрим следующую геометрию для двух дифференциальных пар и определим дифференциальное перекрестное воздействие между ними. Вероятно, вы думаете, что вся суть дифференциальных пар заключается в подавлении шумов; хотя это и верно для общего режима шума, разница в силе поля между двумя дорожками в паре-жертве будет производить разные уровни шума в каждой паре, проявляясь как шум дифференциального режима на приемнике.
Differential crosstalk model between two pairs
Модель для изучения дифференциальной перекрестной помехи между двумя парами микрополосковых линий.
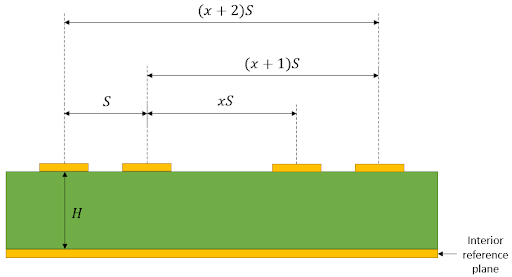
Используя параметры расстояния между дифференциальными парами, показанные выше, можно использовать два подхода для количественной оценки дифференциального перекрестного воздействия:
Модель, основанная на силе поля
В вышеупомянутом обсуждении не был рассмотрен еще один аспект: высота следа над его опорной плоскостью и точное расположение следов в паре. Подобные соображения могут быть применены и к дифференциальным парам в стриплайне. Здесь мы хотели бы количественно оценить силу дифференциальной перекрестной помехи как функцию геометрии. Подход, представленный здесь, тесно следует подходу, показанному Дагом Бруксом. Обычно это делается путем определения коэффициента перекрестной помехи из модели цепи. Проблема с этими моделями заключается в том, что они не учитывают силу поля на пострадавшем следе как функцию расстояния между агрессором и жертвой.
В вышеуказанной модели мы можем определить коэффициент перекрестной помехи C как функцию расстояния между следами S и высоты над опорной плоскостью H. Удобно определять коэффициент перекрестной помехи как функцию отношения (S/H). В этом случае коэффициент односторонней перекрестной помехи между двумя следами, разделенными расстоянием S с противоположной полярностью, составляет:
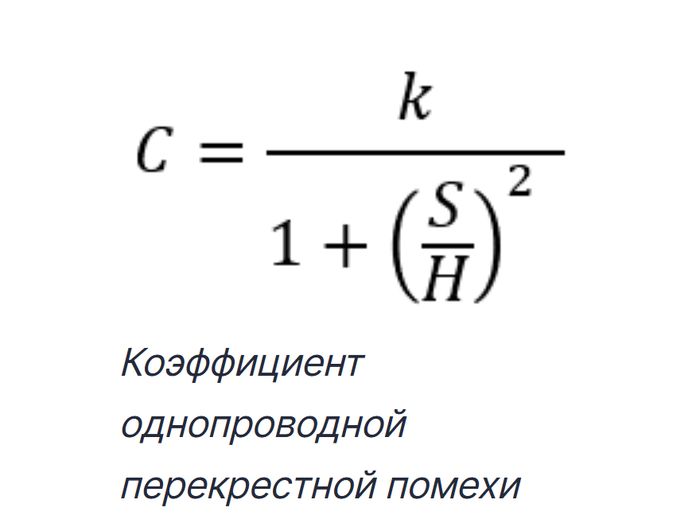
Здесь k является коэффициентом пропорциональности, который связан с временем нарастания сигнала на агрессивной линии, функцией передачи пострадавшей линии и диэлектрической постоянной подложки. Тот, кто проходил курс электромагнетизма, знает, что эта модель основана на силе электрического поля вокруг провода над проводящей плоскостью. Как мы скоро увидим, значение C может быть использовано для определения соотношения общего режима к дифференциальному помеховому шуму, генерируемому на пострадавшем следе для данного соотношения (S/H). Дифференциальный приемник устранит шум общего режима, поэтому мы хотели бы минимизировать шум дифференциального режима.
Дифференциальная перекрестная помеха определяется путем вычисления сумм и разностей в коэффициентах перекрестных помех. Для показанной выше конфигурации перекрестная помеха между одной дифференциальной парой и одним следом в пострадавшей паре является просто суммой их коэффициентов. Заметьте, что для любого значения расстояния между дифференциальными парами, просто примените масштабное преобразование S → S(1+x). Дифференциальная перекрестная помеха является просто разностью коэффициентов перекрестных помех для пострадавших следов:
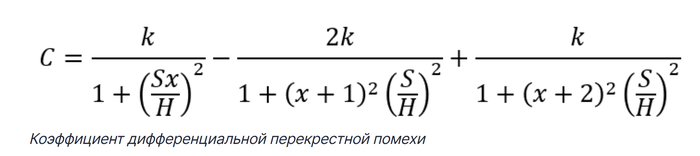
Если мы построим это как функцию от x для различных значений (S/H), мы обнаружим, что расстояние между двумя парами может быть уменьшено, когда дорожки расположены ближе к земляному слою. Ниже приведен такой график для k = 1; увеличение k просто перемещает эти кривые вверх по оси y. Это делается для удовлетворения определенного требования к дифференциальной перекрестной помехе. Например, предположим, что вам требуется коэффициент дифференциальной перекрестной помехи 0.002; если дорожки находятся дальше от ближайшего земляного слоя, тогда требуется большее расстояние, чтобы убедиться, что вы достигаете этой цели проектирования.
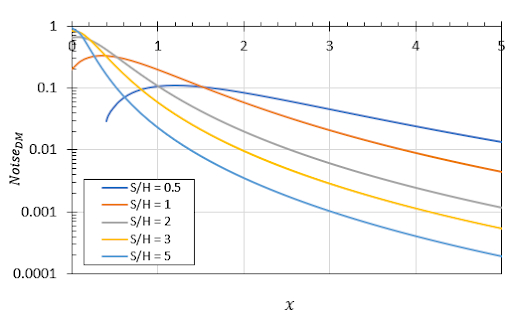
Коэффициент дифференциальной перекрестной помехи как функция расстояния между парами.
Также посмотрите, что происходит, когда (S/H) = 0.5; максимальный коэффициент перекрестной помехи не всегда возникает, когда x = 0. В зависимости от вашей цели проектирования, вы можете расположить дорожки ближе друг к другу и увидеть тот же уровень дифференциальной перекрестной помехи, как если бы дорожки были расположены дальше друг от друга.
Возможно, вы задаетесь вопросом: а что насчет ширины трассы? Ширина трассы важна, поскольку она определяет одиночный и дифференциальный импеданс, емкость и индуктивность. Для заданной спецификации дифференциального импеданса, изменение расстояния между парами дифференциальных трасс и толщины подложки заставляет изменять ширину трассы, чтобы поддерживать одинаковое значение импеданса нечетного режима.

Ещё есть один редко проговариваемый нюанс — согласование импеданса. Если вы проводите дифференциальную пару из точки А в точку В, то нужно обеспечить получение правильного импеданса, и добиться этого проще, чем может показаться.
Импеданс подобен сопротивлению, но относится к изменению сигналов. Каждая часть пути дифпары имеет собственный импеданс: приёмник и передатчик внутри используемой микросхемы, выводы микросхемы, дорожки печатной платы и все разъёмы или кабели между ними, если пара проводится через них. В любой точке, где импеданс сигнала меняется, часть этого сигнала отражается от точки несоответствия, и если изменение окажется достаточно значительным, это приведёт к искажению получаемого сигнала.
Итак, это подразумевает необходимость обеспечения правильного импеданса линии PCIe вдоль всего пути — что на практике означает подбор подходящих разъёмов, а также нужной ширины дорожек и отступов между ними. Оборудование PCIe в основном собирается с учётом импеданса 85 Ом. Такие компоненты, как приёмники, передатчики и соответствующие разъёмы находятся вне нашего контроля, и для получения достаточно однообразного импеданса вдоль всего пути необходимо подстраивать под одно значение те элементы, над которыми контроль у нас есть.
Для начала, если вам для линии PCIe нужны разъёмы, то выбирайте такие, которые будут иметь минимальное несоответствие импеданса. Хорошим вариантом будет использовать высокоскоростные модели или те, что собираются с учётом сигналов PCIe — полноразмерные PCIe, M.2, mPCIe, USB3, USB-C и много высокоскоростных семейств от разных производителей.
Наконец, следует отметить, что в вышеупомянутой модели отсутствует важный параметр: диэлектрическая постоянная. Значение диэлектрической постоянной также важно для влияния на дифференциальные перекрестные помехи, и это одна из причин, по которой конструкции высокой скорости выбирают материалы с более низкими значениями Dk в некоторых слоях. Чтобы увидеть влияние значения Dk на дифференциальные перекрестные помехи, вы могли бы попробовать вернуть значение Dk в вышеуказанную модель коэффициента перекрестных помех, или вам нужно было бы посмотреть на S-параметры для межсоединения, рассчитанные с помощью электромагнитного поля.
Когда вы используете решатель полей для расчета дифференциальной перекрестной помехи, вы будете использовать результаты во временной области (показывающие импульсы, поданные на пострадавший соединитель) и S-параметры для количественной оценки широкополосной дифференциальной перекрестной помехи. Первый метод является стандартным подходом к моделированию, который реализован в Altium Designer для однонаправленных трасс, но не для дифференциальных трасс. Второй метод может быть рассчитан только с помощью решателя электромагнитных полей.
На симуляционных результатах ниже я показываю набор кривых S-параметров, полученных с помощью Simbeor для двух коммерческих ламинатов (Megtron 7 и Megtron 8) на тонких слоях. Внутрипарный интервал был установлен равным ширине трасс в паре (S = W). Расстояние между парами по краю варьировалось от 1W, 2W и 3W. Толщина диэлектрика также варьировалась от 1,5 до 3 мил.
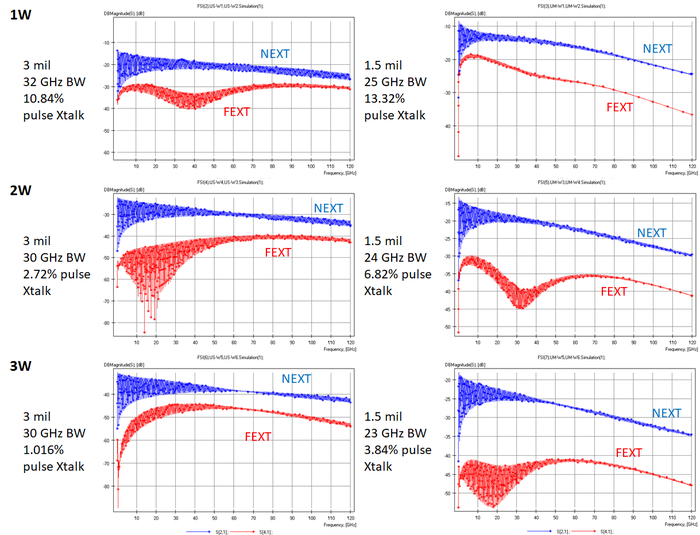
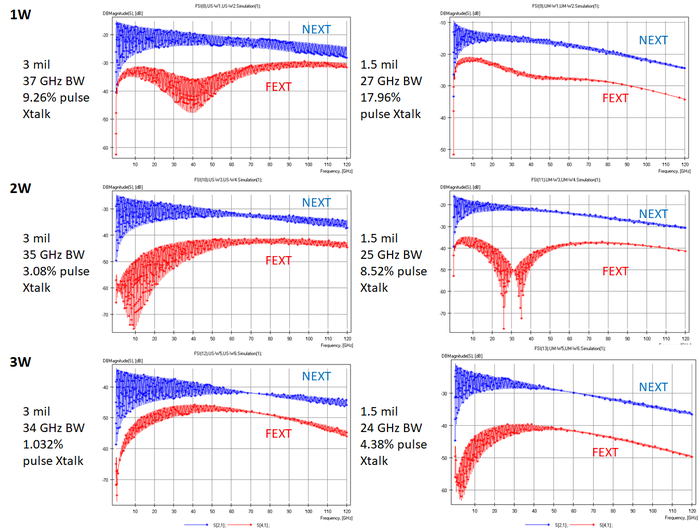
Результаты должны быть очень интересными, поскольку они показывают, что просто приближение земли к дифференциальным парам и сохранение того же краевого расстояния 1W и т. д. между дифференциальными парами не автоматически уменьшает перекрестные помехи. Это связано с тем, что сохранение 1W значительно уменьшает расстояние между парами. Однако переход от 1W/толщины 3 мил к 2W/толщине 1,5 мил всё же уменьшает перекрестные помехи и обеспечивает более высокую плотность трассировки. Это именно то, что нам нужно, если мы разрабатываем HDI-плату с большим количеством высокоскоростных интерфейсов, исходящих от основного процессора.
Мы можем увидеть это из простого расчета ширины трасс/расстояния в паре и значений расстояния между парами для ламинатов толщиной 3 мил и 1,5 мил.
3 мил Meg7 @ расстояние 1W, S/H = 0.75, и S = 2.249 мил
Изначально Xtalk = 10.84%
1.5 мил Meg7 @ расстояние 2W, S/H = 0.51, и S = 0.765 мил
Изначально Xtalk = 6.82%
Это означает, что плотность всё же увеличилась на 63%, даже при увеличении расстояния между парами до 2W. Если мы увеличим расстояние между парами до 3W, плотность трассировки всё равно значительно возрастет. Здесь есть еще один очень важный эффект, который хотелось бы подчеркнуть в приведенных выше данных: ограничение полосы пропускания. Определённое выше ограничение полосы пропускания видно на графике обратных потерь для соединений; когда обратные потери достигают -10 дБ, это определяется как предел полосы пропускания для канала. Мы можем видеть, что во всех вышеперечисленных случаях эффект ограничения полосы пропускания в каналах уменьшается при переходе к более низкому значению Dk. Причина этого проста: это вынуждает использовать более широкую ширину трасс, что уменьшает индуктивный вклад в импеданс и снижает реактивную часть импеданса линии передачи.
В некоторых случаях необходимо знать уровень шума в общей моде, создаваемого в дифференциальной паре из-за входного дифференциального сигнала на паре-агрессоре. Это можно рассчитать с использованием S-параметров в смешанном режиме для нашей указанной выше 4-портовой сети. Это расширяет количество портов в матрице S-параметров до 8-портовой сети, хотя только 4 из этих портов являются физическими входами и выходами. Такой набор S-параметров в дифференциальных каналах называется S-параметрами в смешанном режиме и описывает преобразование режимов внутри одной дифференциальной пары и между двумя дифференциальными парами.
Полная матрица S-параметров для дифференциальной пары, учитывающая сигналы в общей и дифференциальной моде, представляет собой матрицу 8x8, форма которой показана ниже:
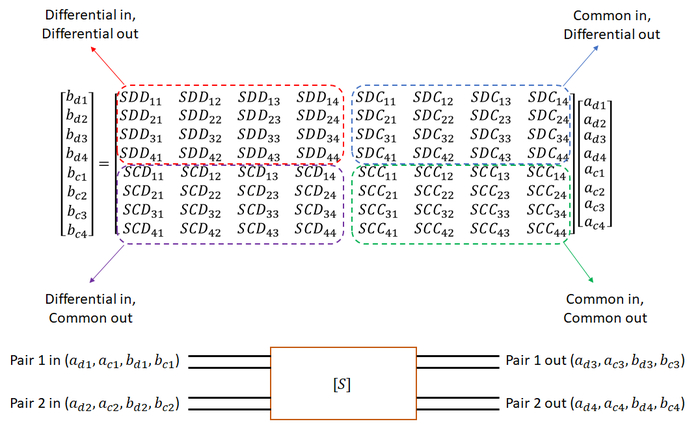
Матрица S-параметров в смешанном режиме, описывающая дифференциальные перекрестные помехи и преобразование режимов между двумя дифференциальными парами.
Это множество параметров для расчета в симуляции! Современные решатели полей в инструментах EDA могут выполнить этот расчет, анализируя сигнал, индуцированный в пострадавшей дифференциальной паре, путем вычисления вклада от каждой однонаправленной трассы в дифференциальной паре-агрессоре. Матрица выше описывает как FEXT, так и NEXT, наряду с преобразованием режимов (например, FEXT, видимый как общая мода при возбуждении входным дифференциальным сигналом).
Дифференциальные перекрестные помехи создают шум в дифференциальном режиме и шум в общем режиме на пострадавшей паре
В некоторых случаях минимизация шума в общем режиме может быть более важной для целей ЭМС
Увеличение расстояния между трассами в дифференциальной паре пострадавшей пары наиболее эффективно для обеспечения доминирования перекрестных помех в дифференциальном режиме
В некоторых случаях минимизация шума в дифференциальном режиме может быть более важной для снижения ИСИ
Уменьшение расстояния между трассами в дифференциальной паре пострадавшей пары наиболее эффективно для обеспечения доминирования перекрестных помех в общем режиме
Перейдём к настройке импеданса дорожек печатной платы. Импеданс дифпары зависит от множества переменных факторов, но если вы начинающий электронщик, то существуют упрощённые калькуляторы — (Например: Impedance-Calculator). Промотайте вниз до пункта «Edge-Coupled Surface Microstrip», для прокладки дифпар на слоях толщиной в 35 мкм укажите высоту дорожки 35, а диэлектрическую константу установите на 4,3, если только производитель платы не рекомендует другое значение.
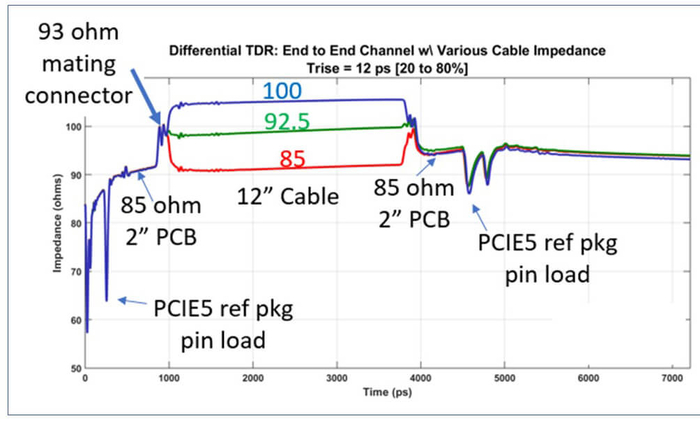
Затем установите толщину изоляции равной расстоянию от дифпар — чтобы его узнать, загляните в раздел документации платы, где описана структура её слоёв. Предположим, ваши дифпары находятся на верхнем слое, и земля проходит по слою под ними. В таком случае ищите толщину «prepreg» между верхним слоем меди и слоем под ним — это значение и будет высотой изоляции. Далее поиграйтесь с шириной дорожек и отступами между ними, стремясь получить сопротивление 85 Ом. В спецификации допускается диапазон от 70 до 100 Ом.

