


Немного истории
47 постов
47 постов
10 постов
180 постов

4 поста

Скорости твердотельных накопителей растут семимильными шагами. Технические характеристики современных моделей на порядок превосходят таковые у SSD десятилетней давности. Но действительно ли они в разы быстрее? Везде ли есть толк от таких скоростей, или обычный пользователь их может попросту не заметить?
Первые потребительские SSD появились на рынке еще в конце 2000-х годов. Они имели небольшие объемы, а линейные скорости многих моделей лишь слегка превышали возможности жестких дисков. И хотя твердотельные накопители могли заметно ускорить работу ОС и программ, на момент появления мало кто бежал за новинками в магазины — уж слишком они были дороги, да и надежность моделей в первые годы оставляла желать лучшего.

Дебютные модели SSD, как и жесткие диски того времени, работали через интерфейс SATA2. На практике он позволял достигать скоростей до 280 Мб/c. С 2011 года стали появляться модели с интерфейсом SATA3. Он удваивал возможности предшественника, предоставляя полосу до 560 Мб/c. Но вскоре флэш-память уперлась и в этот потолок: ее возможности росли не по дням, а по часам.
Тогда начались первые эксперименты производителей SSD по переходу на шину PCI-E. Им сопутствовал вскоре появившийся стандарт SATA Express. Но ни то, ни другое не сыскало особой популярности: такие накопители были дороги, а ограниченная совместимость с материнскими платами поставила крест на их массовом распространении.

В 2014 году дальнейшее развитие SSD определило появление разъема M.2 — сначала в ноутбуках, а затем и в десктопных материнских платах. С его помощью можно было реализовать как интерфейс PCI-E, так и SATA. А ограничения последнего снял вовремя подоспевший протокол NVMe: в отличие от предшественника AHCI, он обладал практически неограниченной глубиной очереди и количеством возможных одновременных запросов. В 2015 году была выпущена массовая платформа Intel LGA1151, открывшая эпоху NVMe-накопителей. Слоты M2 с режимом работы PCI-E 3.0 x4 перестали быть редкостью, открывая пользователям поддержку SSD со скоростями до 3.6 Гб/c.

В середине 2020 года AMD перехватила эстафету, запустив первые чипсеты для платформы AM4 c поддержкой PCI-E 4.0. На них впервые можно было задействовать твердотельные накопители со скоростью до 7.2 Гб/c. А в конце 2021 года стала доступна платформа Intel LGA1700, с которой впервые стало возможным (пусть и не без костылей) реализовать подключение SSD с еще вдвое более быстрым интерфейсом — PCI-E 5.0.
А что же сами накопители? С распространением NVMe-моделей их скорости планомерно начали расти от 2 Гб/c, достигнув невероятных 14 Гб/c к сегодняшнему дню. В итоге за последние 10 лет SSD ускорились практически на порядок.
При работе операционная система взаимодействует с огромным количеством небольших файлов. В эпоху жестких дисков части этих файлов находились вразброс по поверхностям их «блинов». Для того чтобы считывать их и параллельно успевать записывать новые данные головки HDD были вынуждены все время двигаться. Поэтому случайные операции с мелкими блоками вносили ощутимую задержку, и в разы роняли скорость передачи данных по сравнению с линейным чтением или записью.

К счастью, программное обеспечение тех лет не было особо требовательно к этому параметру. Им было можно пользоваться относительно комфортно и с системным жестким диском. Но даже тогда первые твердотельные накопители всколыхнули компьютерный мир, заставив софт заметно ускориться. И причина тут совсем не в высоких линейных скоростях SSD, а именно в скоростях случайного доступа к мелким блокам. В твердотельных накопителях нет движущихся частей, поэтому доступ ко всем данным во флэш-памяти осуществляется с одинаково низкой задержкой. Это позволяет в разы сократить время, необходимое для случайных операций с мелкими блоками, и поднять их скорости на недостижимую для жестких дисков планку. Поэтому с любым SSD (даже старым, сравнимым по линейным скоростям с HDD) софт будет устанавливаться и запускаться заметно быстрее, а время его отклика при работе будет гораздо меньше.
Со временем программное обеспечение становилось требовательнее к дисковой подсистеме, а твердотельные накопители распространялись все шире. Разработчики ПО приняли это во внимание, потихоньку перестав оптимизировать программы для запуска с жестких дисков. Окончательную точку в этом вопросе поставило появление в 2015 году операционной системы Windows 10: ее все еще можно было установить на HDD, но «тормозов» при работе тогда было бы не избежать.
Это привело к тому, что к сегодняшнему дню «твердотельники» стали безальтернативным видом накопителей для установки ОС и программ. Однако случайное чтение мелких блоков у SSD хоть и быстрое, но все еще ограниченное производительностью чипов памяти и контроллера. Поэтому с их совершенствованием растут не только линейные, но и случайные мелкоблочные скорости. Причем интерфейс тут бутылочным горлышком совсем не становится: даже лучшие современные SSD в таком сценарии обеспечивают лишь чуть больше 100 Мб/c при чтении в один поток.
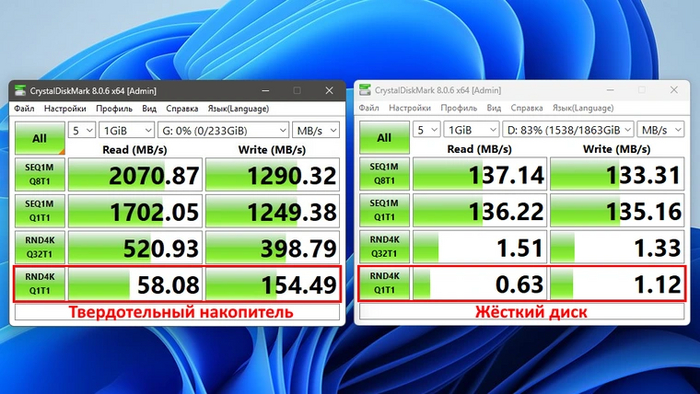
С появлением каждого нового поколения интерфейса производители накопителей торопятся как можно быстрее выпустить SSD с его поддержкой. Ну и куда же без рекламных лозунгов: быстрее, выше, сильнее! В качестве аргументов обычно приводятся тесты в различных бенчмарках — например, CrystalDisk Mark.
Эффектно, не так ли? Особенно если смотреть на первые две полоски, которые показывают линейные скорости. Однако именно они могут быть востребованы только в специфичных сценариях — вроде импорта или экспорта больших объемов видео при монтаже. И тут ждет следующий подводный камень: современные накопители долго поддерживать такие скорости при записи не умеют. Обычно на них выделяется максимум треть от свободного объема диска — так работает SLC-кэширование. Поэтому часть SSD для достижения таких скоростей на нужном объеме придется держать пустым.
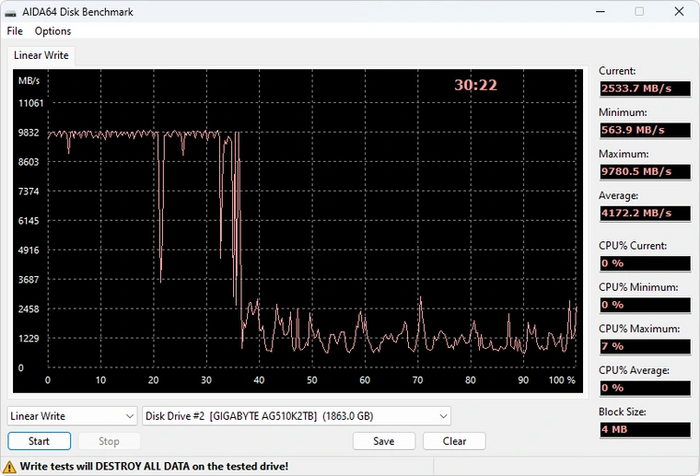
А вот прочитать весь объем без падения производительности — пожалуйста. Правда, придется придумать сценарий для линейного чтения с такой скоростью в домашних условиях. Может, оно пригодится для загрузки игр?