Вот вам практическое упражнение — давайте заглянем в структуру 4-слойной платы OSHPark. Её диэлектрическая константа (dk) равна 3,6, а минимальная ширина дорожек и отступы равны 5 mil, то есть 0,127 мм, или 127 мкм для калькулятора; толщина препрега равна 202 мкм. Введите диэлектрическую константу и толщину препрега в калькулятор и поэкспериментируйте со значениями.
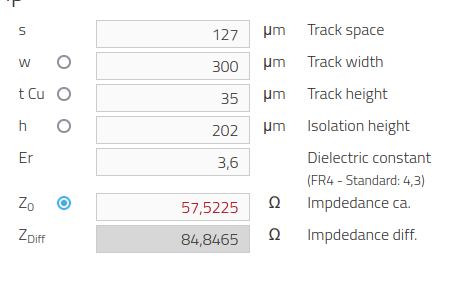
Вы обнаружите, что увеличение ширины дорожки, равно как и уменьшение отступов, ведёт к уменьшению импеданса — установите его на минимально возможное. Вы увидите, что при стремлении к 85 Ом вам нужно использовать пары 0,3/0,127 (ширина/отступы) — это даст 84,8 Ом. Если же вы не можете позволить себе такую ширину дорожек, то используйте 0,2/0,127 — это даст импеданс 106 Ом, который несколько выходит за допустимый диапазон, но при необходимости тоже сгодится.
И последнее — разводите дифпары без лишних манёвров. По возможности не проводите их через отверстия на другие слои — каждая пара отверстий внесёт в сигнал индуктивность, которая может создать помехи для высокоскоростных сигналов. Как правило, начальная и конечная точки линии PCIe находятся на верхнем слое — желательно так всё и оставить. Если есть необходимость перейти на другой слой, добавьте возле дифференциальных пар заземлённые отверстия. Кроме того, удерживайте другие высокоскоростные, быстро меняющиеся либо шумные сигналы как можно дальше от них. Если в ваших проектах наряду с дифпарами также используются высокомощные и асимметричные соединения, то первыми прокладывайте именно дифпары.
Итак, пять важных моментов — прокладывайте дифпары близко друг к другу, размещайте под ними заземление, используйте подобающие коннекторы, подбирайте ширину их дорожек и отступы для получения нужного импеданса, а также делайте разводку без лишних манёвров. Всё это основы, которым необходимо следовать, если вы хотите, чтобы дифференциальные пары в дальнейшем выполняли свою роль достойно.
Если вам доводилось работать с PCIe, ты вы могли открыть для себя одно тайное знание: оказывается, что на практике всё вышеперечисленное проделывать не обязательно.
Возможно, вы слышали, что PCIe работает даже по «мокрой верёвке» (в оригинале wet string — прим. пер.) — впервые так её охарактеризовали на Всемирном конгрессе хакеров 2016 года, 33c3. Это эдакий хакерский способ описывать работу PCIe — вы можете не соблюсти многие из вышеназванных пунктов при подключении двух устройств PCIe, но соединение всё равно заработает. И, что неудивительно, в этом есть крупное зерно истины — PCIe способен работать в субоптимальных условиях, что подтверждается множеством примеров как в мире электронщиков, так и в среде потребителей.

Пожалуй, наиболее доступный пример — это передача сигнала PCIe 1x с помощью USB3, как в использующихся для майнинга райзерах PCIe. Это означает, что вы можете просто зайти в магазин компьютерных аксессуаров и купить продукт, который появился лишь вследствие нарушения правил эксплуатации технологии PCIe.
Ещё один случай, с которым вы могли столкнуться и забыть как страшный сон — это прокладка линии PCIe 8х с помощью, содрогнитесь, проводов для прототипирования. Таким образом Toble_Miner тестировал идею создания переходника для дешёвых высокоскоростных сетевых карт с серверов HP, несовместимых со стандартными слотами PCIe как по распиновке, так и механически. Такая конфигурация для прототипирования позволила ему спроектировать подходящую версию переходника.

Вы вполне можете наспех проложить линию PCIe через кабель FPC, соединив таким небрежным образом две платы. Аналогичный вариант реализовывался в расширителях eGPU с помощью кабелей HDMI, и его также наверняка можно реализовать с помощью обмоточного провода, в котором расширители PCIe соединяли цепочкой, которая успела достичь 5 метров, пока соединение не начало утрачивать стабильность.
PCIe является более снисходительным интерфейсом в сравнении с некоторыми другими, например, с USB3. В нём присутствует механизм подстройки соединения — после установки подключения PCIe приёмник и передатчик перебирают внутренние параметры, корректируя их до тех пор, пока не достигнут максимально возможной скорости при низком уровне ошибок. Далее найденные параметры используются на протяжении всего времени подключения. Также в этом интерфейсе присутствует повторная передача неполученных пакетов. На практике PCIe отличается исключительной стабильностью.
Очевидно, что подстройка соединения PCIe имеет свои уникальные особенности — к примеру, для большего удобства при проектировании платы этот интерфейс также позволяет инвертировать любую дифференциальную пару, за исключением REFCLK, поменяв отрицательный и положительный сигнал местами, что обнаруживается и полноценно компенсируется во время подстройки. Прочие технологии вроде USB3, HDMI или DisplayPort не поддерживают подобные фичи, облегчающие жизнь инженера. В других интерфейсах зачастую требуется, чтобы несколько линий имели одинаковую длину — чтобы данные, передаваемые по одному комплекту дифпар, не прибывали быстрее передаваемых по другому. При этом PCIe отлично работает при расхождении длины дифпар, также обнаруживая и компенсируя это расхождение во время подстройки соединения. И хотя эти особенность больше служат в целях облегчения проектирования печатных плат, нежели отвечают за отказоустойчивость, их наличие определённо помогает.

Помогает ли такая отказоустойчивость электронщикам? Безусловно — эти две особенности используются, по сути, в любой профессиональной схеме PCIe, и если вы находитесь в неидеальных условиях, то можете на свой страх и риск выжать из PCIe ещё больше. С другой стороны, не стоит пренебрегать каждым правилом, только потому что кто-то так делает — приложите усилия к соблюдению пяти описанных пунктов, даже если вы ограничены двухслойной платой и никак не можете получить идеальное значение импеданса.
Следование этим правилам не только научит вас дисциплине использования дифференциальных пар для будущих проектов, но также позволит добиться большей устойчивости сигналов, сократит число ошибок и порадует ваши устройства PCIe. Пренебрежение некоторыми или даже всеми из перечисленных руководств может быть уместным, поскольку в определённых случаях вполне сработает, но затрата лишних тридцати минут на вычисление подобающего импеданса поможет исключить необходимость проектирования второй ревизии вашей платы и обеспечить её исправную работоспособность на протяжении всего срока службы.
Так что вот вам общий принцип: относитесь к дифференциальным парам PCIe с уважением. Если вы используете двухслойную печатную плату и собираете дешёвый прототип, желая поскорее получить результат, не следует просто пренебрегать импедансом из-за того, что для получения 85 Ом дорожки придётся сделать слишком широкими. Откройте калькулятор и просчитайте, насколько можно снизить значение импеданса. Уменьшение толщины изоляции ведёт к снижению импеданса, так что рассмотрите вариант с использованием платы 0,8 мм, если механические особенности проекта это позволяют. Попробуйте разное расположение компонентов в поиске более удачного пути для дорожек PCIe с меньшим уровнем шума. Возможно, подстройка соединения снизит характеристики неидеального подключения на одно-два поколения, но это лучше, чем совсем не получить стабильного соединения. Максимально постарайтесь следовать этим правилам при имеющихся ресурсах, и дифференциальные пары ответят на ваше уважение взаимностью.