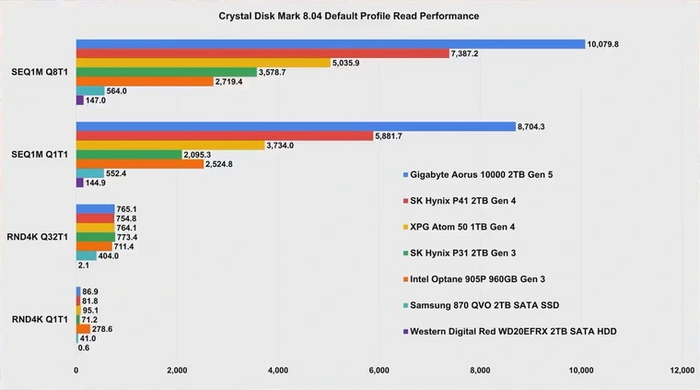
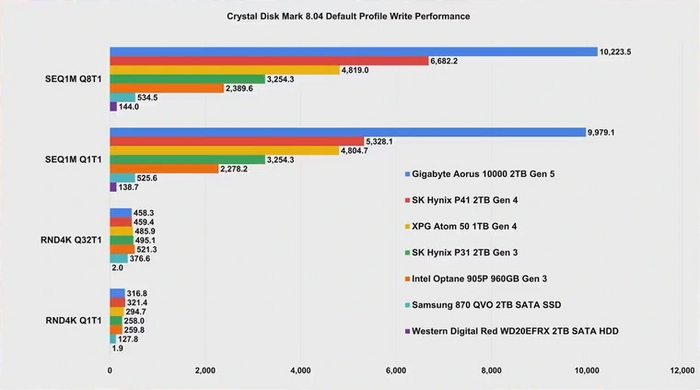
Для современных проектов действительно рекомендуется использовать SSD, чтобы избежать долгих загрузок и просадок производительности во время игры. По сравнению с жесткими дисками разница зачастую колоссальная, а вот «сорта» SSD между собой отличаются мало. И если переход на модели с PCI-E 3.0 в этом случае еще как-то оправдан, то от скоростей PCI-E 5.0 тут уже практически ничего не меняется — в данном случае производительность упирается в процессор и скорость ОЗУ системы. Высокие линейные скорости могут пригодиться при копировании крупных файлов. Но куда и откуда их копировать в случае с SSD PCI-E 5.0, чтобы добиться таких скоростей? Правильно, только со второго такого же SSD. Однако даже в этом, крайне притянутом за уши случае, разница будет существенна по сравнению с SATA SSD, но не с накопителем на базе интерфейса PCI-E 3.0.
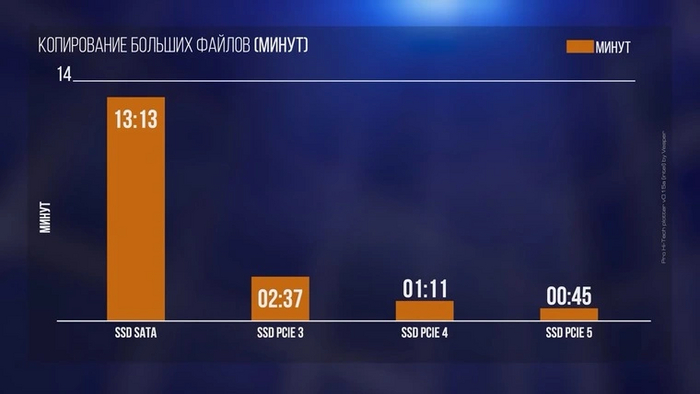
А скорости случайного доступа к мелким файлам, как уже упоминалось, от поколения интерфейса не зависят. Тут все упирается в контроллер и чипы памяти твердотельного накопителя. Поэтому не исключены случаи, когда топовые SSD с PCI-E 3.0 могут оказаться наравне с моделями на базе PCI-E 5.0. Например, при установке программного обеспечения нас ждет примерно следующая картина:
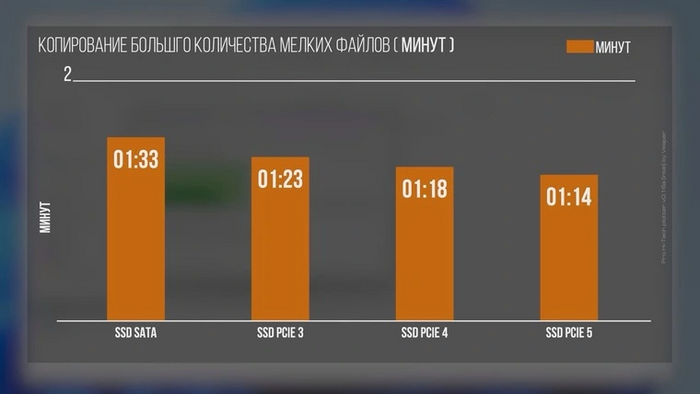
Линейные скорости твердотельных накопителей нельзя напрямую сопоставлять с их производительностью в реальных задачах. Скорость установки, запуска и отзывчивости операционной системы с программами зависят от производительности работы SSD с мелкими блоками, которая не находится в прямой зависимости от линейных операций и скорости интерфейса.
Играм тоже не нужны такие скорости, потому что время их загрузки упирается в другие компоненты системы. По крайней мере, на данный момент. C повсеместным внедрением технологий DirectStorage и RTX IO, призванных устранить узкое место в виде процессора, быстрые накопители смогут дать определенный прирост. Но, во-первых, до этого еще далеко — DirectStorage была представлена еще три года назад, а толку в единичных проектах с ее поддержкой до сих пор почти нет. Во-вторых, даже если прирост и будет заметен, то только при сравнении SSD с интерфейсом PCI-E 5.0 и морально устаревшим SATA. Накопители с PCI-E 3.0 и PCI-E 4.0 от «старшего брата» вряд ли отстанут.
Где же тогда могут пригодиться рекламируемые тысячи мегабайт в секунду? В домашнем использовании таких сценариев немного. Разве что монтаж продолжительных видеозаписей высокого разрешения, да копирование большого объема информации. Причем во втором случае для этого понадобится второй накопитель с хотя бы близкими скоростями, что совсем далеко от реальных ситуаций.
При этом нужно не забыть о поддержке быстрых накопителей платформой. Сегодня интерфейс PCI-E 5.0 для SSD в полной мере доступен только на Intel LGA1851 и AMD AM5. На топовых платах платформы Intel LGA1700 тоже можно встретить слоты с его поддержкой, но при этом нужно учитывать — их использование отнимет половину линий PCI-E у видеокарты.
Пока накопители с PCI-E 5.0 заметно дороже своих сородичей. Но рано или поздно любая технология становится массовой. В 2020 году можно было то же самое сказать о SSD с интерфейсом PCI-E 4.0, а сегодня они продаются по вполне демократичным ценам. Но, что самое важное, у новых моделей понемногу растет и скорость случайных мелкоблочных операций. Именно благодаря этому параметру они становятся быстрее, хотя это и не так заметно. Поэтому особого смысла выбирать SATA SSD на сегодняшний день уже нет — разве что для апгрейда старых систем, где отсутствует слот M.2 с поддержкой NVMe-накопителей.

В последние годы наблюдается бум развития нейросетей. Не прошел он и мимо 3D-графики реального времени. Еще в 2018 году NVIDIA впервые применила нейросеть для работы масштабирования DLSS. А недавно компания представила целый комплекс новых графических технологий, основанных на нейросетевой обработке — Neural Rendering. Что это такое, зачем нужно и как работает?
В начале века 3D-графика в играх развивалась стремительными темпами. Наиболее заметный скачок был совершен с появлением программируемых шейдеров. Благодаря им можно было реализовать сложные графические эффекты, которые ощутимо преображали картинку из набора плоских текстур.
Шейдеры совершенствовались из года в год, принося с собой возможность создавать новые и все более сложные эффекты. Но вычислительной мощности видеокарт не хватало, чтобы использовать все их возможности «по полной» в момент появления. К концу 2000-х развитие шейдеров замедлилось, а видеокарты стали наращивать «мускулы». Благодаря этому еще десяток лет графика развивалась — уже медленнее, но все так же планомерно.

С каждым новым поколением ГП разработчикам игр в реальном времени становились доступны эффекты, которые за несколько лет до этого можно было реализовать лишь со скоростью пары кадров в секунду. Поэтому, несмотря на отсутствие «прорывных» технологий, качество графики в играх понемногу росло. Но в 2018 году компания NVIDIA решила, что этот процесс слишком замедлился и настала пора революционных изменений. Тогда она представила технологию трассировки лучей в реальном времени и дебютную серию видеокарт RTX 2000, необходимую для ее работы. В последние шесть лет все усилия разработчиков игр направлены именно на трассировку. Но NVIDIA, кажется, нашла способ сделать графику в играх еще реалистичнее. В январе 2025 года вместе с видеокартами серии RTX 5000 она представила нейронные шейдеры, которые должны стать очередным «столпом» для развития графических технологий в ближайшее время.

Ключом к работе технологии масштабирования DLSS стали тензорные ядра, появившиеся в видеокартах серии RTX 2000. С течением времени она дорабатывалась, обеспечивая все более высокое качество. А когда появились линейка RTX 4000, тензорные ядра стали использоваться и для генерации кадров в DLSS 3.
В отличие от этих технологий, концепция Neural Rendering предлагает задействовать тензорные ядра не для всяческих улучшений уже отрендеренных кадров, а для использования подобных расчетов внутри самого конвейера рендеринга. Для этого NVIDIA предлагает следующие «трюки»:
RTX Neural Texture Compression
Сжатие текстур с помощью нейросети. Текстуры анализируются на предмет схожих или повторяющихся фрагментов, чтобы создать их представление в нейронном виде — своеобразный архив из кода. При том же качестве, что у традиционно сжатых, нейронные текстуры занимают до семи раз меньше памяти. Благодаря этому можно «поймать двух зайцев» одновременно: и качество самих текстур увеличить, и в небольшие объемы видеопамяти вписаться.

RTX Neural Materials
Использование нейросети для воспроизведения сложных поверхностей. Например, шелка, меха или фарфора. При их традиционной обработке с помощью универсальных шейдеров приходилось идти на компромиссы и упрощения, иначе производительность просаживалась довольно сильно. Тензорные ядра позволяют в несколько раз ускорить эти расчеты, благодаря чему подобные материалы можно сделать реалистичнее без пагубного влияния на FPS.

RTX Neural Radiance Cache
Трассировка пути — метод, позволяющий получить более реалистичное освещение, чем обычная трассировка лучей. Но он гораздо сильнее влияет на производительность, потому что видеокарте приходится просчитывать заметно большее количество переотражений лучей от разных поверхностей. Neural Radiance Cache — технология, призванная упростить трассировку пути для оборудования. При ее использовании только лишь пара отскоков лучей от поверхностей просчитывается RT-блоками. Дальнейший процесс возлагается на плечи нейросети. Она динамически обучается после первых «увиденных» отражений, чтобы просчитывать дальнейшие отскоки лучей самостоятельно.

Главный плюс Neural Rendering в том, что это не проприетарная технология NVIDIA. Его компоненты станут доступны в ближайшем обновлении графического API DirectX в виде функции «Кооперативные векторы» (Cooperative Vectors). При разработке стандарта Microsoft проводила консультации не только с NVIDIA, но и с другими разработчиками графических процессоров для Windows — AMD, Intel и даже Qualcomm. Ожидается, что графика каждого из них будет совместима с Neural Rendering. Но пока нет точной информации, какие это будут поколения видеокарт — нынешние или будущие.

Что до NVIDIA, то функции Neural Rendering будут доступны для всех видеокарт семейства RTX — от 2000 до 5000 серии. Но нужно учитывать, что наиболее оптимизированной для нее будет только последняя линейка RTX 5000.

Только ее графические чипы имеют аппаратный планировщик AI Management Processor, который эффективно распределяет вычисления между универсальными шейдерными процессорами и тензорными ядрами.

У прошлых поколений графики NVIDIA такого планировщика нет, поэтому его функционал будет реализован программно. Вдобавок к этому, их возможности работы с нейронными шейдерами ограничены заметно меньшим темпом тензорных вычислений. У RTX 5000 за счет поддержки низкой точности FP4 он в два с лишним раза выше, чем у RTX 4000 и RTX 3000. А явный аутсайдер в этом плане — дебютная линейка RTX 2000, которая поддерживает лишь FP16.
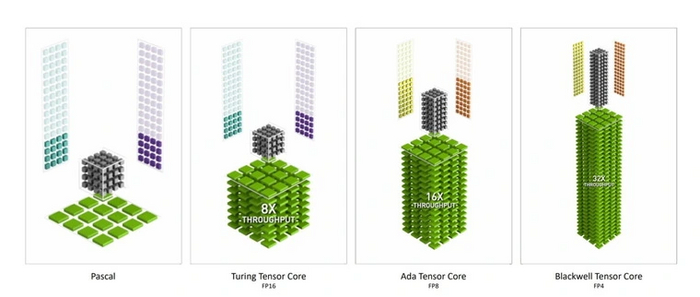
Для эффективной работы нейронных шейдеров линейка RTX 5000 также обзавелась планировщиком переупорядочивания выполнения шейдеров второго поколения (Shader Execution Reordering, SER). Он перегруппировывает различные операции по типам, чтобы они выполнялись на шейдерных процессорах и тензорных ядрах более эффективно.

В линейке RTX 4000 этот планировщик тоже присутствует, но работает только с операциями для универсальных шейдерных процессоров. А вот в RTX 3000 и RTX 2000 похожего блока нет вовсе.
Если объединить совокупность всех ограничивающих факторов, то можно сказать следующее: чем новее поколение графического процессора RTX, тем быстрее оно будет работать с функциями Neural Rendering. Скорее всего, в случае со старыми видеокартами эта технология не раскроет всех своих преимуществ из-за слишком медленного темпа вычислений и программной реализации некоторых этапов.
Neural Rendering — новая глава в развитии 3D-рендеринга реального времени. Его гибридный подход сочетает объединение традиционных шейдерных вычислений высокой точности (FP32) с работой локальных нейросетей, для которых подходят и вычисления низкой точности (FP4/FP8/FP16). За счет их помощи можно сократить потребление видеопамяти, улучшить качество текстур и сделать технологии трассировки менее затратными для оборудования.
Важно то, что благодаря функции Cooperative Vectors нейронный рендеринг станет стандартной возможностью API DirectX. Поэтому в будущем он будет работать не только на ГП NVIDIA с тензорными ядрами, но и на решениях от AMD, Intel и Qualcomm. Вполне возможно, что многие его функции будут работать и на уже существующем оборудовании. Например, в современных ГП Qualcomm Adreno для этой цели могут использоваться блоки FP16, которых вдвое больше, чем обычных FP32. А в линейке видеокарт AMD RX 7000 вычислительные блоки могут переключаться в режим матричного ускорения, которое как раз подходит для работы с нейронным рендерингом.

Однако стоит учитывать, что реализация нейронных шейдеров на графических процессорах, появившихся до концепции нейронного рендеринга, никогда не будет такой же быстрой, как на специально заточенных под это графических архитектурах — таких, как NVIDIA Blackwell в видеокартах RTX 5000. Поэтому рассчитывать на «магическое» повышение качества текстур и повсеместное внедрение трассировки пути в играх ближайшего будущего все-таки не стоит.
Как и в случае с трассировкой лучей в свое время, фишки нейронного рендеринга будут в первую очередь появляться в наиболее технологичных ААА-проектах. А вот станут ли они стандартными в течение нескольких лет учитывая то, что графические процессоры консолей текущего поколения для них не приспособлены — вопрос пока открытый.

Еще несколько лет назад в характеристиках видеокарты производители указывали скорость работы видеопамяти частотой — в МГц. Но в последние годы вместо частоты скорость указывается в Гбит/c или ГТ/с. В чем отличие этих характеристик, почему стали использоваться новые значения и как сравнить между собой эти величины?
В компьютерных системах еще с начала 90-х годов используется оперативная память типа Dynamic Random Access Memory (DRAM), которая к настоящему времени сменила несколько поколений. Физический принцип работы такого типа памяти прост: данные хранятся в ячейках, представляющих собой микроконденсаторы. Каждая ячейка хранит в себе 1 бит данных. В заряженном виде он читается как 1, в разряжённом — как 0.
В середине 90-х получает распространение память Synchronous Dynamic Random Access Memory (SDRAM). В отличие от ранних предшественников, память впервые стала синхронной, обзаведясь тактовым генератором. Данные в этом типе памяти передаются один раз за такт. То есть, частота генератора равна результирующей частоте работы самой памяти.

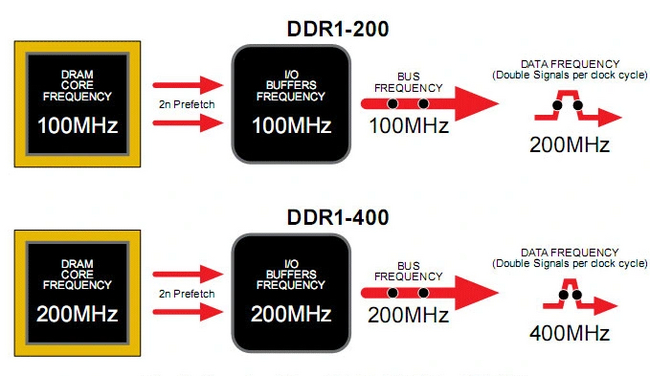
В начале 21 века на рынок был выведен новый тип памяти — Double Data Rate SDRAM (DDR). Как следует из названия, DDR представляет собой SDRAM с удвоенной скоростью передачи данных. Этого удалось достичь с помощью передачи данных дважды за такт, на фронте и спаде тактового сигнала.
Чтобы отправить информацию дважды за такт, сначала нужно было подготовить ее к такому выводу, что стало возможно благодаря технологии предвыборки под названием 2n-prefetch. Информация из двух выборок попадает в буфер ввода-вывода, через который потом происходит обмен данными с системой. Буфер и шина памяти у DDR имеют частоту, аналогичную частоте ядра памяти. Таким образом DDR, работающая на частоте в 200 МГц, имеет эффективную частоту в 400 МГц. По такому же принципу работает память для видеокарт GDDR первого и второго поколения.
Именно с момента появления первой DDR появились понятия «реальная» и «эффективная частота передачи данных». Хотя еще в то время в спецификации JEDEC появилось замечание, что использовать термин «МГц» для памяти типа DDR некорректно, правильнее указывать «миллионов передач в секунду через один вывод данных». Один миллион передач называется мегатрансфером, а количество таких передач в секунду обозначается МТ/c. Память типа DDR2 использует следующее поколение 4n-prefetch, где используются четыре выборки. И если в DDR частота буфера и шины была равна частоте ядра памяти, то в DDR2 она вдвое превышает последнюю. С этого поколения реальную частоту памяти можно считать по частоте работы шины. Эффективная частота все так же в два раза выше. Например, в памяти DDR2 с частотой 800 МГц шина памяти и буфер вывода работают на 400 МГц, а сама память — на 200 МГц. На базе DDR2 была разработана графическая память GDDR3, обладающая схожим принципом работы.

В оперативной памяти DDR3 и DDR4 используется выборка 8n-prefetch. Соответственно, шина и буфер работают на частоте, которая в четыре раза превышает частоту самой памяти. Реальная скорость передачи данных выше частоты шины все так же в два раза. Так работает и графическая GDDR4.
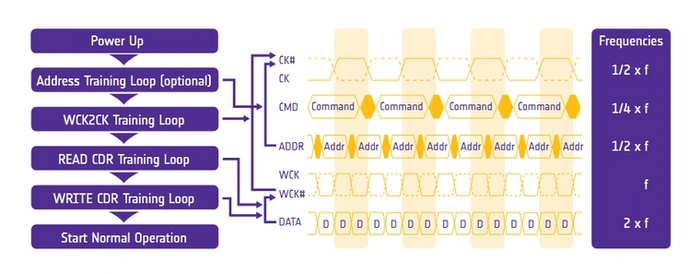
Современные виды графической памяти открывает устаревшая, но до сих пор применяющаяся в начальном сегменте GDDR5. Как и GDDR4, она использует 8n-prefetch, но пятое поколение видеопамяти стало способно передавать данные четыре раза за такт против двух у предшественников. Это стало возможным благодаря отделению частоты передачи адресов и команд (CK) от частоты передачи данных, которая вдвое выше (WCK). Теперь передается одновременно два импульса, в каждом из которых, как и раньше, два бита данных — на фронте и на спаде. Таким образом, эффективная частота памяти у GDDR5 в четыре раза превышает частоту шины.
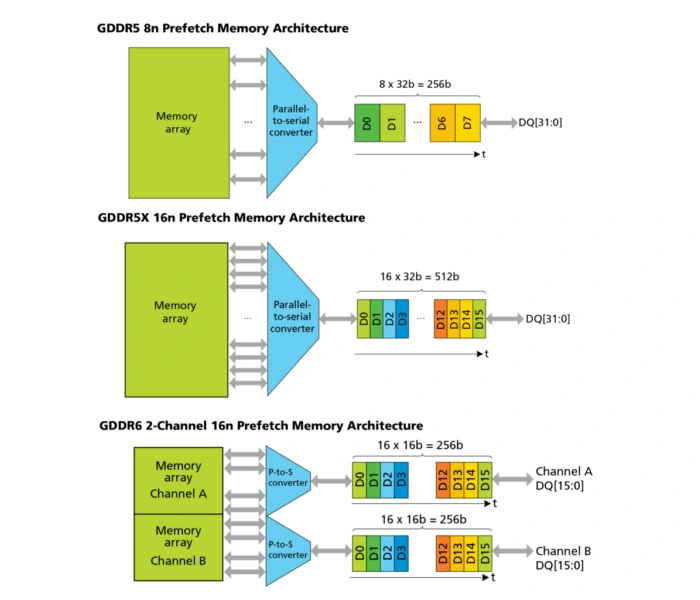
Память типа GDDR5X отличается от предшественника выборкой 16n-prefetch. Благодаря более широкой выборке частоту шины памяти теперь можно было снизить, при этом получив прирост пропускной способности на четверть.
Аналогичную выборку использует и современная GDDR6. Основная разница в том, что в этом типе видеопамяти каждый 32-битный канал данных разделен на два 16-битных. Это позволяет отправлять к памяти больше запросов одновременно, но непосредственно на пропускную способность не влияет. Последняя возросла до полутора раз по сравнению с GDDR5X благодаря повышенным частотам.
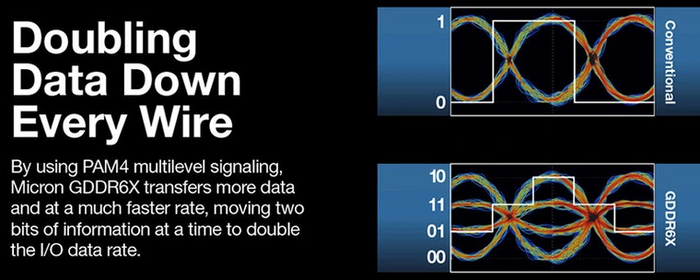
В новейшей GDDR6X увеличение скорости работы памяти по сравнению с предшественником в очередной раз достигло полуторакратной планки. В этом ей помогла новая технология кодирования 4 Pulse Amplitude Modulation (PAM4), суть которой в использовании четырехуровневой модуляции сигнала против двухуровневой у прошлых поколений памяти.
Как вы уже поняли, с развитием памяти DDR увеличение количества выборок и новые виды модуляции все дальше и дальше отдаляли «эффективную» частоту памяти от «реальной», под которой подразумевается частота шины. А уж от частоты работы самих микросхем памяти и подавно. Именно поэтому несколько лет назад производители видеокарт решили наконец вспомнить про рекомендации JEDEC двадцатилетней давности и указывать скорость работы памяти либо в трансферах в секунду, либо в пропускной способности на один контакт.
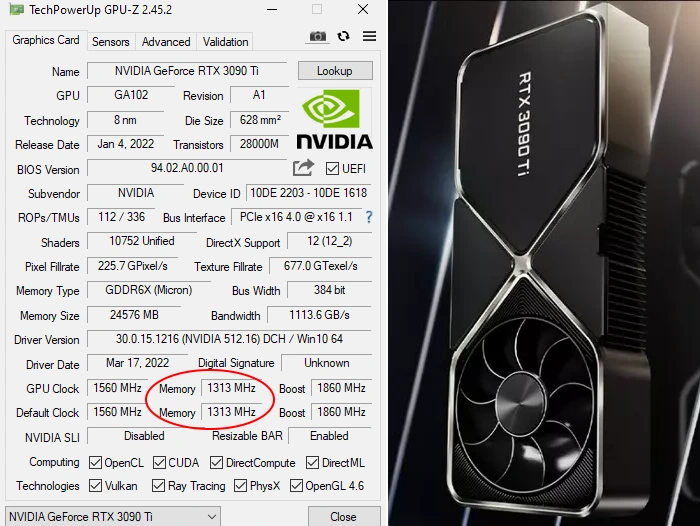
Например, современный флагман NVIDIA RTX 3090 Ti имеет скорость работы памяти 21000 МТ/c, или 21 ГТ/c. Это же значение указывается как 21 Гбит/c — в этом случае имеется ввиду пропускная способность на один вывод памяти, то есть на один бит шины. Это может запутать неподготовленного пользователя, ведь в случае видеокарты имеет смысл не один вывод, а общая пропускная способность шины. Которая, к тому же, измеряется не в Гбит/с, а в Гбайт/c.
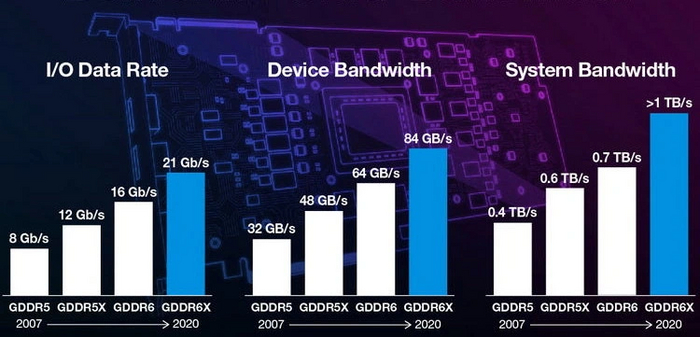
Как узнать реальную пропускную способность памяти видеокарты, у которой вместо частоты указаны МТ/c, ГТ/c или Гбит/c? Все очень просто. Указанные величины соответствуют эффективной частоте памяти. 21000 МТ/c, 21 ГТ/c, и 21 Гбит/c — все это равно эффективной частоте памяти в 21 ГГц. А зная частоту, можно вычислить пропускную способность установленной видеопамяти по формуле:
Частота (ГГц) х ширина шины памяти (бит) : 8 (бит в байте)
В случае RTX 3090 Ti мы получаем пропускную способность 21 ГГц × 384 бит ÷ 8 = 1008 Гбайт/c, что соответствует официальному значению, указанному компанией NVIDIA.
Откуда же берутся такие высокие результирующие частоты памяти? Чтобы понять принцип их формирования, предлагаем взглянуть на таблицу ниже.
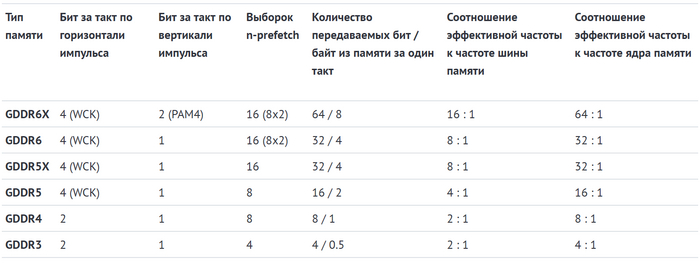
Разберем на примере все той же RTX 3090 Ti с памятью GDDR6X. Эффективная частота в 21000 МГц в этом случае имеет соотношение к частоте шины 16:1. То есть для вычисления последней 21000 нужно разделить на 16. Результат будет равен 1312,5 МГц, что и наблюдается в округленном виде в программе GPU-Z.
Соотношение эффективной частоты к истинной частоте работы микросхем памяти составляет 64:1. Благодаря нехитрым расчетам можно узнать, что внутри топовой GDDR6X работают микросхемы с частотой около 328 МГц.
Как видите, путаница обозначений возникла из-за использования разных характеристик скорости памяти производителями в разные годы. Если бы компании изначально придерживались рекомендаций JEDEC еще со времен выпуска первой DDR, то такого бы не было.