Тестирование видеокарты MSI GeForce RTX 4060 Ti Gaming X Trio 8 Гб проводилось на следующей конфигурации:
Процессор: Intel Core i9-13900K;
Охлаждение: ID-Cooling ZOOMFLOW 360 XT
Термоинтерфейс: Arctic MX-4;
Материнская плата: ASUS ROG MAXIMUS Z690 APEX;
Память: 2 x 16Гб DDR5-6400, Team (SKhynix);
Видеокарта: MSI GeForce RTX 4060 Ti Gaming X Trio 8 Гб (2310 / 2670 / 2250 МГц (ядро/boost/память));
Накопитель: Samsung PM9A1 1Тб;
Блок питания: XPG CyberCore 1300W, 1300 Ватт.
Температура в помещении находилась на уровне 22°C, уровень шума составлял 27.1 дБ.
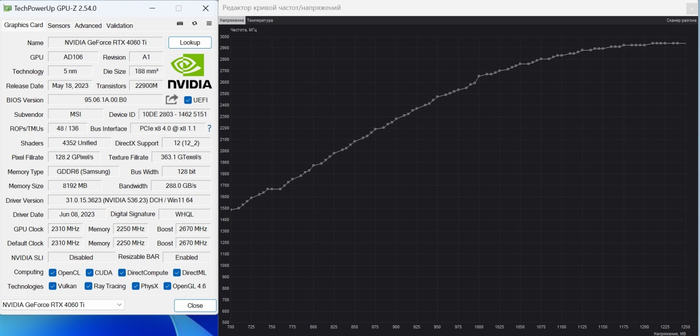
При внешнем осмотре карты можно было упустить ряд важных моментов, о которых нам рассказывают утилиты. Все они грустные. Начнём с интерфейса подключения. Теперь это PCI-e x8 Gen4, как на RTX 3050. Причём при взгляде на разъём это можно заметить по отсутствию дорожек к половине контактов.
Это мелочи потому, что, по сути, перед нами пропускная способность PCI-e x16 Gen3. Куда важнее, что шина памяти всего 128 бит, как на GTX 1650. Её пропускная способность оказывается очень маленькой для карты среднего уровня и почти вдвое меньше чем на RTX 3060Ti. И раз уж речь зашла о сравнении с RTX 3060Ti, то ещё снизилось количество CUDA ядер.
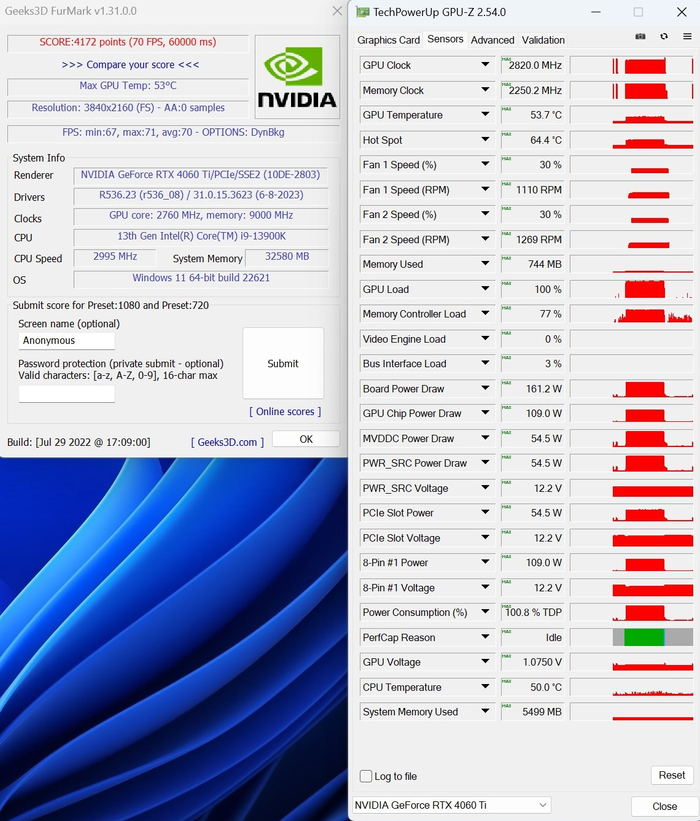
При отсутствии нагрузки вентиляторы здесь останавливаются. Такая схема используется не впервые и большой массивный радиатор может справиться даже с мощным чипом в пассиве, если частоты его падают до 300 МГц. При достижении 50°C вентиляторы запускаются. На 100% мощности вентиляторы раскручиваются до 2800 об/мин, шум при этом составляет 48 дБ с расстояния 1 м. В «бублике» вентилятор работает только на 30% от полной мощности, что составляет 1100 об/мин. Даже в таком режиме получается приемлемый уровень шума – 32,4 дБ на расстоянии 30 см. В «волосатом бублике» карта потребляет около 162 Вт. Это не мало, но смотря с чем сравнивать.
Сверху кожуха предусмотрена небольшая вставка с RGB-подсветкой двух логотипов. Также есть ещё два модуля с RGB-подсветкой спереди на кожухе. Подсветка настраивается через приложение MSI Center. Режимов работы очень много, можно всё настроить на свой вкус. Также есть синхронизация подсветки с материнской платой.
Пора переходить к тестированию.
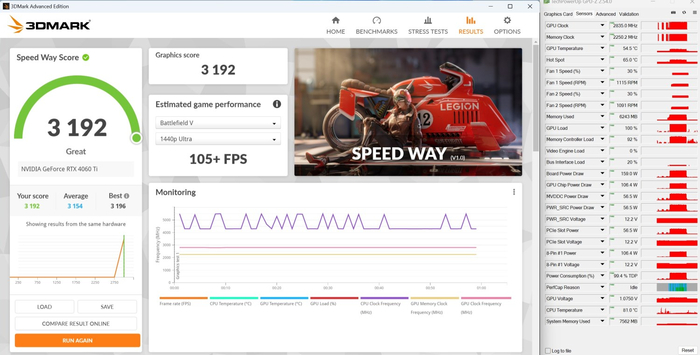
3DMark Speed Way:
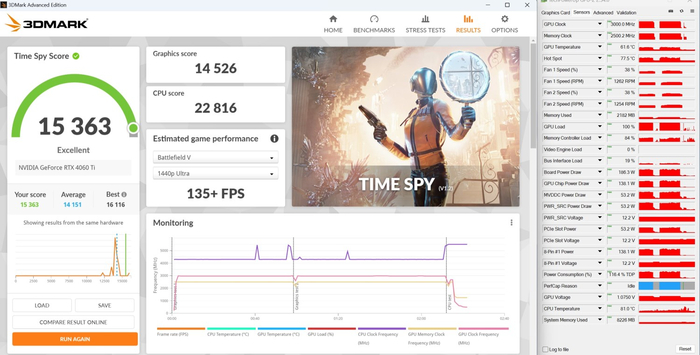
3DMark Time Spy:
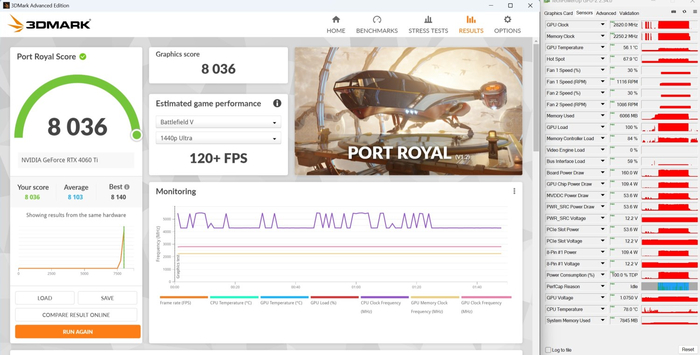
3DMark Port Royal:
Superposition FHD Medium:

Superposition FHD High:

Superposition FHD Extreme:

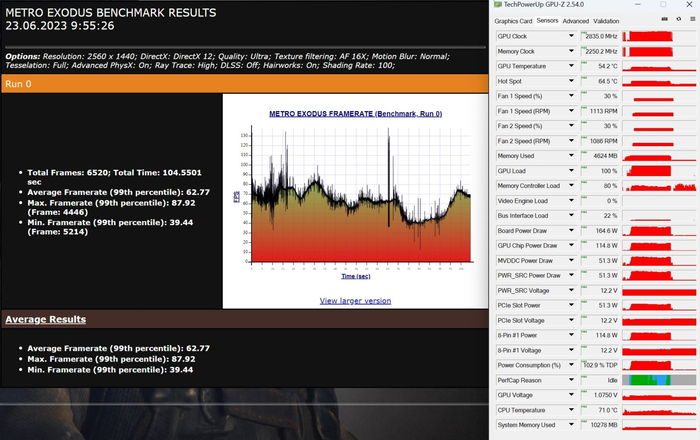
Metro Exodus FHD, RTX:
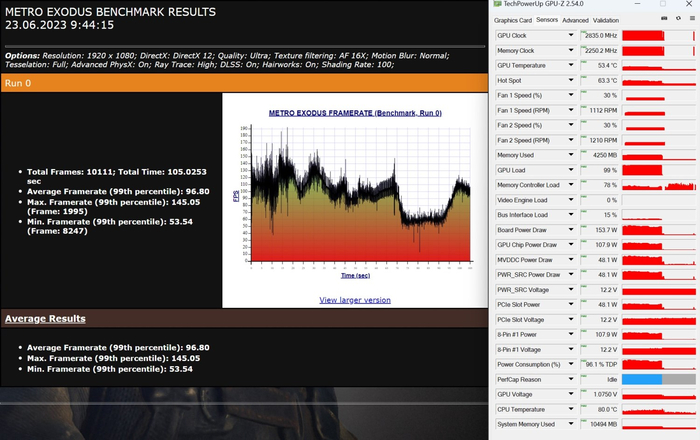
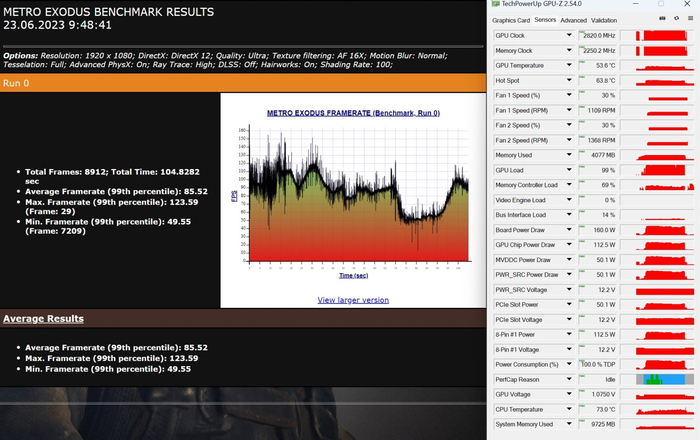
Metro Exodus FHD, RTX, DLSS OFF:
Metro Exodus QHD, RTX:
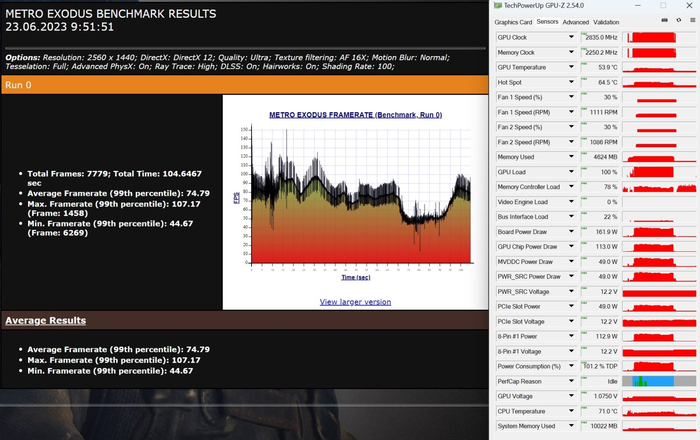
Metro Exodus QHD, RTX, DLSS OFF:
Cyberpunk 2077, FHD, трассировка минимальная:

Cyberpunk 2077, FHD, трассировка минимальная, DLSS OFF:

Cyberpunk 2077, QHD, трассировка минимальная.
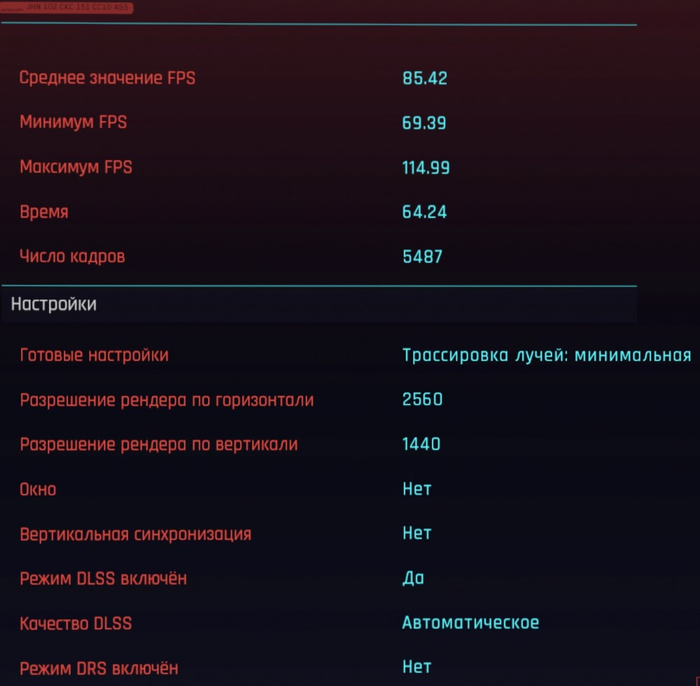
Разгон у видеокарты есть, причём неплохой. Она может легко уйти за 3 ГГц по чипу и при этом потребление может достигать практически 230 Вт. Именно поэтому здесь система охлаждения вполне соответствует.
При обычной игровой эксплуатации я бы всё же не разгонял карту потому, что нагрузка на VRM вырастает, а «выхлоп» на 5-10%. Однако здесь каждый будет решать сам.
3DMark Speed Way:
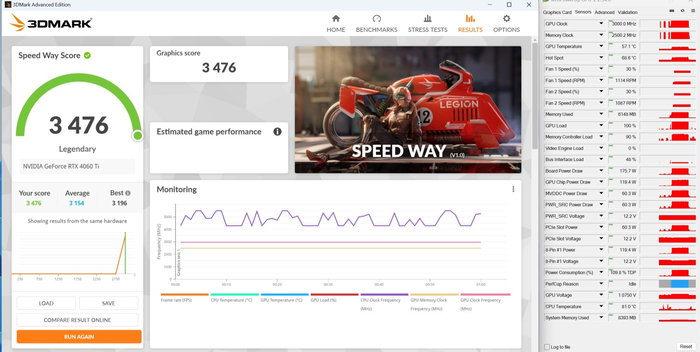
3DMark Time Spy:
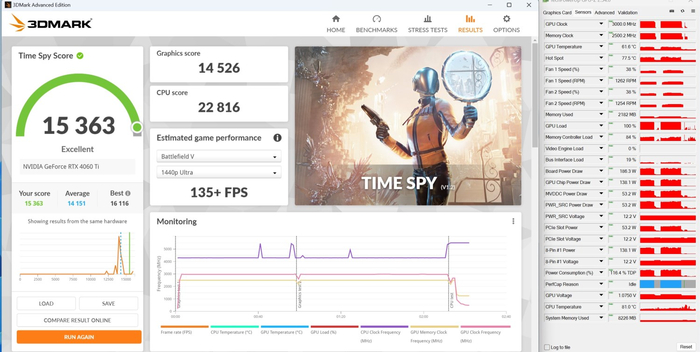
Superposition FHD High:

Metro Exodus FHD, RTX:
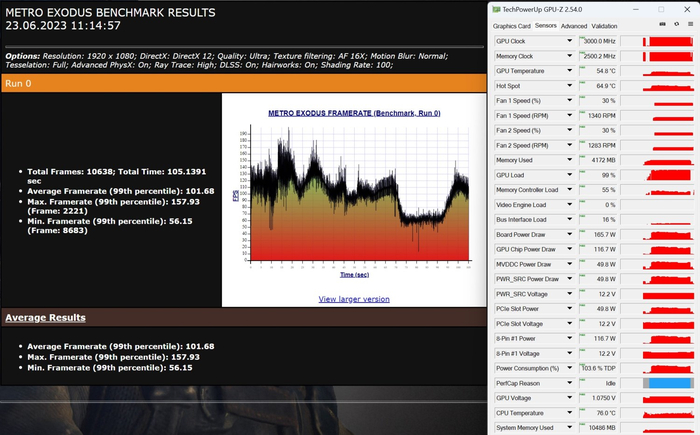
Metro Exodus QHD, RTX, DLSS OFF:
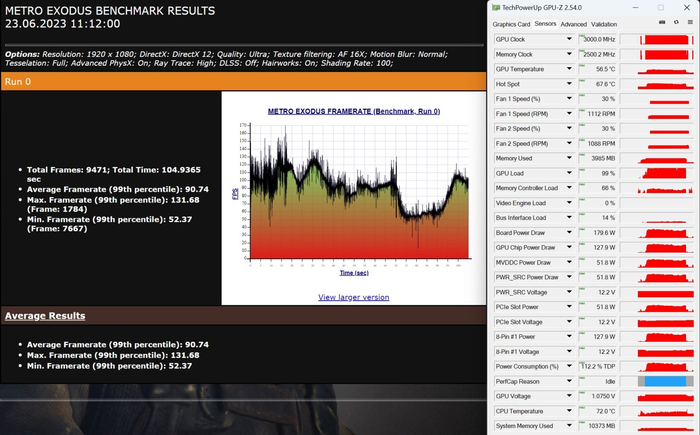
В плане производительности карта находится на уровне RTX 3060 Ti и этому есть очевидные объяснения. Достаточно вспомнить про пропускную способность памяти. Я уже даже не говорю про её объём.
Посмотрим теперь на нагрев карты во время интенсивной нагрузки.
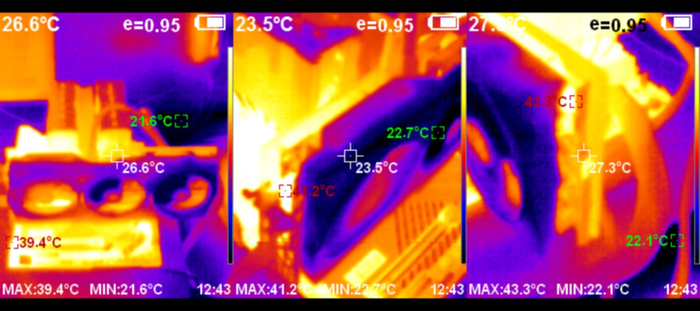
Каких-то высоких показателей температуры нет, и это объясняется габаритной системой охлаждения, которая обеспечивает низкую температуру и маленький уровень шума.
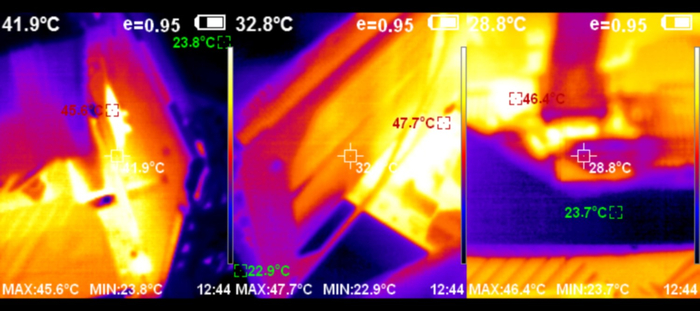
MSI RTX 4060Ti Gaming X Trio – это яркий представитель своего поколения видеокарт, основанных на графическом процессоре AD106. Картина чем-то напоминает MSI GeForce RTX 4070 Gaming X Trio потому, что там тоже была достаточно компактная плата и крупная система охлаждения. Большой кулер – это хорошо, но и здесь нужна мера. Карту же нужно размещать в корпусе и с более компактным устройством проблем меньше. Здесь кулер огромный, поэтому эта и без того не очень мощная карта получилась тихой и холодной. Печатная плата и подсистема питания полностью соответствуют потребностям графического процессора. Может всё показаться сильно упрощённым, но это так и задумывалось. Тем не менее, чип можно разогнать до 3 ГГц и даже заметно поднять частоту памяти, но всё это не сильно спасает. Играть уверенно можно только в разрешении FHD. В QHD нужно уже включать DLSS или играться с настройками качества картинки.
Больше всего вопросов не к самой карте потому, что она сама по себе сделана отлично, а к компании NVIDIA. Было бы отлично, если б этот комплект чипа и памяти назывался RTX 4050 и стоил в два раза дешевле, чем7продаются RTX 4060Ti. Тогда вопросов бы никаких не было, а NVIDIA можно было бы только поздравить.
Однако мы видим абсолютно другую картину, и у многих она вызывает недоумение. CUDA ядер стало меньше, шина памяти 128 бит, интерфейс PCI-e x8 – это всё элементы бюджетного решения, но никак не карты среднего уровня. Благодаря этому производительность фактически осталась на уровне RTX 3060 Ti, а стоимость заметно увеличилась.
Кроме этого, на вторичном рынке сейчас великое множество карт прошлого поколения и поэтому неудивительно, что наблюдается очень маленький спрос на карты 4000-серии среднего уровня. Тем более что на рынок вышли флагманские карты 5000-серии.

Видеокарты среднего ценового сегмента наиболее популярны среди игроков. Они обеспечивают хорошую графику при относительно невысокой стоимости. Среди моделей NVIDIA к таким картам относятся модели серии x060.
Пожалуй, лучшая реализация RTX 4060 Ti. Она работает практически без звука. Даже под полной нагрузкой уровень шума от карты не превышает 23.3 дБА. При этом модель остается довольно холодной — 56 °C на чипе и 64 °C в точке Hotspot. Секрет кроется в грамотном охлаждении чипа. Его реализуют пять тепловых трубок, габаритный радиатор и три вентилятора.

Подсистема питания графического чипа состоит из восьми фаз. Для ГП данного класса это солидный запас, даже с учетом разгона. В нем можно добиться неплохих результатов благодаря повышению лимита энергопотребления на 22 %.
Подсветки немного: наклонные полосы возле центрального вентилятора и логотип компании на торце. Видеокарта занимает два с половиной слота в системном блоке. Единственный минус — большая длина, целых 33 см. Перед покупкой убедитесь, что она влезет в корпус вашего ПК.

Габариты видеокарты составляют: 338 х 141 х 52 мм, вес – 1167г. Для сравнения те же характеристики у версии MSI GeForce RTX 4070 Gaming X Trio: размеры -– 338 х 141 х 52 мм, а вес – 1214г.

Карта по габаритам как более старшая версия, но по весу немного легче и это легко объяснимо, ведь памяти на два чипа меньше (и не только это). Все разъёмы задней панели и сам разъём PCI-e x16 закрыты чёрными пластиковыми заглушками.

Во внешнем оформлении мы видим узнаваемые черты. Схожим образом реализована подсветка на кожухе. Здесь, наконец, исчез разъём питания 12VHPWR, который используется на старших адаптерах. Вместо него всего один коннектор 8-pin PCI-e.
Карта занимает больше двух слотов расширения. Для усиления жёсткости конструкции в комплекте поставляется специальная стальная пластина, окрашенная в чёрный цвет.

Сзади видеокарты мы снова видим защитную пластину («бекплейт»). Она также выполняет функцию теплоотвода. Кроме этого, не ней заметны огромные прорези для того, чтобы воздух проходил радиатор насквозь свободно. Это свидетельствует о том, что сама печатная плата короткая и меньше участвует в распределении тепла.
Защитной плёнки снаружи нет, но она есть внутри. Термопрокладок тоже нет потому, что память GDDR6 холоднее, чем GDDR6X.

С обратной стороны платы мы можем заметить ШИМ-контроллер, а сама плата короче системы охлаждения больше чем в два раза. Танталовых конденсаторов в большом количестве на плате нет. Они твердотельные капсульные и все находятся спереди.

Кулер снимается очень просто. Для этого нужно сначала снять заднюю пластину, а затем открутить специальную монтажную рамку на четырёх винтах. После этого снимается кулер. Никакой дополнительной рамки спереди больше нет.
Сам кулер изготовлен по классической схеме. Две секции и пять тепловых трубок. За теплоотвод отвечает обычная медная никелированная пластина. Графический процессор контактирует с ней напрямую через термопасту, а с микросхемами памяти через термопрокладки.

Далее уже от теплосъёмной пластины расходятся тепловые трубки и пронизывают два массива алюминиевых рёбер радиатора. Трубки медные, никелированные диаметром 6 мм.

Сами пластины тоже достаточно крупные и их много. Поэтому радиатор очень похож на тот, что используется в MSI GeForce RTX 4070 Gaming X Trio, особенно это заметно по толщине. Все элементы здесь также пропаяны.
Акцент сделан на эффективность и возможность отвода большого количества тепла. Здесь это сделано с огромным запасом. В спецификации указано 160 Вт, а в BIOS стоит лимит на 195 Вт. Производитель похоже подгонял размеры кулера под стоимость устройства потому, что чувствуется солидный запас по мощности теплоотвода.

Пластиковый кожух чёрный с серыми вставками. Он крепится шестью винтами к специальным креплениям на радиаторе спереди. Если вы думаете, что вентиляторы крепятся к кожуху, то это не так. Здесь они также напрямую крепятся к специальным монтажным приспособлениям на радиаторе.

Кулер достаточно тихий и производительный. Здесь используются три вентилятора Power Logic PLD10010S12H с техническими характеристиками 12 В, 0.40 А. Максимальная скорость 2800 об/мин, а шум на расстоянии 1 м – 48 дБ.

Да, это немало, но обеспечивает сильный воздушный поток и солидный запас по мощности, ведь вертушки в нагрузке трудятся приблизительно на треть от максимальной мощности. Они также оборудованы специальной крыльчаткой TORX FAN 5.0. Спереди на всех есть серебристые наклейки с драконом MSI Gaming.

Судя по заявлениям производителя, они обеспечивают больший поток при той же скорости вращения и уровне шума. И это хорошо потому, что рёбра у радиатора расположены очень плотно друг к другу.