Любая память типа DDR имеет три разные частоты: частоту ядра памяти, частоту шины/буфера и эффективную частоту. Впрочем, для простого пользователя достаточно знать лишь последнюю — с ее помощью можно вычислить пропускную способность и сравнить видеокарту по скорости работы памяти с другими. А как она обозначается — Гбит/c, ГТ/c или ГГц — неважно. Важно помнить, что все эти значения в данном конкретном случае взаимозаменяемы.

В феврале 2024 года компания Intel представила свою обновленную дорожную карту. Этим она немного приоткрыла завесу тайны, огласив некоторые интересные особенности процессоров следующих поколений и технологий их производства.
Многие наверняка помнят, что основной для продуктов Intel долгое время являлась технология производства 14 нм. С 2015 по 2021 год именно по этому техпроцессу выпускались все десктопные процессоры Intel Core. И лишь в конце 2021 года вместе с Core 12-го поколения компания вывела на рынок новый техпроцесс Intel 7, который на самом деле является разновидностью 10 нм норм.
С этого момента в истории производства Intel началась новая глава. Десктопные модели Core 13-го и 14-го поколений продолжили использовать техпроцесс Intel 7, но в мобильных процессорах Core Ultra, представленных в конце 2023 года, компания начала использовать следующий процесс под названием Intel 4 (7 нм). В обновленном роадмапе за ним следуют будущие техпроцессы — Intel 3, Intel 20A, Intel 18A, Intel 14A и Intel 10A. Расскажем о каждом поподробнее.
Дальнейшее развитие идей Intel 4 найдет воплощение в техпроцессе Intel 3. Как и в прямом предшественнике, в нем используется литография в сверхжестком ультрафиолете (EUV), без которой не обойтись в таких тонких процессах.
Intel 3 уже прошел полное тестирование и готов к применению. Относительно Intel 4 показатель производительности на ватт вырастет на 18 %, что довольно неплохо при схожем процессе производства. К тому же, по сравнению с предшественником, он позволит достичь более высокой плотности транзисторов и рассчитан на более высокопроизводительные чипы.
Однако десктопные и мобильные процессоры Intel этот техпроцесс обойдет стороной. Уделом Intel 3 станут новые серверные процессоры под названием Xeon 6. Их будет две разновидности — на основе производительных (Granite Rapids) и энергоэффективных (Sierra Forest) ядер.
Выпуск Granite Rapids состоится уже во втором квартале 2024 года, а Sierra Forest — в его второй половине. Благодаря новому техпроцессу в этих чипах уместится до 288 энергоэффективных ядер.
Техпроцесс Intel 20A для рядового пользователя более интересен. Ведь именно на нем будут построены процессоры 15-го поколения Core под кодовым названием Arrow Lake. Как и мобильные Meteor Lake, эти процессоры получат «Core Ultra» в названии и плиточную компоновку Foveros — впервые для десктопа.
Intel 20A, по словам компании, открывает «эру Ангстрема». Это и отражено в названии техпроцесса: 20A — 20 ангстрем, то есть 2 нм. Конечно, маркетинговые нанометры давно перестали отражать реальные размеры транзисторов, но именно этот техпроцесс должен обеспечить наиболее большой технологический скачок. В том числе, благодаря двум заметным технологическим улучшениям.
Первое их них — новые транзисторы RibbonFET Gate-All-Around (GAA). Они оснащены затвором с четырьмя каналами, который полностью их окружает. Это первое улучшение с 2012 года, когда были внедрены так называемые 3D-транзисторы FinFET, окруженные затвором с трех сторон.

В отличие от них, транзисторы GAA занимают меньше места, благодаря чему заметно возрастает их плотность. К тому же и переключаются они при сравнимом токе быстрее.

Второе новшество — вывод сигнальных линий и линий питания с разных сторон подложки чипа. В более ранних техпроцессах оба вида линий находятся с ее фронтальной стороны. Новое решение под названием PowerVia заключается в переносе линий питания на обратную сторону подложки. Так как линии питания больше не мешают сигнальным, для последних можно упростить разводку и уменьшить длину соединений. А за счет отсутствия прямых наводок от питания и помех для сигналов становится меньше.
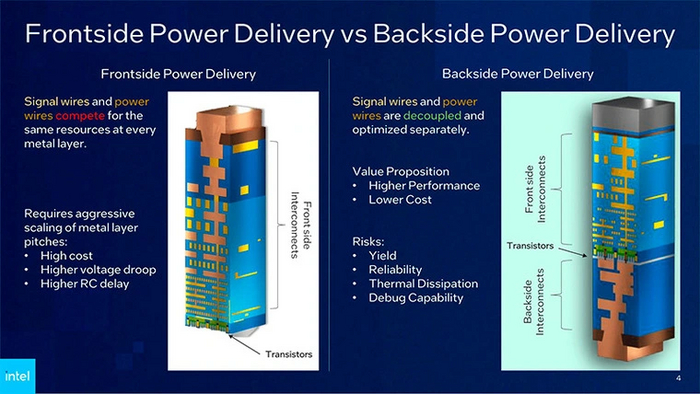
Проводники питания можно сделать большего сечения для использования повышенных токов, а плотность размещения транзисторов — увеличить. Благодаря такому сочетанию новые процессоры наверняка смогут достигать более высоких частот. Производительность на ватт по сравнению с техпроцессом Intel 3 возрастет до 15 %.
Следующее поколение техпроцесса представляет собой усовершенствованную версию Intel 20A. В него перекочуют все новшества предшественника. Intel 18A — техпроцесс, соответствующие условным 18 ангстрем, или 1.8 нм. По сравнению с Intel 20A, он позволит увеличить показатель производительности на ватт на величину до 10 %.
Как признался глава Intel, именно на этот техпроцесс он сделал наибольшую ставку. Intel 18A должен вернуть компании лидерство в передовых технологиях производства, а также стать наиболее массово использующимся техпроцессом. На Intel 20A компания намерена обкатать технологии RibbonFET и PowerVia, поэтому он будет использоваться только в процессорах Core. А на базе 18A будут выпускаться и серверные Xeon нового поколения, и чипы, разработанные сторонними компаниями-заказчиками — к примеру, мобильные решения на архитектуре ARM.

Среди продукции компании первой на вооружение этот техпроцесс возьмут новые процессоры Xeon под кодовым названием Clearwater Forest. Это второе поколение разновидности Xeon на базе энергоэффективных ядер. В нем впервые будет применена технология Foveros Direct, которая позволит связывать кристаллы-плитки с помощью соединений гораздо меньшего размера, чем ранее.
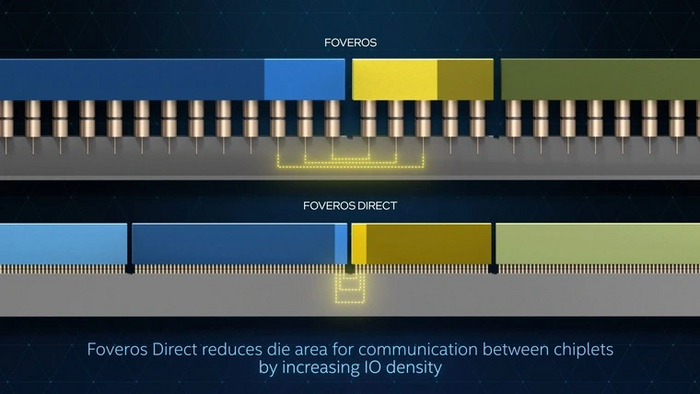
Следом за Xeon технология производства найдет приют в процессорах Core под кодовым названием Lunar Lake. Это произойдет в конце 2024 или начале 2025 года. Как и Meteor Lake, эта линейка процессоров предназначена исключительно для ноутбуков. В десктопы новый техпроцесс попадет только в середине 2025 года с приходом процессоров Core под кодовым названием Panther Lake.
В 2027 году в массовое производство будет запущен Intel 14A. Ключевое отличие от предшественников в том, что он станет первым техпроцессом, при производстве которого будет использоваться литография в сверхжестком ультрафиолете с высокой числовой апертурой (High-NA EUV). Это потребует нового оборудования для производства, поэтому на первых порах ждать бюджетных продуктов на базе 14A не стоит.
Как и в предшественниках, в Intel 14A будут использоваться транзисторы RibbonFET, а технология PowerVia второго поколения сможет обеспечить лучшие параметры питания. Intel планирует две разновидности этого техпроцесса: стандартную 14A и улучшенную 14A-E, которая увидит свет позже. Таким образом компания хочет продлить жизненный цикл технологии без перехода на новый процесс производства. Доработанные версии получат также Intel 18A и Intel 3.

Компания пока не называет предполагаемое преимущество в производительности на ватт или плотности транзисторов, так как не хочет заранее информировать конкурентов. Поэтому более подробные технические детали 14A станут известны ближе к дате запуска его тестового производства, которое начнется в 2026 году.
Последний техпроцесс Intel, который упоминался ее представителями — Intel 10A. Информации о нем пока немного. Известно, что тестовое производство стартует в конце 2027 года, а готовые продукты появятся не раньше 2028-го.