Над радиатором тоже поколдовали и верхние грани пластин выполнены волнообразно и расположены со сдвигом. Получается, как бы чешуя и сквозь не воздушный поток легче проникает и шума меньше.
Транзисторные сборки и катушки также охлаждаются этим радиатором, для чего на пластинах изготовлены специальные площадки, а в качестве термоинтерфейса выступает терморезинка.

Никакой дополнительной рамки тут нет. Память GDDR6 не такая прожорливая и поэтому питание для неё достаточно скромное. Поэтому мы видим всего одну фазу.

Слева находятся линии питания GPU, которых здесь также восемь, как на MSI RTX 4070 Gaming X Trio. Логику производителя понять можно. Чип потребляет меньше, значит и питание можно упростить, а если всё не такое горячее, то можно уменьшить печатную плату и сделать её более компактной.

ШИМ-контроллер распаяны сзади. Это та же самая микросхема uPI Semi uP9512R.

На каждую фазу приходится по одной транзисторной сборке ON Semiconductor NCP302150 на 50А и одной ферритовой катушке индуктивности. Силовые элементы распаяны все и пустых мест нет.

По центру размещен графический процессор NVIDIA AD106-350-A1, он же RTX 4060 Ti. Чип изготовлен на 50-й неделе 2022 года, но в NVIDIA долго думали над конечным продуктом. Это 188 кв. мм выполненных по 5 нм техпроцессу TSMC.

Четыре микросхемы памяти типа GDDR6 распаяны только спереди. Пустых мест нет и в BIOS платы не упоминаются более ёмкие чипы.

Используются микросхемы производства компании Samsung. Дополнительное питание подаётся на видеокарту через обычный разъём 8-pin PCI-e.

На задней панели расположен классический набор видеовыходов.

3x - Display Port;
1x – HDMI 2.1.
Ещё одна важная деталь. На этой видеокарте отсутствует переключатель двух режимов работы устройства: тихий и игровой.

PCI-Express — высокоскоростная шина обмена данных, без которой не обходится ни один компьютер на протяжении вот уже полутора десятка лет. За какие соединения отвечают ее линии, на что они влияют, и как создать правильную конфигурацию без узких мест?
Изначально главной целью внедрения PCI-E в пользовательские компьютеры была замена устаревшего интерфейса AGP для коммутации с видеокартой — самым требовательным к пропускной способности шины компонентом. Но этим ее сфера применения не ограничилась. В современных ПК шина используется практически повсеместно — для видеокарт, для других плат расширения, для скоростных накопителей, для связи процессора с чипсетом, для коммутации с высокоскоростными портами и дополнительными чипами встроенных устройств на материнской плате.
Шина PCI-E масштабируется с помощью линий. В персональном ПК таких линий на связь с одним устройством может выделяться от 1 до 16, в зависимости от нужной пропускной способности. Линии PCI-E — связующие «нити» в работе всех компонентов современной системы. Именно поэтому любой платформе важно иметь достаточно таких «нитей» для поддержания необходимой скорости обмена данными между всеми компонентами ПК
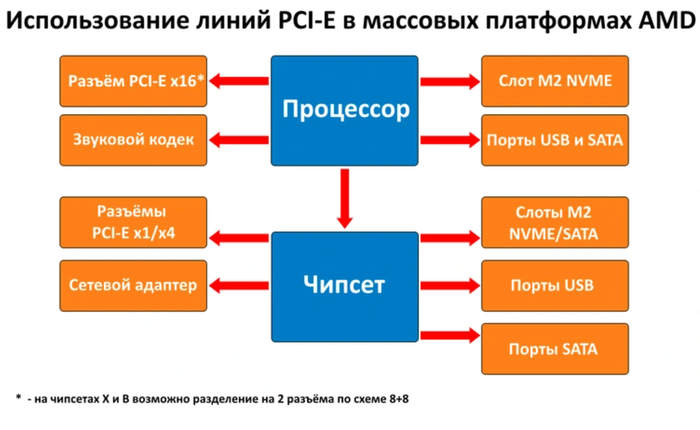
На заре становления PCI-E его коммутации с компонентами системы проходили через северный и южный мосты, которые представляли собой отдельные микросхемы на материнской плате. Для передачи данных процессору северный мост соединялся с ним по собственному каналу. В современных платформах северный мост интегрирован в процессор, по этой причине коммуникация с самым важным потребителем линий PCI-E — видеокартой — у всех современных ЦП осуществляется напрямую. Помимо выделенных линий для видеокарты, у большинства актуальных процессоров имеются отдельные линии для подключения NVME SSD.
Напрямую с ЦП по линиям PCI-E общается и чипсет (в прошлом — южный мост), находящийся на материнской плате. Он играет роль коммутатора, через который проходят данные от всех периферийных устройств, за исключением слота видеокарты и первого слота для NVME SSD на некоторых чипсетах. Общее количество линий, которое способна предложить система, складывается из линий процессора и линий чипсета — то есть, именно комбинация процессора и материнской платы определяет, сколько свободных линий PCI-E будет доступно пользователю. Однако стоит учитывать еще и скорость связи чипсета с процессором: она меньше пропускной способности линий чипсета, поэтому задействовать все их одновременно без потерь производительности просто не удастся.
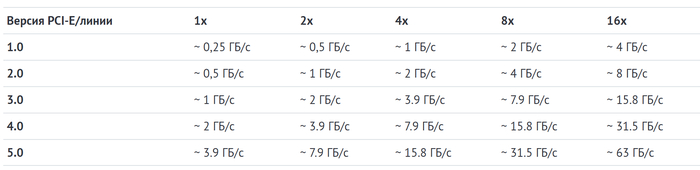
В отрыве от количества линий есть еще и другая характеристика — версия PCI-E. На данный момент существуют пять поколений шины, каждая из которой отличается от предыдущей удвоением пропускной способности. В одной системе для разных внутренних соединений могут использоваться разные версии протокола.
В массовых платформах 16 линий от процессора идет на слот для видеокарты. Платы на флагманских чипсетах позволяют «расщепить» его на несколько слотов по 4 или 8 линий на каждый. Еще 4 линии от процессора подключаются к слоту M2 NVME для высокоскоростных накопителей, но такой «прямой» слот встречается не везде. 4 или 8 линий используются для подключения процессора к чипсету на материнской плате. Чипсет распределяет их пропускную способность между разъемами USB, SATA и распаянными на материнскую плату контроллерами — такими, как звуковой чип, сетевой контроллер или дополнительный контроллер USB/SATA/Thunderbolt, если он имеется.
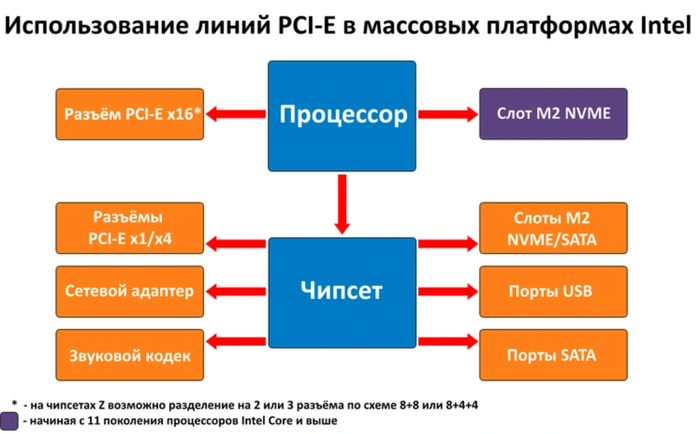
Оставшиеся после этого распределения линии идут на слоты для накопителей M2 NVME, если они присутствуют — по 4 на каждый, и на слоты расширения PCI-E. Обычно на них выделяется 1 или 4 линии.
Такое устройство имеют платформы Intel, процессоры которой для коммутации с большинством устройств полагаются на возможности чипсета. Платформы AMD в этом плане немного отличаются, так как процессоры семейства Ryzen — это системы на чипе (SoC), которые кроме видеокарты и NVME SSD имеют прямое подключение к некоторому количеству портов USB, SATA и звуковому кодеку.
Особняком стоят HEDT-платформы обоих вендоров. В общем плане они не отличаются от массовых, но могут предложить пользователю до 64 свободных линий PCI-E напрямую от процессора. Эти линии можно гибко конфигурировать для видеокарт, слотов M2 NVME и прочей скоростной периферии.