Аналогично Intel 14A, этот техпроцесс будет использовать литографию High-NA EUV. К тому моменту она станет более зрелой и дешевой в производстве, поэтому стоит ожидать использование 10A и в массовой недорогой продукции.

Среди характеристик видеокарты имеет значение не только мощность графического процессора, но и пропускная способность видеопамяти. На что она влияет, насколько важна, и как формируется?
В любом компьютере два процессора — центральный и графический. Центральный процессор устанавливается в сокет материнской платы и снабжается модулями оперативной памяти, с которыми взаимодействует в процессе работы. Пользователь волен подбирать плату и память к процессору самостоятельно. Для топовых моделей логично брать быструю память с небольшими таймингами и плату с мощной подсистемой питания. Для бюджетных можно обойтись дешевой «материнкой», а также памятью со стандартными частотами и таймингами — на их производительность это повлияет на уровне погрешности.
Видеокарты подразделяются на встроенные и дискретные. Ядро встроенной видеокарты находится внутри центрального процессора. Оно не имеет собственной памяти, и для работы берет часть из системной «оперативки», которую использует и ЦП.
Дискретная видеокарта выполнена в виде отдельной платы, на которой имеется собственная подсистема питания, графический процессор и микросхемы видеопамяти. Это — готовый продукт, где невозможно заменить ни одну из составляющих графической подсистемы, в том числе и память. Из-за особенностей работы графических процессоров тайминги видеопамяти влияют на производительность мало, поэтому практически нигде не упоминаются. А вот что на слуху — так это ширина шины ГП, тип применяемой памяти и ее частота.

В отличие от процессорных платформ, где в массовом сегменте шина памяти у всех моделей ЦП составляет 128 бит, каждый графический процессор обладает собственной шириной шины. У современных моделей она может составлять от 64 до 384 бит. Кроме того, разнятся и типы памяти — GDDR5, GDDR5X, GDDR6 или GDDR6X. Особняком стоят модели с памятью HBM, у которых шина намного шире — 2048 или 4096 бит. Помимо этого, у каждой карты память работает на своей частоте, отличной от частот других моделей.
Как не запутаться во всех этих характеристиках? Неопытные пользователи часто делают акцент на одной из них. «Чем больше разрядность шины, тем лучше!», «GDDR6 быстрее GDDR5!», «Тут частота 14 ГГц, а там намного больше — целых 20!». Данные утверждения верны, но лишь при условии, что прочие переменные подразумеваются одинаковыми. Этого в реальности практически никогда не бывает.
Пропускная способность видеопамяти формируется с учетом ширины шины и скорости работы чипов памяти, которая, в свою очередь, зависит от типа памяти. Рассчитать пропускную способность можно по формуле:
Эффективная частота памяти (ГГц) × разрядность шины памяти (бит) ÷ 8 (бит в байте)
Если говорить простым языком, то разрядность шины памяти — это ширина канала, по которому передаются биты (единицы информации). К примеру, 128-битная шина означает, что по каналу одновременно передается 128 бит информации. Эффективная частота памяти определяет, сколько раз в секунду эта информация может передаваться — 16 ГГц означает, что данные за секунду передаются 16 миллиардов раз.

Итак, 128-битная шина вкупе с памятью на 16 ГГц даст нам следующую пропускную способность:
16 × 128 ÷ 8 = 256 ГБ/c.
Частота в 16 ГГц характерна для памяти GDDR6. Более медленная DDR5 может достигнуть такой же пропускной способности при частоте в 8 ГГц и более широкой шине в 256 бит:
8 × 256 ÷ 8 = 256 ГБ/c.
Поэтому при сравнении видеокарт, в том числе разных поколений, следует учитывать именно пропускную способность памяти (ПСП). То, как она достигается, для оценки быстродействия подсистемы памяти не особо важно.
Чем мощнее графический процессор, тем в более высокой пропускной способности памяти он нуждается. Разрядность шины и тип применяемой памяти закладывается производителем при разработке каждого ГП с учетом его вычислительной мощности, и не подлежит изменению. У пользователя нет возможности повысить пропускную способность памяти, за исключением легкого разгона, почти не влияющего на нее. Поэтому рассуждения в стиле «если бы этой видеокарте ПСП в полтора раза больше» остаются лишь теоретическими.
Однако существуют некоторые видеокарты на одном ГП с полной и урезанной шиной памяти, а также с разными типами памяти, например, GDDR5 и GDDR6. Обратимся к тестам производительности таких моделей, чтобы понять, сколько производительности теряют младшие варианты.
Первый на очереди современный «середнячок» от NVIDIA — GeForce RTX3060. Карта существует в двух вариантах с полностью идентичными ГП, но разной подсистемой памяти. У старшей модели 12 ГБ 192-битной памяти GDDR6 с ПСП 360 ГБ/c. У младшей модели 8 ГБ 128-битной GDDR6 с ПСП 240 ГБ/c.
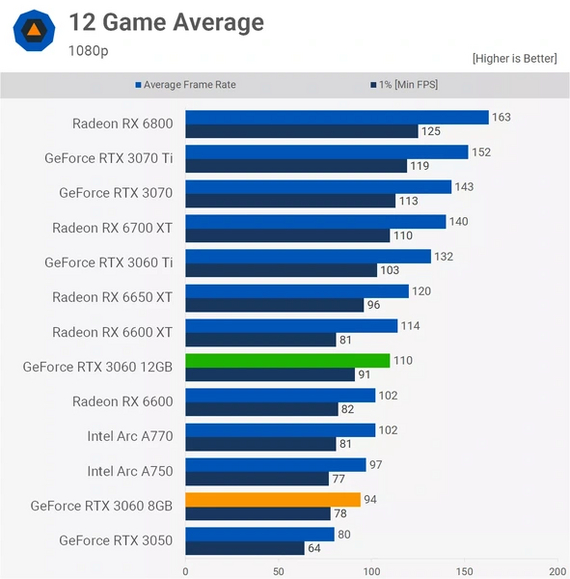
Тестирование проводилось в разрешении 1920×1080, поэтому упора в объем памяти у младшей модели не было. Итак, что мы имеем? Полоса пропускания памяти по сравнению со старшим вариантом снизилась на 33 %, а средняя производительность — на 15 %. Следуя логике, можно сказать, что ПСП у старшей карты с небольшим запасом, а вот младшей ее недостает.
В качестве второго примера рассмотрим пару не новых, но все еще актуальных карт GeForce: GTX1660 и GTX1660 Super. Они имеют одинаковую вычислительную мощность и 6 ГБ памяти, подключенных к 192-битной шине. Модели отличаются только типом памяти. На обычной GTX1660 установлена GDDR5, а на GTX1660 Super — GDDR6. Соответственно отличается и ПСП: у первой — 192 ГБ/c, у второй — 336 ГБ/c.
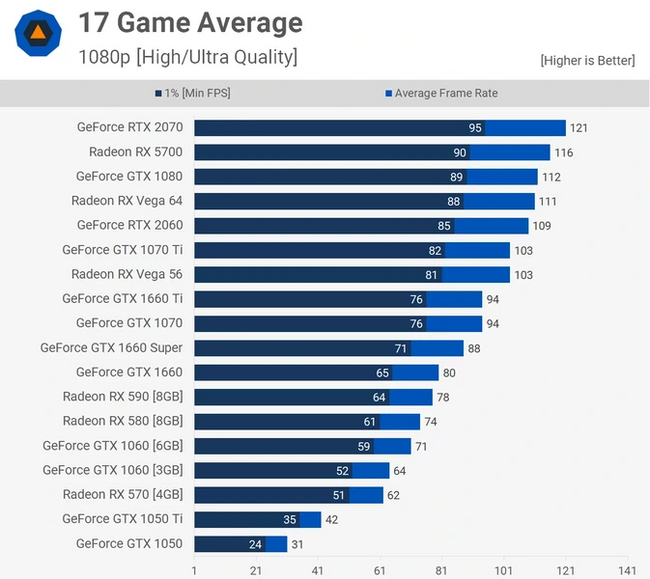
Разница в полосе пропускания между моделями — целых 75 % в пользу GTX1660 Super. Что же показывает тестирование? При такой огромной разнице в ПСП производительность по сравнению с обычным вариантом поднялась всего на 10 %. Из этого можно сделать вывод, что обычной GTX1660 для раскрытия потенциала не хватало пропускной способности лишь самую малость, а 336 ГБ/c для такого графического чипа явно избыточны.
В стане видеокарт AMD последние два поколения не встретить полностью одинаковых ГП с разной пропускной способностью памяти. Однако в позапрошлом поколении такая пара имеется — это Radeon RX5700 и RX5600 XT. У первой 8 ГБ 256-битной GDDR5 с ПСП 448 ГБ/c. У второй — урезанная до 192 бит шина, вследствие чего объем памяти и ПСП сократились до 6 ГБ и 336 ГБ/c соответственно.
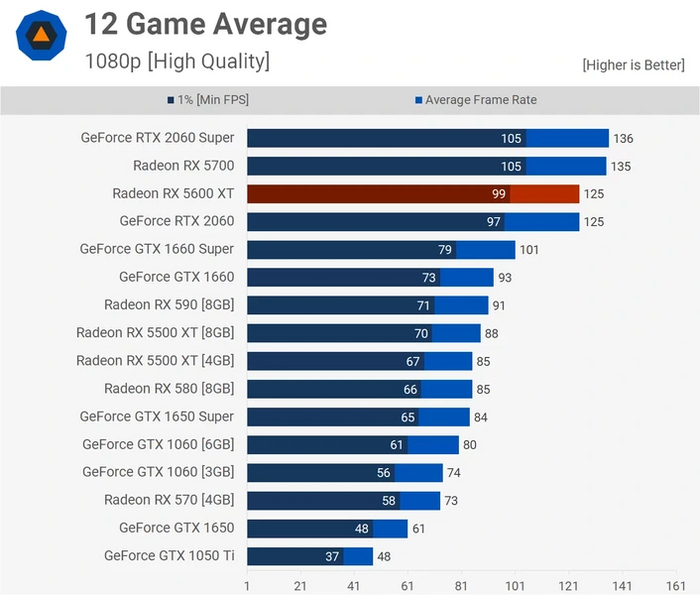
Старшая модель обладает на 33 % большей ПСП, но разница в производительности куда скромнее — на уровне 8 %. И это несмотря на то, что частота ГП у RX5600 XT хоть немного, но меньше. Еще один пример случая, когда огромная ПСП не нужна графическому процессору такого уровня.
Впрочем, бывают и обратные ситуации. Бюджетная Radeon RX6500 XT обладает ПСП в 144 ГБ/c, чего явно недостаточно даже для такого ГП.
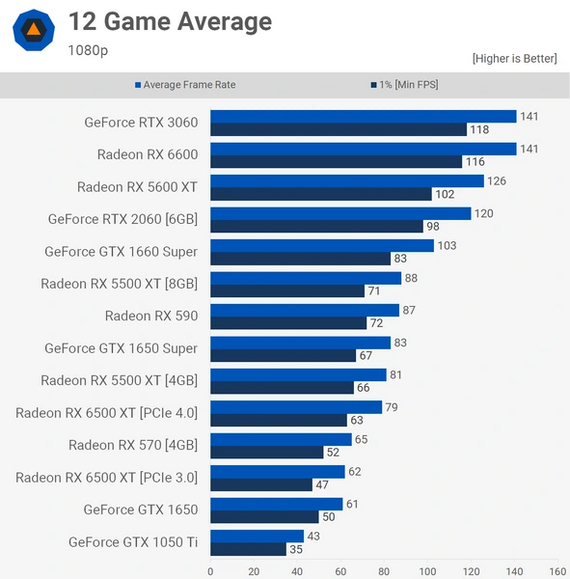
При более высокой вычислительной мощности карта умудряется уступать собственной предшественнице RX5500 XT. Более того, RX6500 XT медленнее даже «старушки» RX590, хотя с учетом разницы производительности между графическими архитектурами GCN и RDNA2 новая карта должна быть быстрее на треть. Но важно помнить, что сама по себе ПСП ничего не решает. Ее более высокое значение не поможет слабой видеокарте стать быстрее. За примером обратимся к популярной GeForce RTX3060 Ti, которая обладает 256-битной шиной и имеет две версии: с памятью GDDR6 и GDDR6X. В первом случае ПСП равна 448 ГБ/c, во втором — 608 ГБ/c.
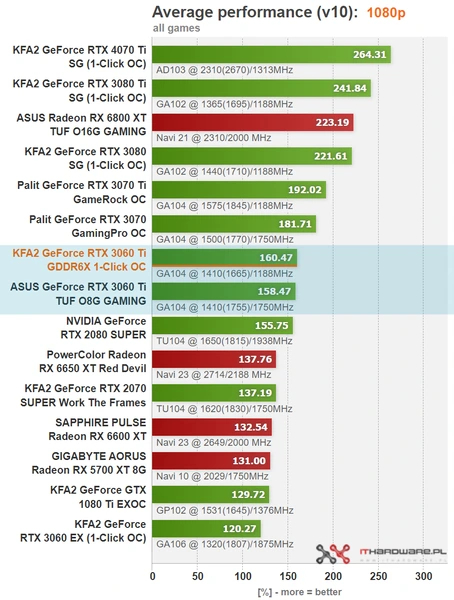
У старшей модели ПСП на 36 % больше, но разница в производительности на уровне погрешности. В редких проектах память GDDR6X дает такому ГП прирост чуть более 5 %, в остальных не наберется и такой разницы.
А вот модели нового поколения GeForce RTX4060 Ti ПСП недостает. По вычислительной мощности карта быстрее RTX3060 Ti на треть, но по реальной скорости обходит предшественницу на 8 %. Виной этому — 128-битная шина памяти GDDR6 со скромной ПСП 288 ГБ/c, что на 36 % меньше, чем у прошлой модели. Хотя и при такой полосе пропускания карта умудряется быть быстрее RTX3060 Ti в среднем, немного отставая лишь в некоторых проектах.
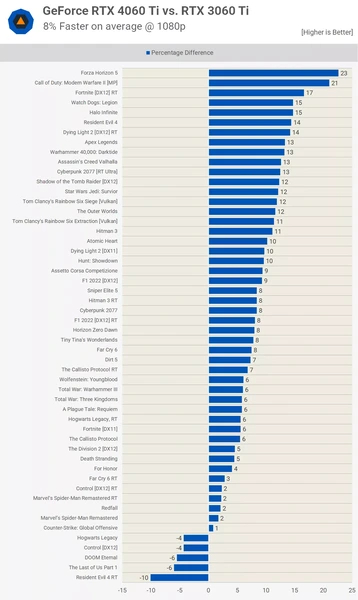
Пропускная способность памяти — один из ключевых параметров видеокарты. Для обычного пользователя неважно, каким путем она достигается, будь то широкая шина или быстрые чипы памяти — важен результат.
Нередки случаи, когда ПСП на определенных моделях карт несбалансированна: где-то выше необходимого, а где-то ниже. От более высокой ПСП вреда не будет. Как, впрочем, и заметной пользы. А вот от ее недостатка возможны потери производительности, которые разнятся от игры к игре: где-то почти неощутимые, а где-то — сразу бросающиеся в глаза.
Дополнительно стоит учитывать, что потери от недостатка полосы пропускания увеличиваются с ростом разрешения. Впрочем, для высоких разрешений видеокарты с несбалансированной ПСП вряд ли будут использоваться, ведь в основном этим страдают бюджетные и средне бюджетные модели. В топовом и пред топовом сегменте почти всегда имеется и широкая шина, и быстрая память. Поэтому недостаток ПСП мощные модели испытывают очень редко.

Новая техника ломается чаще старой и это не парадокс. Не зря говорят — если сразу не сгорело, будет работать сто лет. В сложной технике поломки редко сопровождаются дымом и искрами, из-за чего неисправности будет сложно найти. Оперативная память в компьютере как раз из таких. Эта нахалка будет сыпать ошибками в нагрузке, перезагружать систему или подглючивать в браузере, но никогда не выдаст себя фейерверком. Поэтому есть железные правила, которые помогут понять, почему память работает плохо и как это исправить.
Положить систему на лопатки могут старые комплектующие, сыплющиеся диски или перегретые видеокарты. Но даже техника из магазина попадается с недостатками. Улучшение техпроцесса и качества материалов снижает количество отбраковки, и то, что раньше считалось браком, теперь называется «неудачными» образцами и работает на пониженных частотах.
Тем не менее, иногда и полностью нерабочие экземпляры умудряются пройти контроль качества и попасть в руки покупателю. Это не проблема: производитель заменит неработающее устройство по гарантии. Но испорченные видеофайлы семейного праздника, проигранный бой в сетевом шутере и кракозябры в дипломной работе сервисный центр не обменяет. Поэтому проверять оперативную память — занятие не постыдное.
Будут ошибки в работе или нет — зависит не только от качества ОЗУ, но и от совместимости. Производители сильно упростили сборку и настройку ПК, поэтому вряд ли материнская плата будет конфликтовать с памятью. Тем не менее, каждая модель тестируется на совместимость с большинством модулей памяти. Например, вот часть 100% поддерживаемых комплектов памяти для Asus Maximus XII Hero:
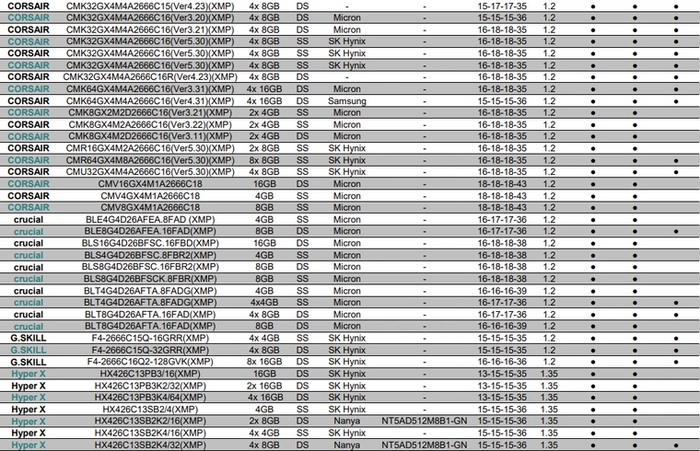
Однако список совместимости не панацея. Современные платы переваривают всевозможные комплекты памяти. Главное, соблюдать эти пункты:
Выключаем разгон памяти. Перед установкой ОЗУ скидываем биос к заводским. Новый комплект отличается от старого и вряд ли заработает на аналогичных настройках.
Выключаем разгон процессора. Если в связке с прошлыми планками разгон процессора был стабилен, то с новыми чипами памяти цифры поменяются.
Учитываем физические ограничения платформ. Подбираем память не только по цене, но и с прицелом на остальные комплектующие. Например, не все модели процессоров одинаково хорошо гонят память. Поэтому для некоторых моделей выше 3600 или 3800 МГц по памяти не прыгнешь. Это относится к Ryzen 3000 серии и старше: частота шины Infinity Fabric не позволит процессору работать выше 1800 или 1900 МГц без делителя и потери мощности. Эти «золотые» частоты зависят от удачности процессора, контроллера, а также ограничений производителя или техпроцесса. С Intel разгон памяти дается легче, но от модели к модели все равно есть ограничения. Так, процессоры верхнего ценового сегмента и модели с разблокированным множителем легче настраивают ОЗУ на частоте 4000 и выше. Бюджетные капризничают на 3600 или 3800 МГц.
Не забываем об ограничениях. Платы на Z-чипсетах для платформы Intel лишены ограничений по частоте памяти. Тем не менее, материнки на H-чипсетах выше 2933 МГц работать не будут, однако менять тайминги разрешается. Для платформы AMD B-чипсеты и X-чипсеты одинаково работают с разгоном.
Разгон памяти — не гарантийный случай. Память стабильно работает с профилем XMP (для Intel) или D.O.C.P (для AMD), но не разгоняется в ручном режиме по частоте или таймингам. Это не поломка, так как разгон свыше заводских значений и профилей не гарантируется производителем. Разгонный потенциал — частный случай для каждой модели.
Обязательно проверяем поддержку заявленных частот. При выборе памяти нужно руководствоваться не только характеристиками, но и поддержкой этих характеристик как самой памятью, так и материнской платой. Для этого лучше обратиться к информации производителя на официальном сайте. Для материнки это будет просто перечень рабочих частот в таком формате:

Поддержка частот самой памятью зависит от модели. Например, на официальном сайте Crucial можно проверить поддержку для каждой планки Ballistix:
Народный метод, предлагающий протереть контакты ОЗУ ластиком
(Конечно если Вы не Ископаемый IT-шник которому по зубам и RJ45 при помощи отвертки на патч-корде обжать!!! РЕСПЕКТ И УВАЖУХА)
Библия IT-шников из 90-х:
1. Вначале было слово, и слово было два байта, а больше ничего не было.
2. И отделил Бог единицу от нуля, и увидел, что это хорошо.
3. И сказал Бог: «Да будут данные, и стало так.»
4. И сказал Бог: «Да соберутся данные каждые в свое место, и создал дискеты и винчестеры, и компакт-диски.»
5. И сказал Бог: «Да будут компьютеры, чтобы было куда пихать дискеты, и винчестеры, и компакты, и сотворил компьютеры, и нарек их хардом, и отделил хард от софта.»
6. Софта же еще не было, но Бог быстро исправился и создал программы большие и маленькие, и сказал им: плодитесь и размножайтесь, и заполняйте всю память.
7. Но надоело Ему создавать программы самому, и сказал Бог: «Создадим программиста по образу и подобию нашему, и да владычествует он над компьютерами и над программами, и над данными.» И создал Бог программиста и поселил его в своем ВЦ, чтобы работал там. И повел Он программиста ко древу каталогов и заповедал: «Из всякого каталога можешь запускать программы, только из каталога Windows не запускай, ибо мастдай.»
8. И сказал Бог: «Нехорошо программисту быть одному, сотворим ему пользователя, соответственно ему.» И взял Он у программиста кость, в коей не было мозга, и создал пользователя, и привел его к программисту, и нарек программист его юзером.
9. Билл был хитрее всех зверей полевых. И сказал Билл юзеру: подлинно ли сказал Бог «не запускайте никакого софта»? И сказал юзер: «Всякий софт мы можем запускать, и лишь из каталога Windows не можем, ибо мастдай.» И сказал Билл юзеру: «Давайте спорить о вкусе устриц с теми, кто их ел! В день, когда запустите Windows, будете как боги, ибо одним кликом мышки сотворите, что угодно.» И увидел юзер, что винды приятны для глаз и вожделенны, потому что делают ненужным знание, и поставил их на свой компьютер; а затем сказал программисту, что это круто, и он тоже поставил.
0A. И отправился программист искать свежие драйверы, и воззвал Бог к программисту и сказал ему: где ты? Программист сказал: «Ищу свежие драйверы, ибо нет их под голым ДОСом». И сказал Бог: «Кто тебе сказал про драйверы? Уж не запускал ли ты винды?» Программист сказал: «Юзер, которого Ты мне дал, сказал, что отныне хочет программы только под винды, и я их поставил». И сказал Бог юзеру: «Что это ты сделал ?» Юзер сказал: «Билл обольстил меня».
0B. И сказал Бог Биллу: «За то, что ты сделал, проклят ты пред всеми скотами и всеми зверями полевыми, и вражду положу между тобою и программистом: он будет ругать тебя нехорошими словами, а ты будешь продавать ему винды.»
0C. Юзеру сказал: «Умножу скорбь твою и истощу кошелек твой, и будешь пользоваться кривыми программами, и не сможешь прожить без программиста, и он будет господствовать над тобой».
0D. Программисту же сказал: «За то, что послушал юзера, прокляты компьютеры для тебя, глюки и вирусы произведут они тебе; со скорбью будешь вычищать их во дни работы твоей; в поте лица своего будешь отлаживать код свой.»
0E. И выслал Бог их из своего ВЦ, и поставил пароль на вход.Не мог не остановиться на данном отступлении. Кто знает тот поймет смысл здесь сказанного!
, — заблуждение и самообман. Вот почему:


Чистить контакты нужно, только если они в таком состоянии, как на фото выше. Если они и так в порядке, ничего протирать не нужно. На новых комплектах из магазина — и подавно. Рядом с контактами на текстолите находятся конденсаторы, которые легко сбить неаккуратными движениями. После такого память даже не придется проверять на ошибки.
Тем не менее, сторонники протирки отмечают, что она частенько решает некоторые проблемы. И дело не в чистоте контактов:
«Чтобы протереть контакты, надо достать планки из разъемов. После протирки вставляем их обратно. В это время в компьютере происходит волшебство: при первом включении новое оборудование вызывает инициализацию, чтобы материнская плата узнала уникальные данные о работе планок памяти. Для ускорения последующих загрузок компьютера они записываются в постоянную память и используются при каждом включении. Так происходит с каждым подключенным к ПК устройством. Следовательно, вытаскивая планки на «протирку», мы обновляем информацию об ОЗУ. Другими словами, материнка заново «тренирует» память. Некоторые программные сбои исчезают как по волшебству».
Стресс-тесты
Проверка памяти на ошибки — затяжное удовольствие. Поэтому перед поиском лучше удостовериться, что проблема в ОЗУ, а не других компонентах. Для этого используют стресс-тесты, которые умеют нагружать железо точечно.
Наиболее популярная программа для тестов — AIDA64:
Аида тестирует процессор, кэш-память процессора, оперативную память, диски и видеокарты. Кремниевая техника привередлива к температурным условиям. Поэтому, чтобы определить, какой элемент в сборке дает сбой, проводится тестирование на рабочей температуре. Тем более, что память подвержена дестабилизации из-за завышенной температуры чипов.
Для прогрева и комплексного тестирования системы на стабильность можно включить OCCT:
Хотя тест написан для проверки стабильности процессора в разгоне, для наших нужд он тоже подойдет. Для создания нагрузки программа использует большой объем оперативной памяти, поэтому если проблемы с ОЗУ есть, в этом стресс-тесте они, скорее всего, проявятся.
Самый надежный и подробный тест стабильности системы — это Prime95:
В автоматическом режиме программа проверяет систему комплексно, нагружая задачами разного объема. Поэтому для точечного тестирования есть шпаргалка. Свой объем задачи для разных узлов:
1344K = тестируется вольтаж процессора;
448K = тестируется вольтаж кэша;
768K = тест контроллеров ввода/вывода и памяти;
800K = проверка оперативной памяти и тестирование вольтажа DRAM;
864K = комплексное тестирование.
Закончив с поиском неисправного компонента и разобравшись, что в некорректной работе компьютера замешана связка процессор + оперативная память, переходим к поиску ошибок. Для этого существует несколько программ, которыми пользуются и обычные пользователи, и специалисты в сервисных центрах.
Кто помнит
MemTest86 — древнейший инструмент для проверки памяти, работает с загрузочной флешки через DOS.
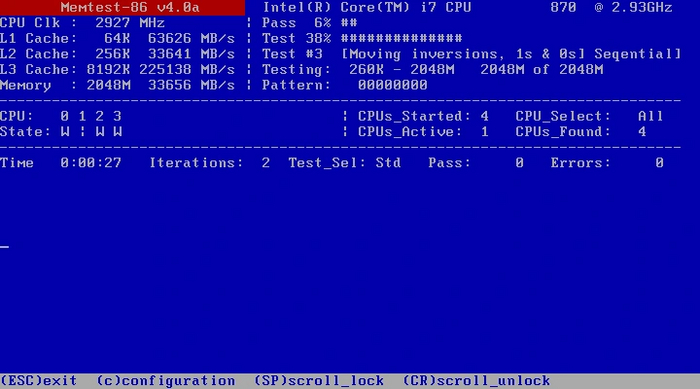
Утилита появилась в 90-х годах, и до сих пор поддерживается разработчиками. Идеальный и единственный вариант для тех, у кого нет операционной системы или она не загружается.
Установка на флешку:
Загружаем установочный файл с официального сайта;
Распаковываем и открываем imageUSB из архива;
Выбираем флешку для установки и ждем окончания записи (флешка форматируется автоматически).
TestMem5 — утилита пришла из мира оверклокинга и пока держится в топе программ по проверке памяти.
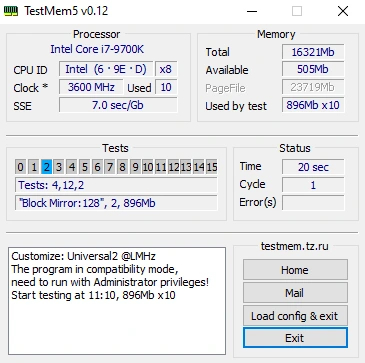
Силами и умами энтузиастов удалось создать такие конфигурационные файлы, что даже бесконечная проверка с помощью MemTest86 не сравнится с часовым прогоном этой утилиты.
Настройка программы:
Скачиваем с официального сайта и распаковываем;
Загружаем конфиг;
Открываем программу от администратора;
Нажимаем Load config & exit, указываем файл конфига;
Заново открываем программу от Администратора, и она автоматически начнет поиск ошибок.
RAM Test Karhu — популярный среди зарубежных оверклокеров тест памяти.
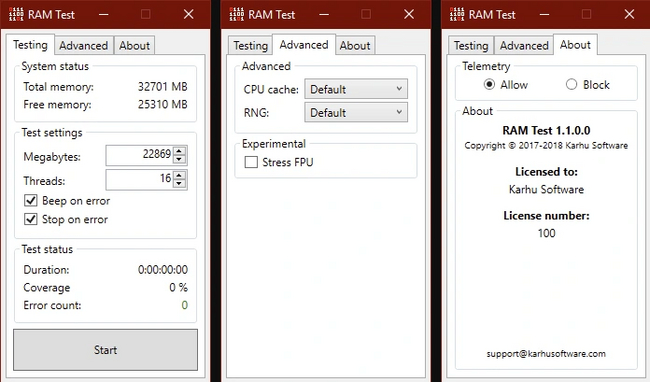
Эта программа быстрее всех тестирует память на ошибки. Показатель стабильности памяти — если Coverage перевалил за 200% с нулем в Error Count. Качество подтверждается лицензией, но истоимость программы составляет почти 10 евро.
Есть также десятки других утилит: Это HCI MemTest, MemTest64, AIDA Memory Test и другие. Но качество их работы не гарантируется.
В современных сборках память комплектуется минимум двумя планками для включения двухканального режима. Поэтому для поиска конкретной планки, которая дает ошибки, придется тестировать каждую поочередно в первом слоте материнской платы. Если ошибок нет — убираем. Затем вставляем другую планку и тестируем ее аналогичным образом.

Продолжаем серию статей посвященных оперативной памяти.
Чтобы разобраться, что такое профиль XMP, нужно понять, как работает компьютер. В частности, как оперативная память влияет на работу процессора, и какие характеристики важны в настройке системы.
В конструкции любой вычислительной машины есть главные и второстепенные комплектующие. Без первых система функционировать не будет. Например, без процессора и оперативной памяти. Однажды получив набор данных с жесткого диска, процессор направляет поток информации в оперативную память для временного хранения и, в основном, пользуется только этими данными. Часть обработанных битов и байтов направляется к видеокарте, чтобы пользователь видел результат работы системы, а остальные возвращаются, обрабатываются процессором и снова записываются в оперативную память. Так происходит чтение, запись и копирование в ОЗУ.
Кто отвечает за скорость
Чтобы избавиться от ограничений, необходимо правильно настроить систему: поднять частоту и снизить тайминги. Тогда оперативная память сможет быстрее принимать и отдавать данные для работы процессора и перестанет сильно ограничивать его вычислительную мощность.
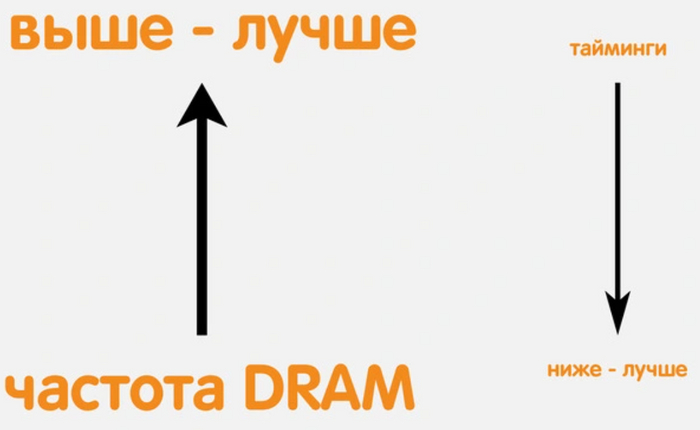
Тактовая частота оперативной памяти отвечает за пропускную способность. Если сравнить с барменом, то это значение указывает на количество помидоров, которое он может загрузить в соковыжималку за раз. В компьютере это мегабайты в секунду. Поэтому пропускная способность памяти — это скорее мощность, нежели скорость. За последнюю отвечают тайминги.
Тайминги — это скорость работы памяти в тактах. Другими словами, это значение времени, за которое оперативная память совершает какое-либо действие. Для бармена это означает скорость, с которой он загружает помидоры. Не количество, а именно скорость — два помидора в минуту или два помидора в секунду. Для компьютера — время, за которое память выполняет один такт. Таким образом, чем ниже значения таймингов, тем лучше для скорости и производительности.
Повышая частоту и снижая тайминги, можно заметно ускорить систему — память научится обрабатывать большие объемы данных за короткий промежуток времени. Самостоятельно настроить оперативную память непросто. Кроме того, что на разгон придется потратить не один десяток часов, стабильность работы ОЗУ после настройки остается на совести юзера. Производители об этом знают, поэтому придумали волшебный XMP.
Вывод: квинтэссенция быстрой памяти — высокая частота и низкие тайминги, а ее целевая аудитория — игровые компьютеры или рабочие станции.
На планках памяти устанавливается микросхема с прошивкой. Производитель вписывает в нее несколько пар в виде «частота/тайминги», из которых компьютер выбирает подходящий режим для стабильной работы системы.