До 6 поколения Intel использовала линии PCI-E 3.0 только для соединения процессора с видеокартой, в прочих случаях ограничиваясь PCI-E 2.0. Первой ласточкой полного перехода соединений на PCI-E 3.0 стал чипсет Z170, выпущенный в 2015 году для 6 поколения Intel Core.
Процессоры этого поколения имеют 16 линий PCI-E 3.0 для видеокарты и соединяются с чипсетом посредством шины DMI 3.0 x4, которая базируется на той же версии PCI-E. Выделенной линии для накопителя NVME еще нет, для них используются линии от чипсета. Старший чипсет Z170 обладает 20 линиями третьей версии скоростного интерфейса, следующий за ним H170 — 16 линиями. У B150 12 линий, у младшего H110 — только 6. Платы на старшем чипсете умеют разделять слот видеокарты x16 на два слота по x8, или на три по схеме x8+x4+x4. Эта особенность сохранится и у всех последующих чипсетов Z-серии.
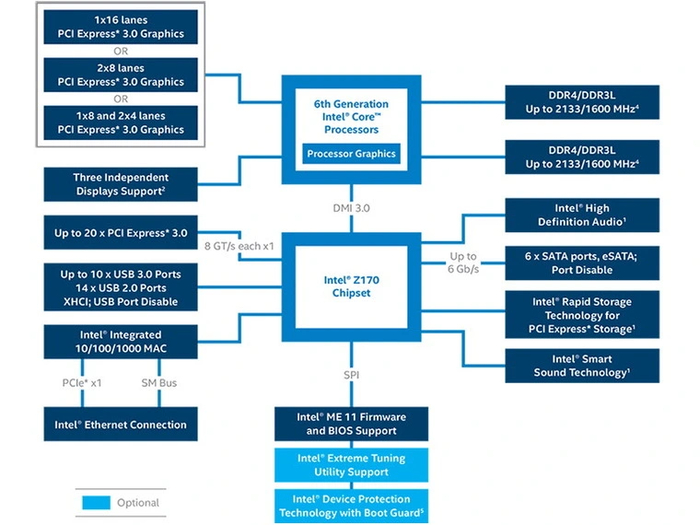
Увидевшие свет процессоры 7 поколения в этом плане изменений не получили, а вот возможности чипсетов для них немного расширились. У Z270 стало 24 линии, у H270 — 20, у B250 — 12.
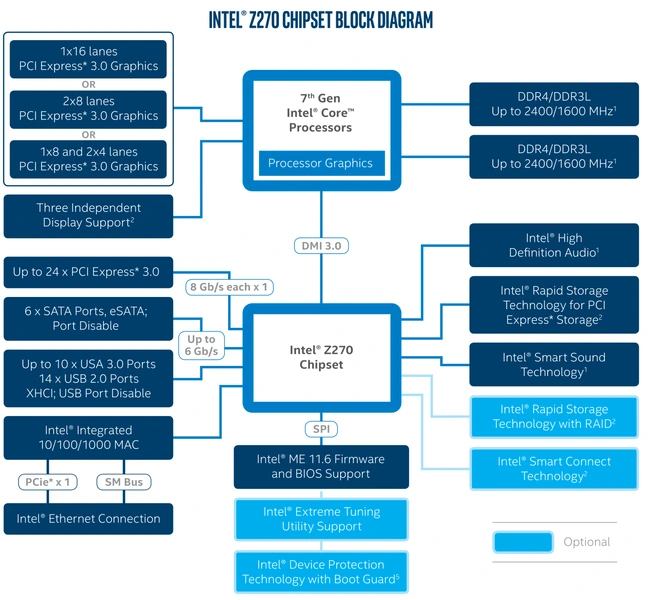
Чипсеты, выпущенные для 8 и 9 поколения Core для сокета LGA1151 v2 унаследовали ту же конфигурацию. Впрочем, как и сами процессоры. У Z370 и Z390 все так же 24, у H370 — 20, у B360 — 12, у H310 — 6 линий третьего поколения стандарта. Новинкой в иерархии чипсетов стал только B365, который получил 20 линий PCI-E 3.0.
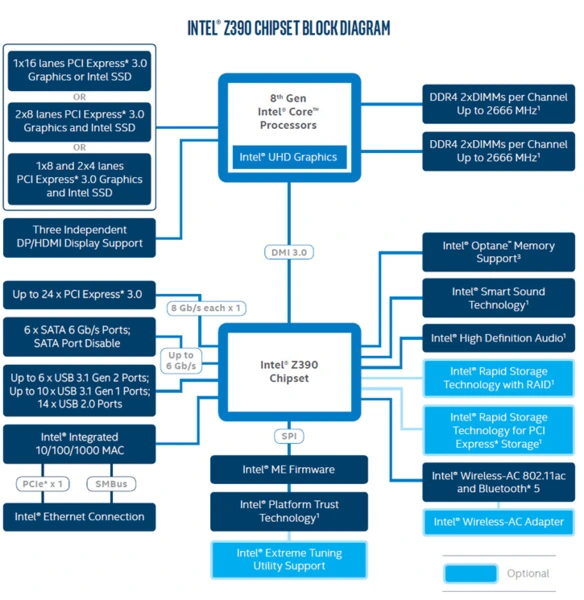
Сокет LGA1200 начал свой путь с процессоров 10 поколения Core и 400 серии чипсетов для них. Это последнее поколение, в котором не было изменений в топологии линий со времен 100 серии чипсетов. Топовый Z490 имеет 24 линии, H470 обладает 20 линиями, средний B460 — 16, а младший H610 — всего 6.
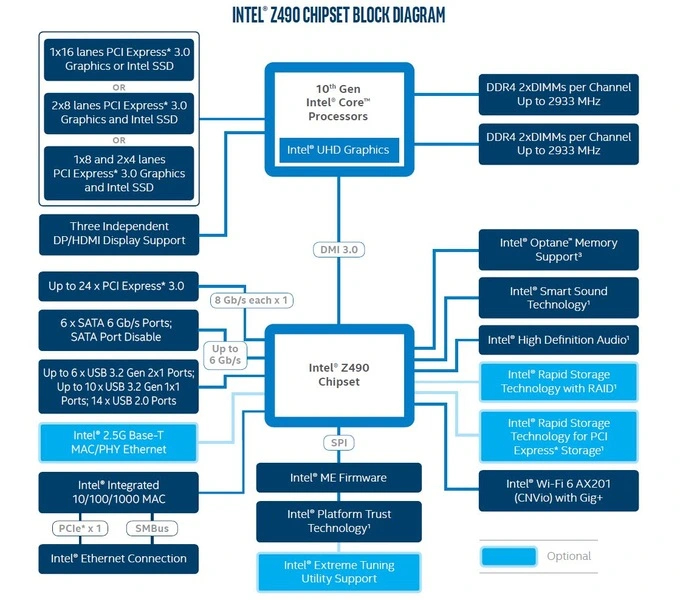
11 поколение процессоров и 500 серия чипсетов принесли поддержку PCI-E 4.0. Помимо слота нового поколения с 16 линиями для видеокарты появился и выделенный канал с 4 линиями той же версии для NVME SSD. Линк связи с чипсетом расширен до DMI 3.0 x8, но только в Z590 и H570. У первого 24 линии PCI-E, у второго — 20. Средний B560 и младший H510 остались на DMI 3.0 x4. Линий у них 12 и 6 соответственно.
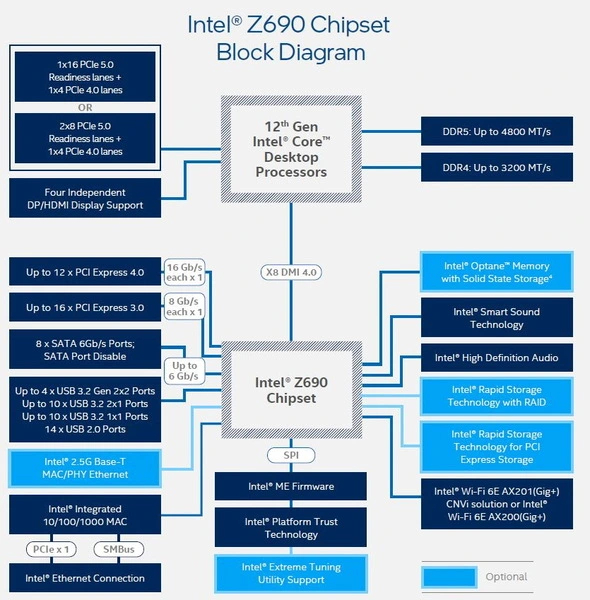
Революция в этот сегмент пришла с сокетом LGA1700, процессорами 12 поколения и новыми платами 600 серии для них. Появилось сразу два нововведения: линии для графики стали поддерживать PCI-E 5.0, линии чипсета — PCI-E 4.0. Выделенный канал для NVME SSD остался неизменным, зато линк связи с чипсетом в очередной раз ускорился в два раза: у Z690 и H670 его перевели на режим 4.0 x8, у B660 и H610 — на 4.0 x4.
Канал связи процессора с чипсетом расширили не зря. Теперь флагманский Z690 поддерживает 12 линий PCI-E 4.0 плюс 16 линий PCI-E 3.0 против прежних 24 линий 3.0-версии стандарта. Это открывает гораздо больше возможностей для скоростной периферии, чем в предыдущем поколении. H670 выглядит скромнее — у него по 12 линий PCI-E 3.0 и 4.0. У B660 их 6 плюс 8 соответственно, младший H610 линиями четвертой версии обделили — здесь только 8 линий PCI-E 3.0. В этом поколении разделять линии слота для видеокарты помимо Z690 научился и H670. Конфигурацию 8+4+4 для этого посчитали неактуальной, оставив лишь более привычные 8+8.
Возможности процессоров Core 13 и 14 поколений изменений не претерпели. Но чипсеты 700 серии, использующие ту же платформу LGA 1700, подверглись заметному тюнингу. По сравнению с предшественниками, в каждом из них было увеличено количество быстрых линий PCI-E 4.0, а более медленные линии третьей версии интерфейса были сокращены. Z790 получил 20 линий PCI-E 4.0 и 8 PCI-E 3.0, а H770 — 16 PCI-E 4.0 и 8 PCI-E 3.0.
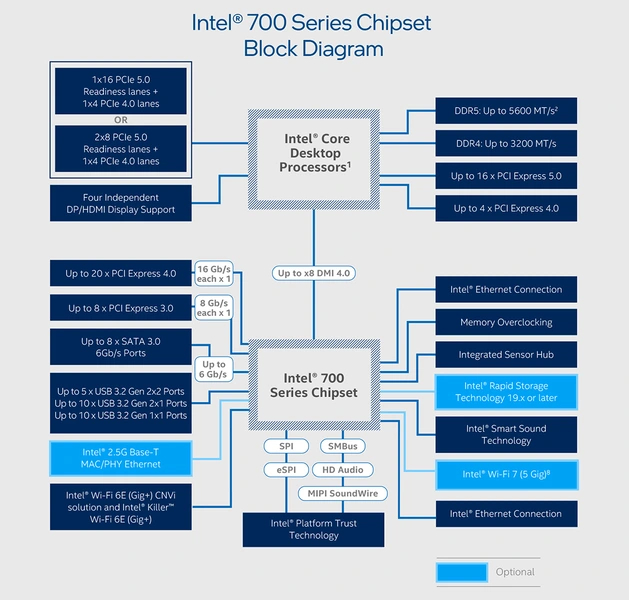
Оба старших чипсета для подключения к процессору используют 8 линий DMI 4.0. Средний B760 имеет для этой цели вдвое более узкий канал 4.0 x4, но при этом может обеспечить собственными силами 10 линий PCI-E 4.0, и ещё 4 — PCI-E 3.0.
Самая новая массовая платформа от Intel получила очередное расширение периферийных возможностей. Общее количество линий PCI-E у Core 15 поколения увеличилось до 24. К прежним 16 линиям PCI-E 5.0 и 4 линиям PCI-E 4.0 были добавлены еще 4 линии PCI-E 5.0. Таким образом, напрямую к Core Ultra стало возможным подключить сразу два NVMe накопителя: один 5.0 x4 и еще один 4.0 x4.
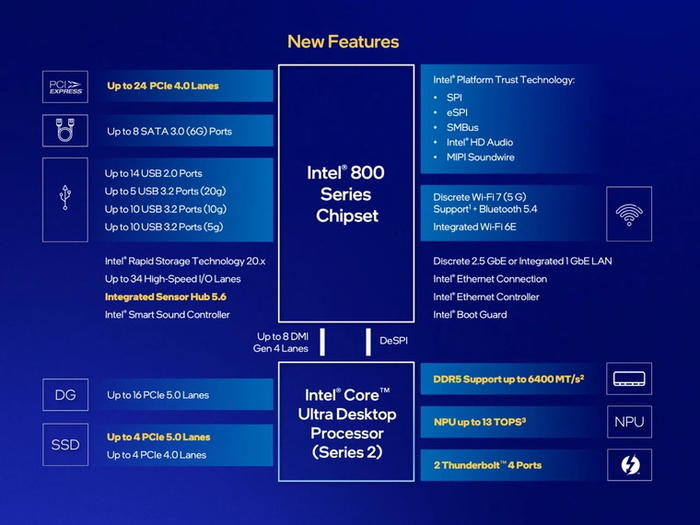
Вдобавок к этому, кристалл ЦП может напрямую взаимодействовать с двумя портами Thunderbolt 4/USB 4. В прошлых поколениях для их использования на материнской плате приходилось тратить линии чипсета.
Как и у платформы LGA 1700, для связи чипсета с процессором используется шина DMI 4.0. У старшего Z890 она имеет 8 линий, у среднего B860 и младшего H810 — по 4 линии. Ключевое отличие от прошлого поколения в том, что теперь все собственные линии самих чипсетов относятся к PCI-E 4.0. У Z890 их 24, у B860 — 14, а у H810 — 8.
В отличие от массовых, высокопроизводительные HEDT-платформы всегда оснащались большим количеством линий PCI-E. Не стала исключением и последняя такая платформа от Intel на сокете 2066. Единственный чипсет, выпущенный для нее — X299, обладает 24 линиями PCI-E 3.0. Повышенное количество выделенных линий у таких платформ обеспечивают не чипсеты, а сами процессоры. Если у процессоров массовых платформ на данный момент от силы 20 линий PCI-E — 16 на видеокарту и 4 на накопитель, то у процессоров HEDT количество свободных линий для коммуникации с оборудованием может достигать 64.
Впрочем, у Intel это зависит от модели процессора и его положения в иерархии. Для LGA2066 было выпущено три поколения процессоров. Старшие модели 7000 и 9000 серии имеют 44 линии PCI-E 3.0, 10000 серии — 48. При этом у средних моделей таких линий только 28, а у самых младших — лишь 16, как на массовых платформах.
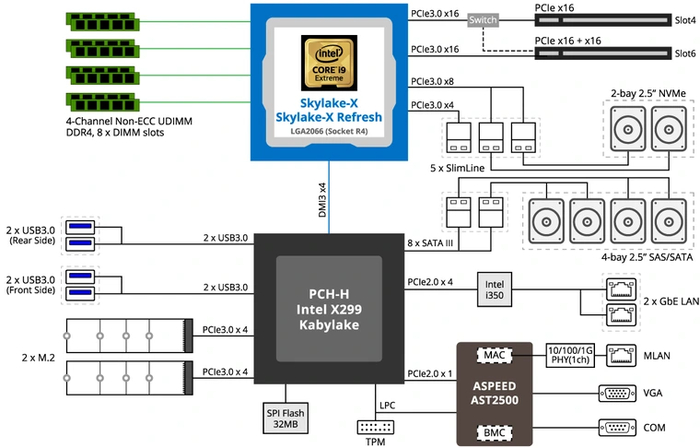
Платформа LGA2066 была выпущена в 2017 году, и еще два года получала обновления в виде новых процессоров с увеличенным количеством ядер. К сожалению, последние три года о новых HEDT-платформах Intel кроме слухов ничего не слышно. Именно поэтому более современной продукции Intel в этом сегменте ни с PCI-E 4.0, ни с новейшим PCI-E 5.0 так и нет.
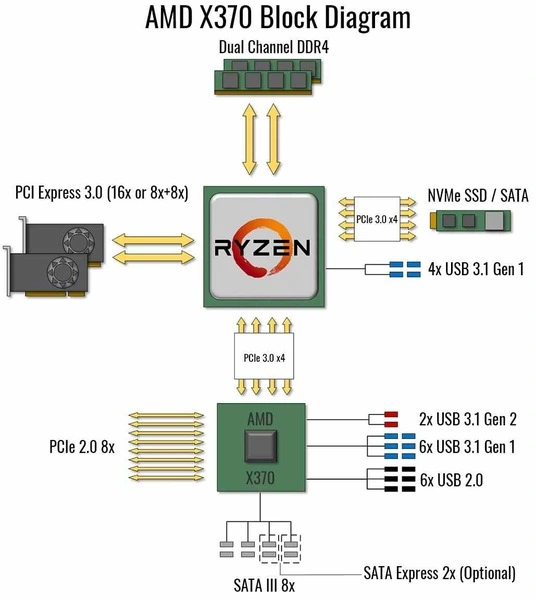
Первое поколение Ryzen 1000 и 300 серия чипсетов для них стали первой платформой, где был реализован отдельный канал PCI-E 3.0 x4 для NVME SSD. Соединение процессора с чипсетом происходит на аналогичной скорости, для видеокарты используется PCI-E 3.0 x16, который старший X370 и B350 умеют делить на два слота по x8. А вот с периферией тут хуже, чем у конкурента. У старшего X370 — 8 линий устаревшего PCI-E 2.0, у среднего B350 таких линий 6, у младшего A320 — всего 4.
Помимо Ryzen 1000 серии под платформу AM4 были выпущены APU на базе этого же поколения архитектуры — процессоры со встроенной графикой серии Ryzen 2000G и Athlon 200GE, а также процессоры и APU на старой архитектуре Excavator - Athlon X4 и серия APU A6/A8/A10/A12. Они имеют урезанный канал PCI-E 3.0 для видеокарты — всего 8 линий, а процессоры архитектуры Excavator вдобавок лишены 4 линий для отдельного канала NVME SSD.
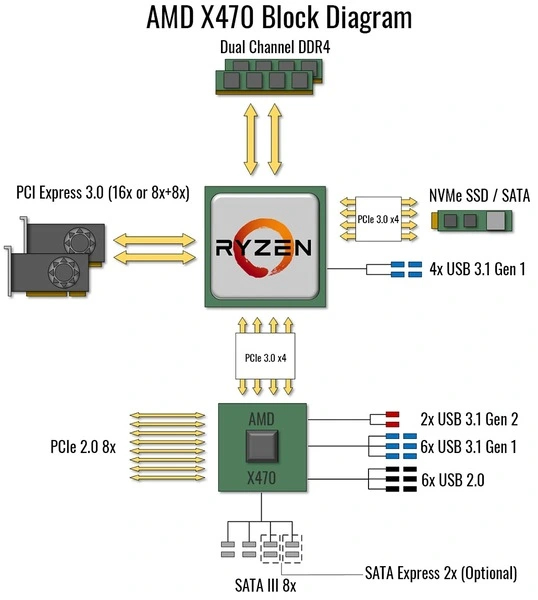
Второе поколение Ryzen и 400 серия чипсетов в этом плане изменений не получили: линии у X470 и B450 аналогичны своим предшественникам X370 и B350. Процессоры Ryzen 2000 по периферийным возможностям от прошлой линейки тоже не отличаются. Выпущенным на их базе APU серии Ryzen 3000G и Athlon 3000G/ 300GE вернули полноценную поддержку разъема PCI-E для видеокарты — 16 линий версии 3.0.
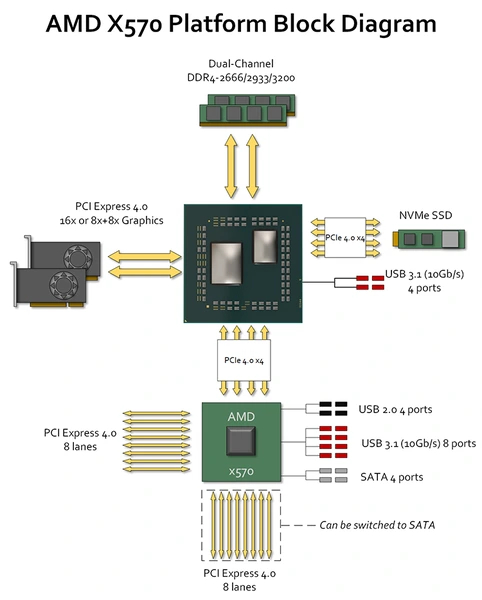
А вот с выходом на рынок Ryzen 3000 и чипсетов 500 серии платформа сразу получила полный PCI-E 4.0 — и для видеокарты, и для NVME SSD, и для связи с чипсетом, и для линий самого чипсета. Правда, только в связке со старшим X570, который может предоставить до 12 линий PCI-E 4.0. Средний B550 имеет 10 линий третьей версии, да и сам связывается с процессором по PCI-E 3.0 x4. Младший A520 поддержки четвертой версии шины лишен — все коммуникации у него основаны на PCI-E 3.0, а соответствующих линий от чипсета всего 6. Как и раньше, старшая и средняя версия чипсетов поддерживают разделение слота для видеокарты на два с 8 линиями каждый.
Следующее поколение процессоров Ryzen 5000 в плане поддержки периферии изменений не получило. Именно поэтому компания AMD не стала выпускать для него новые чипсеты, ограничившись обновлением BIOS для плат на старых чипсетах. APU на базе 3000 и 5000 серий — Ryzen 4000G и 5000G — поддержки PCI-E 4.0 не получили, для всех соединений все так же используя PCI-E 3.0.
Процессоры Ryzen 7000 под сокет AM5 вместе с чипсетами 600 серии принесли массовым платформам AMD долгожданную поддержку PCI-E 5.0. Сами ЦП обладают 16 линиями нового поколения для видеокарты и 8 такими же линиями для двух NVME SSD. А подключение к чипсетам осуществляется с помощью 4 линий PCI-E 4.0.

Аналогичные возможности имеют ЦП Ryzen 9000 и чипсеты AMD 800 серии. При этом APU Ryzen 8000, которые тоже используют ту же платформу, в этом плане заметно обделены. У Ryzen 7 и старших Ryzen 5 8 линий PCI-E 4.0 для слота видеокарты, и еще 4 — для одного NVMe SSD. А у Ryzen 3 и младших Ryzen 5 всего лишь 4 линии PCI-E 4.0 для видеокарты и 2 такие же линии для накопителя.
Старшие чипсеты X670, X670E и X870E предлагают до 12 линий PCI-E 4.0, «середнячки» B650, B650E, B850 и X870 — до 8. Младшие A620 и B840 имеют 8 линий PCI-E 3.0. При этом они сами, в отличие от прочих моделей, подключаются к процессору в «замедленном» режиме PCI-E 3.0 x4.
Первая современная HEDT-платформа от AMD использует сокет TR4 и чипсет X399. В отличие от Intel, у любого процессора AMD Threadripper первого или второго поколения под эту платформу стабильное количество свободных линий PCI-E 3.0 — 60. Еще 4 линии этой версии, а также 8 линий более медленного PCI-E 2.0 добавляет чипсет, который связывается с процессором по PCI-E 3.0 x4.

Второе поколение HEDT-платформ AMD получило новый сокет sTRX4, и полностью перешло на использование PCI-E 4.0. У чипсета TRX40 64 линии обновленной версии интерфейса от процессора и 8 таких же линий от чипсета, который связывается с процессором по PCI-E 4.0 x8.

Если в компьютере много периферии, требующей высокоскоростного подключения, то линий на все может не хватать. Например, в массовых платформах на полной скорости x16 можно подключить только одну видеокарту. В случае использования топового чипсета две видеокарты можно будет подключить только на «половинной» скорости x8, которая может снизить их быстродействие. В случае остальных чипсетов — только по схеме x16 + x4, последние из которых будут браться от чипсета. Такое неравновесие еще больше может усугубить производительность.

Периферийных устройств, портов и разъемов на платах часто больше, чем может обеспечить чипсет одновременно. Из-за этого приходится выбирать, каким портам и устройствам предоставить пропускную способность. Но при этом одновременно все порты и устройства задействовать не удастся. Простой пример: в некоторых системах установка второго NVME накопителя отключает порты SATA, потому что на них перестает хватать линий чипсета. Если бы последние были неограниченными, такого бы не было.
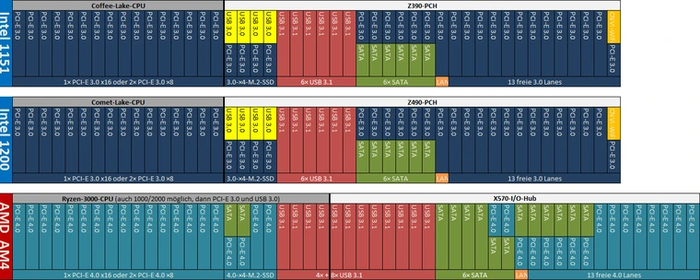
Еще одна проблема в том, что соединение чипсета с процессором использует меньше линий, чем дает сам чипсет на выходе. Именно поэтому, даже если чипсету хватает собственных линий на все устройства, последние не могут работать на полной скорости одновременно. С процессорами Intel до 11 поколения NVME-слоты общаются через чипсет, который подключен по PCI-E 3.0 x4. Если установить два таких накопителя и использовать их параллельно, то оба из них не смогут одновременно смогут передавать данные процессору на полной скорости из-за бутылочного горлышка, находящегося в соединении чипсета. Особенно это может помешать при активном RAID.
У чипсетов 300 и 400 серии AMD под процессоры Ryzen другая проблема: линии чипсета поддерживают лишь PCI-E 2.0. Поэтому при установке второго SSD в слот, подключенный к чипсету, он попросту потеряет половину своей скорости.
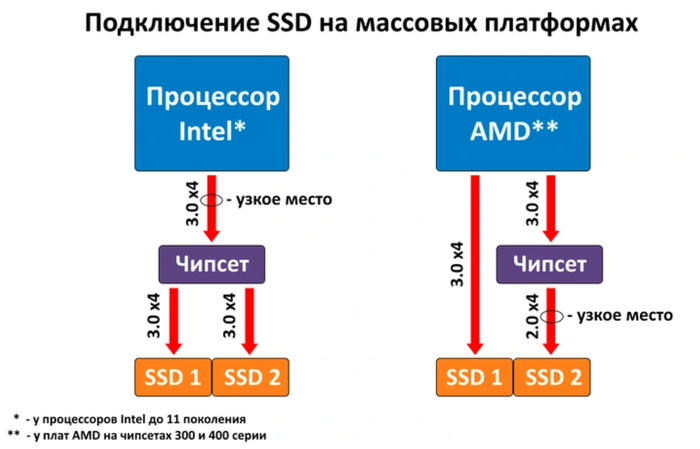
Последние массовые платформы обеих компаний частично лишены этих недостатков за счет использования каналов связи с чипсетами с более высокой пропускной способностью. Но полностью избавить от них могут только HEDT-платформы, которые обладают гораздо большим количеством линий PCI-E. На таких платформах нехватка линий может возникнуть только в самых крайних случаях: при одновременном использовании более двух видеокарт вкупе с большим количеством высокоскоростных SSD.
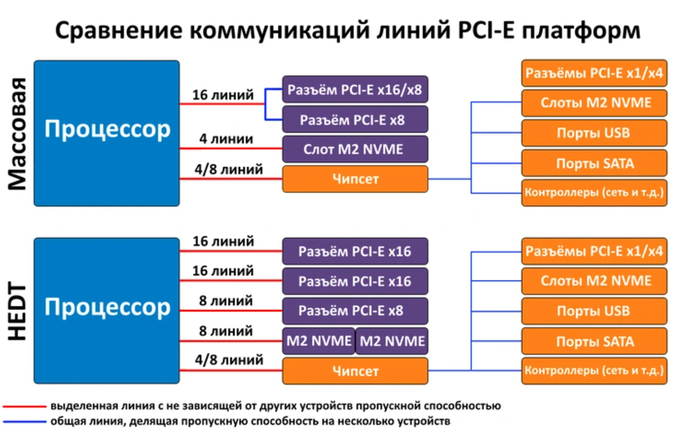
В виду ограничения фотоматериалов
ПРОДОЛЖЕНИЕ СЛЕДУЕТ...

Высокоскоростная шина PCI-Express — одна из основ современных компьютерных систем. Ее линии — это связующие звенья между различными компонентами любого ПК. Раз в несколько лет появляется новая версия шины, приносящая очередные улучшения. Что нового принесла с собой PCI-Express 5.0, и чем отличается от своей предшественницы четвертой версии?
Персональный компьютер представить без шины PCI-E просто невозможно. Линии PCI-E связывают центральный процессор с видеокартой, накопителями, чипсетом и платами расширения — все соединения, требующие высокой скорости обмена данными, базируются именно на этой шине.
Производительность компьютеров растет из года в год, а шине PCI-E скоро стукнет два десятка лет. Поэтому нет ничего удивительного в том, что раз в несколько лет она получает доработки для более высокой скорости обмена информацией, и в связи с этим обновляется до новой версии. Сейчас на смену уже привычному PCI-E 4.0 приходит пятая версия обновленного интерфейса. Первые платформы с его поддержкой уже на рынке — это Intel LGA1700 и AMD AM5.
Главным новшеством пятой версии интерфейса является увеличение пропускной способности. Как и прежде, стандарт верен правилу удвоения пропускной способности каждое поколение. Это означает, что при одинаковом количестве линий пропускная способность PCI-E 5.0 вдвое больше, чем у предшественника.

Каждая линия PCI-E 5.0 обеспечивает пропускную способность в 32 Гбит/c. При этом используется схема кодирования 128b/130b, когда 128 бит данных кодируются 130 битами, — она не нова, и появилась еще в PCI-E 3.0. В результате, скорость обмена данными по одной линии составляет 31.5 Гбит/c, или почти 3.94 ГБ/c.
Разъем для видеокарт с 16 линиями нового стандарта может обеспечить эффективную пропускную способность на уровне 63 ГБ/с. Не менее впечатляет и скорость NVMe-слотов нового поколения — четыре линии дают пропускную способность в 15.75 ГБ/c. Для сравнения: при использовании PCI-E 4.0 эти значения составляют лишь 31.5 и 7.87 ГБ/с, соответственно.
При этом новые слоты расширения сохраняют совместимость со старыми картами, накопителями и прочими устройствами, работающими в более медленном режиме. Впрочем, как и всегда — преемственность поколений у шины присутствует изначально.
Главными потребителями линий PCI-E, несомненно, являются видеокарты. Из всех компонентов системы именно графические адаптеры нуждаются в как можно большей скорости обмена данными.


Впрочем, и здесь все не так просто. Наличие соответствующей версии интерфейса у видеокарты отнюдь не означает, что она в нем нуждается. Видеокарта RTX4090, до 2025 года являлась флагманом компании NVIDIA и самым быстрым графическим адаптером в мире, была протестирована на производительность в трех разрешениях с разными версиями шины PCI-E ресурсом TechPowerUp:

Как видим, даже для текущего короля 3D-графики задействование режима PCI-E 3.0 одиннадцатилетней давности против нативного PCI-E 4.0 выливается лишь в потерю 2–3% производительности. Режим PCI-E 2.0, которому стукнуло уже полтора десятка лет, просаживает производительность сильнее, но тоже не так заметно — на 6–8%. И лишь старичок PCI-E 1.1, который в следующем году будет отмечать 20-летний юбилей, ограничивает производительность флагманской карты на 18–20%.
Казалось бы, если у топовой видеокарты такая небольшая разница даже с вдвое более медленным PCI-E 4.0, то зачем переходить на PCI-E 5.0 всем остальным? Но тут есть одна загвоздка — дело в том, что в последние годы многие видеокарты среднего и бюджетного ценовых сегментов получают урезанное количество линий PCI-E. Это кратно уменьшает пропускную способность. Например, у NVIDIA RTX3050 восемь линий PCI-E 4.0, которые по пропускной способности равны 16 линиям более старого PCI-E 3.0. А у AMD RX6500XT так вообще четыре линии PCI-E 4.0, которые имеют пропускную способность, аналогичную достаточно древнему PCI-E 2.0 x16.



Если учитывать, что в следующем поколении карты этого ценового диапазона станут быстрее, то вполне возможно, что малого количества линий PCI-E 4.0 им будет не хватать. Вот тут и понадобится более быстрый PCI-E 5.0. Однако, минусов при таком раскладе не избежать — даже если новые карты будут поддерживать пятую версию шины, для ее задействования в обязательном порядке понадобится соответствующая платформа с поддержкой PCI-E 5.0. В противном случае повышенной пропускной способности этим видеокартам не видать.
Для NVMe-накопителей наличие нового интерфейса кажется более полезным. Если текущий PCI-E 4.0 ограничивает максимальную скорость обмена с ними на отметке чуть более 7.5 ГБ/c, то с новым PCI-E 5.0 это значение превышает 15 ГБ/c.
Сразу ждать таких скоростей не стоит, ведь помимо интерфейса, соответствующими характеристиками должна обладать и сама флеш-память. Но даже у первых представленных моделей скорости достигают 10–12 ГБ/c — это уже в полтора раза больше, чем 7 ГБ/c у SSD с прошлым поколением интерфейса. Достижение двукратной разницы в скоростях между разными поколениями накопителей — лишь вопрос времени.

Но при этом нужно учитывать, что видна глазу разница в скоростях будет лишь на линейных операциях с большим количеством данных — например, при работе с видео сверхвысокого разрешения или сложными проектами в 3D-программах. В остальных случаях сверхскорости по отношению к прошлому поколению будет трудно заметить. Впрочем, как и разницу между SSD с интерфейсами PCI-E 3.0 и 4.0.
Если PCI-E 4.0 впервые внедрили на платформах AMD, то пионером PCI-E 5.0 стала новая платформа Intel — LGA1700. Первыми платами, получившими новый интерфейс в конце 2021 года, стали модели на базе чипсета Z690. На данный момент этот ассортимент расширен платами на чипсетах H670, H770 и Z790. У среднебюджетных B660 и B760 поддержка опциональна и встречается редко, а платы на младшем чипсете H610 новой версией шины оказались обделены.

Несмотря на звание первой платформы с поддержкой PCI-E 5.0, у LGA1700 есть небольшой нюанс. Дело в том, что пятую версию интерфейса поддерживают только 16 линий PCI-E от процессора, предназначенные для видеокарты. Четыре линии, выделенные для NVMe-накопителя, а также сама связь процессора с чипсетом базируются на четвертой версии PCI-E. То есть прямой возможности установить быстрый накопитель PCI-E 5.0 платформа не имеет. Для ее организации придется устанавливать SSD на отдельную плату расширения, вставляемую в разъем PCI-E x4 или PCI-E x8, и тем самым лишать драгоценных восьми линий видеокарту.

В отличие от LGA1700, новая платформа AMD AM5, увидевшая свет в конце прошлого года, изначально проектировалась под особенности пятой версии шины. Процессоры Ryzen 7000 имеют 28 линий PCI-E 5.0. 16 из них идут на слот видеокарты, две пары по четыре линии — к быстрым NVMe-слотам с поддержкой PCI-E 5.0. Последняя четверка в данный момент функционирует в более медленном режиме PCI-E 4.0 x4, и предназначена для связи с чипсетами AMD 600 серии. При этом новой версией интерфейса могут быть оснащены как дорогие платы на двух разновидностях топового чипсета X670/X670E, так и более дешевые на среднебюджетной паре B650/B650E — тут AMD развязала руки производителям, оставив реализацию PCI-E 5.0 на их выбор.

На данный момент платформа AM5 позволяет одновременное использование видеокарты и двух NVMe SSD с поддержкой пятой версии PCI-E. Еще четыре линии работают в более медленном режиме для связи с текущими чипсетами — вполне вероятно, что для будущих чипсетов платформы это соединение тоже перейдет на пятую версию интерфейса. Тем самым откроется возможность установки третьего NVMe-накопителя с PCI-E 5.0.
Внедрение новой версии интерфейса PCI-E, как и ранее, опережает текущие потребности большинства пользователей. Несмотря на полуторогодовалое присутствие на рынке, видеокарт под PCI-E 5.0 нет и в ближайший год не предвидится, а накопители только готовятся к выходу на рынок и далеки от массового применения.
Тем не менее, с учетом сохранения актуальности современных платформ в течении четырех-пяти лет, поддержка нового интерфейса может пригодиться в будущем. Особенно людям, работающим с большими объемами данных — в два раза более быстрые SSD уже не за горами. В этом плане платформа AM5 смотрится в лучшем свете, чем LGA1700. Впрочем, первая будет присутствовать на рынке еще года четыре, тогда как для второй уже в ближайший год придет замена в виде LGA1851. Можно быть уверенным, что на ней будет уже не частичная, а полная поддержка PCI-E 5.0, аналогично конкуренту.

Но если для SSD скорость PCI-E 5.0 еще может найти применение в некоторых сценариях, то для видеокарт толку от нее не будет еще долго. Мультичиповые конфигурации, которые могли бы немного выиграть от пятой версии шины, канули в лету, а одиночные ГП еще несколько лет не будут явно упираться в возможности четвертой версии интерфейса. Однако новая шина все-таки может пригодиться для будущих карт с урезанным количеством линий, с учетом их использования на новых платформах естественно.

Материнские платы — основа любой современной электроники. Именно они связывают между собой все остальные компоненты системы. Платы — достаточно сложные электронные устройства, но как же их производят?
Полный цикл производства материнских плат разделен на два этапа. Первый этап — это производство печатных плат. Второй этап — это сборочная линия, на которой на печатную плату устанавливаются все необходимые электронные детали и разъемы.
Процесс создания материнской платы стартует с производства печатных плат. Производственные процессы этого этапа доверены автоматам, но следят за их параметрами и помогают им в работе люди. Рождение платы начинается с создания ее основы — текстолита. Для современных материнских плат используется многослойный текстолит.

Чтобы получить один слой текстолита, тонкие листы стекловолокна пропитывают эпоксидной смолой и отправляют под пресс. После этого на получившуюся заготовку наносят слой меди, а поверх нее слой светочувствительного материала — фоторезиста. Специальная машина засвечивает поверхность заготовки по загруженному в нее фотошаблону, и в засвеченных областях образуются протравленные медью следы. Затем остальная медь с незасвеченным фоторезистом последовательно смывается в нескольких ваннах с химикатами. После всех этих процедур слой нашей будущей платы готов. По своим свойствам он похож на плотную бумагу.

Такие процедуры проходят все слои платы. Затем несколько готовых слоев накладываются друг на друга, чередуясь с препрегами — пропитанными смолой слоями стеклотекстолита без меди, используемых для изоляции и склеивания рабочих слоев друг с другом. Потом такой «бутерброд» отправляется под горячий пресс, где слои склеиваются между собой и в итоге образуют твердую заготовку текстолита для платы.
После выхода из пресса заготовка отправляется в сверлильный станок, который делает отверстия для сквозных соединений между слоями платы.

После окончания его работы плата отправляется на «мойку» в специальный аппарат-ванну, который очищает её поверхность. Следующий шаг – обработка заготовки специальными катализаторами ещё в одном аппарате-ванне, чтобы медь могла осесть в просверленных отверстиях. После неё в других ваннах с помощью растворов электролитов и технологии гальванической металлизации в отверстиях наращивают слои меди.

Далее будущая плата попадает на тестирование в специальный аппарат. Он проверяет соединения внутри платы с помощью специальных щупов — это похоже на прозвон проводки мультиметром, только автомат делает это в несколько раз быстрее человека. Если все в порядке, заготовка платы попадает на следующий шаг — нанесение паяльной маски. Это то самое внешнее покрытие, которое изолирует и защищает токопроводящие дорожки от внешних воздействий. Как правило, у современных плат оно может быть практически любого цвета — от классического зеленого до практически черного или ослепительного белого.

После нанесения маска обрабатывается в нужных местах ультрафиолетовым излучением и отправляется на сушку. Когда она высыхает, заготовка вновь отправляется на очередную мойку, где маска смывается в необработанных ультрафиолетом местах, чтобы обнажить контактные пятачки для будущих элементов на плате. С помощью другой маски в ходе таких же процессов создаются и надписи на текстолите. В качестве последнего шага специальный аппарат наносит на пятачки тонкий слой припоя — и текстолит будущей платы готов к поездке в сборочный цех материнских плат.
Если на производстве печатных плат должно быть чисто, то на автоматическом этапе сборочной линии так вообще обязательна практическая стерильность. Именно поэтому такие помещения изолированы, а сотрудники сборочного цеха должны надевать халаты, перчатки, бахилы и маски — прямо как врачи на операциях в больнице. Проход в цех от внешнего мира отделяет воздушный душ. Именно он позволяет «сдуть» всю пыль с одежды, чтобы она не попала в воздух сборочного цеха.

Текстолиты, приехавшие из цеха изготовления печатных плат, загружаются в автоматическую сборочную линию. Первоначально в нужных местах автомат наносит паяльную пасту. Затем заготовка едет по конвейеру дальше, где другие автоматы монтируют на нее различные электронные элементы: конденсаторы, транзисторы, чипы.

Для того, чтобы автоматизированное оборудование могло быстро получать доступ к нужным элементам, компании-производители отправляют их на сборочную линию в специальных лентах.

Когда все элементы на своих местах, наступает время для первой визуальной проверки корректности их нанесения. Но производит ее не человек, как можно было бы подумать, а тоже специальный автомат.
После автоматической линии текстолиты отправляются в печь. Там они разогреваются, и паяльная паста начинает плавиться. Таким образом все нанесенные электронные элементы припаиваются к поверхности заготовки материнской платы.

Когда платы остывают, на отсутствие дефектов их проверяет человек. Сотрудники цеха сначала визуально осматривают платы с помощью увеличительных стекол, а затем помещают их в еще одну разновидность специальных автоматов, которые тестируют их на правильность расположения элементов и работоспособность.

После всех проверок работники цеха присоединяют к плате коннекторы и одевают заглушки. Следующий шаг тоже без человеческих рук не обходится. Это шлифование нижней части платы, чтобы не было торчащих снизу ножек от установленных электронных элементов.

Затем вручную одеваются радиаторы охлаждения, и плата отправляется на последнюю визуальную проверку — снова человеческую. Если все в порядке, к новенькой плате добавляют комплектные кабели, инструкцию по эксплуатации и упаковывают в коробку. На этом путь производства завершен. Платы едут на склад производителя, оттуда — на склад продавца, а потом попадают в магазины. И, наконец, в финале пути — желанная плата попадает в руки купившего ее потребителя.
НЕМНОГО ФОТО С РЕАЛЬНОГО ПРОИЗВОДСТВА



После размещения всех элементов на поверхности печатной платы она поступает в специальную печь, где припойная паста плавится, образуется электрический контакт самого элемента и металлической контактной площадки.

После этого каждая будущая материнская плата проходит стресс-тест, когда её встряхивают, чтобы убедиться, что все элементы надёжно пристали. Вы не думайте, тут не трясут платы в руках и не бегают с ними по цеху, этим всем занимается другой робот.

После этого печатные платы идут в другую более крупную печь, где температура варьируется от 130 до 250 градусов по Цельсию.
Затем приходит очередь более габаритных компонентов: интегральных микросхем, конденсаторов, слотов и разъемов. Все эти элементы будущей материнской платы размещаются вручную. Каждая из операционисток ответственная за 2-6 деталей, в зависимости от того, насколько сложно их устанавливать.

На запястьях у девушек надеты специальные браслеты, чтобы исключить возникновение статического электричества.


После того, как все элементы установлены, время визуальной проверки, чтобы благодаря шаблону убедиться, что ничего не пропущено.
После установки последнего элемента и успешной проверки печатная плата идёт на тестированию. Примечательно, что тестируют все материнские платы. На этом этапе проверяется работоспособность материнской платы и её функциональность. Также платы подвергаются проверке работы в условиях отрицательных и высоких температур и повышенной влажности.

Последним этапом изготовления материнской платы является её упаковка. В этом цеху работа идёт споро и атмосфера более весёлая, девушки общаются между собой. Материнские платы укомплектовываются необходимыми кабелями, разъёмами и программным обеспечением. После этого продукция полностью готова к продаже.