Дело в том, что процессоры поддерживают разную базовую частоту оперативной памяти. Для некоторых моделей это 2400 МГц или 2933 МГц, а флагманские модели семейства Rocket Lake от Intel теперь работают с частотой 3200 МГц. Это значит, что для полноценной работы процессора необходимо подобрать соответствующий комплект памяти, который умеет работать на нужной частоте. А если не умеет, то автоматика самостоятельно подберет из списка пар ближайшую рабочую частоту. Так работает DRAM по стандартам JEDEC или по ГОСТу, если говорить понятно для русскоговорящего обывателя.
Не по ГОСТу
Профиль XMP или DOCP (так его называют в AMD) — это тоже заводской набор правил работы модулей памяти. Но от базовых стандартов его отличают максимальные рабочие настройки. Если JEDEC ограничивает характеристики микросхем на уровне технологии DDR, то XMP — это частный случай для каждой модели, за который отвечает только производитель этого комплекта.
Чем выше частота и ниже тайминги, тем быстрее работает компьютер — за автоматическую настройку этих параметров и отвечают XMP. Характеристики, которые производитель «зашьет» в профиль, могут варьироваться в зависимости от типа чипов, их качества и возможностей. До недавних пор золотой серединой в скорости и стабильности была частота памяти 3600 МГц.
Какой профиль у моих планок, спросите Вы?
Можно быстро узнать, на каких настройках будет работать конкретный комплект памяти. Сейчас почти все модули, особенно с приставкой «игровые», умеют работать на повышенных частотах с XMP-профилем. Об этой характеристике производители говорят в первую очередь — цифры к каждому модулю всегда подробно расписаны:
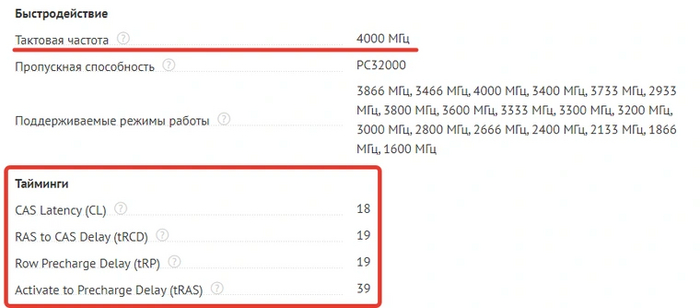
Стандартная частота для DDR4 бывает от 2133 МГц до 3200 МГц. Поэтому все, что выше этих значений, будет работать только как XMP. Информацию о частотных характеристиках можно найти везде: в магазине, на сайте производителя и на упаковке ОЗУ. Словом, мимо не пройдешь.
Какой XMP «лучше»
Существует огромное количество комплектов, которые идентичны по внешнему виду и количеству гигабайт под капотом, но имеют разные профили XMP. Например, часто встречаются пары 3600/CL17 и 3600/CL18. Если обратиться к теории выше, то второй вариант считается медленнее — ведь чем выше тайминг, тем дольше память выполняет работу.
Для «вычисления» производительности любого комплекта «на глаз» можно ассоциировать частоту и тайминги. Если кратко, то модули памяти с тактовой частотой 3600 МГц и первичным таймингом CL16 будут однозначно лучше, чем любой другой с аналогичной частотой, но более высокими таймингами. То же самое можно сказать и про остальные частоты: 4000 на CL17 лучше, чем на CL19. Еще проще — делим частоту на тайминг. Тогда 3600/16 равно 225, а 4000/17 равно 235 — чем больше результирующее число, тем быстрее память. Это сильно упрощенный способ быстро посчитать примерную разницу между настройками памяти, студенты математических ВУЗов и знатоки, конечно, посчитают лучше и точнее.
Вывод: профили XMP призваны облегчить процесс разгона оперативной памяти, но для максимального эффекта нужно обращать внимание не только на частоту, но и на тайминги, которые записаны в прошивку: чем они меньше, тем лучше.
Все комплектующие в компьютере связаны контроллерами и шинами. Поэтому ориентироваться только на показатели в XMP-профиле не получится. Активация заводского профиля разгона хоть и гарантирует стабильность, но не гарантирует работоспособность. Как и в ручном разгоне, компьютер ограничен физическими пределами контроллеров и многими факторами, которые зависят от качества микросхем. Например, не стоит ожидать рекордных возможностей от бюджетной материнской платы и такого же процессора. Современные платформы легко «берут» рубежи в 3600 МГц или 4000 МГц, но экстремальные 4700 МГц и выше доступны только топовому железу.

Работа XMP также зависит от набора логики материнской платы. Для платформы AMD здесь всегда зеленый свет: компания убрала ограничение на разгон процессора и ОЗУ на всех фирменных чипсетах для процессоров Ryzen. Но Intel более консервативны — разгон памяти поддерживается только на платформах с чипсетами серии Z. Это ограничение должны убрать в новых B560, но гарантированную максимальную частоту для таких плат ограничат на 4000 МГц. Это еще один нюанс в совместимости.
Вывод: частота и тайминги в профиле гарантируют стабильность только в одном случае — если такой разгон «потянут» процессор и материнская плата.
Настройка оперативной памяти и любые действия с частотой, таймингами и вольтажом происходят в BIOS. Чтобы зайти в это меню, необходимо сразу после появления загрузочного экрана с логотипом производителя или «бегущими буквами» несколько раз нажать клавишу Delete или F2:
После того, как появится интерфейс BIOS, необходимо найти вкладку, отвечающую за разгон комплектующих. В меню материнских плат ASUS эти функции находятся в разделе Extreme Tweaker:
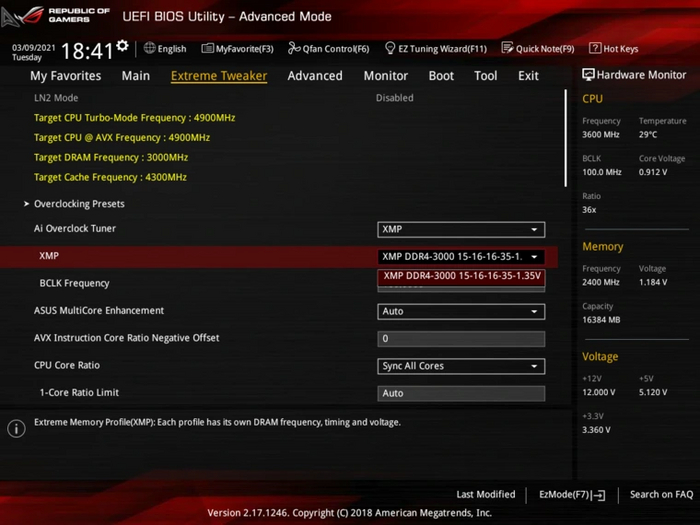
В пункте Ai Overclock Tuner необходимо выбрать строку XMP, чтобы ниже появилось окно с выбором профиля частоты:
После активации профиля переходим к последней вкладке, сохраняем настройки и перезагружаем компьютер:
Система загрузится с примененными параметрами из профиля XMP. Чтобы удостовериться, что настройки активировались, можно открыть утилиту CPU-Z, найти в разделе Memory строку Frequency и умножить значение на два. Если в итоге получится цифра, которая соответствует частоте из профиля, то все работает верно:
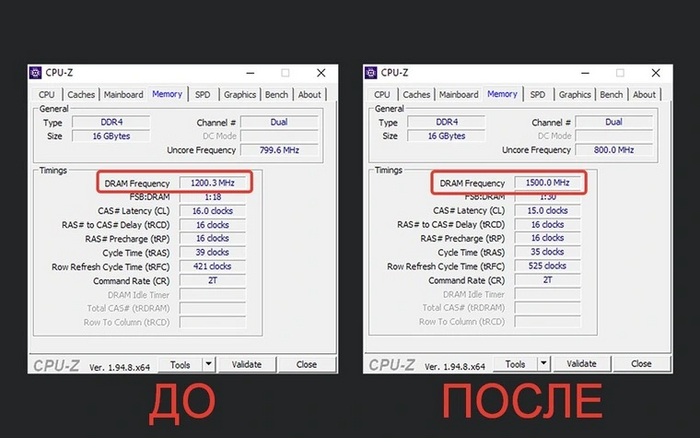
После разгона всегда интересно сравнить, как новые настройки повлияли на производительность. В данном случае планки памяти поддерживают очень низкую частоту в XMP — всего 3000 МГц на достаточно высоких таймингах CL15. Однако даже такой мизерный буст подсистемы памяти показывает прибавку к мощности процессора. Вот, что было на стандартной частоте:
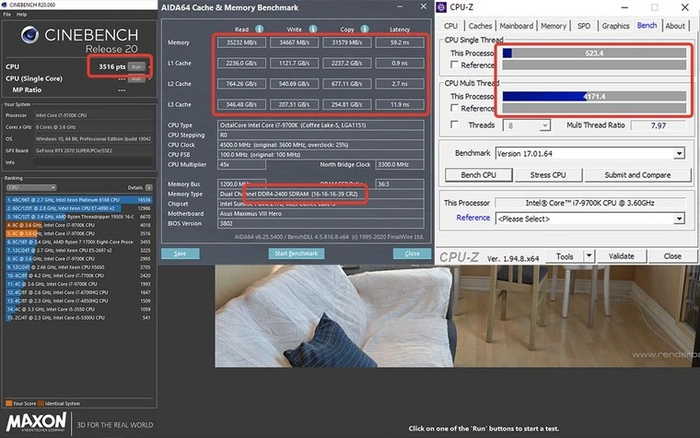
И вот, как изменилась производительность после активации профиля:
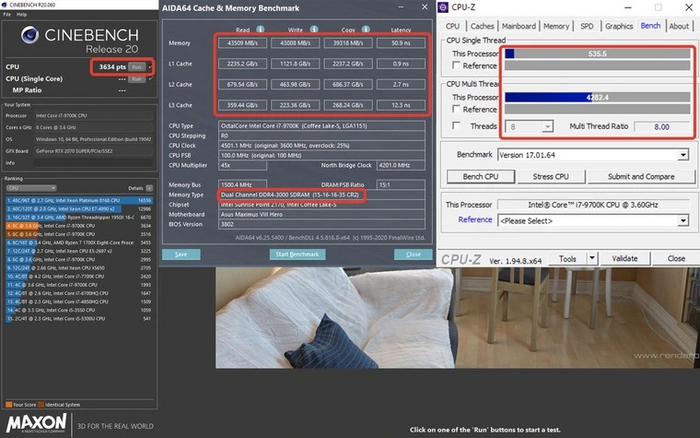
Во всех тестах производительности процессор показывает на несколько процентов больше единиц, хотя он находится в заводском состоянии. И это всего лишь 3000 МГц на «конских» таймингах.
Поиск оперативной памяти — это не только выбор между количеством планок и количеством гигабайт на борту. Кроме базовых характеристик, в этом вопросе теперь участвуют и другие параметры, которые раньше обходили стороной. Когда пользователь пытается выжать максимум из своей сборки, возможность настройки ОЗУ в этом плане играет главную роль. Здесь уместно сказать: пусть это будут 16 быстрых гигабайт, нежели 64 медленных.
Принцип «больше — лучше» здесь не работает. Подбирать XMP-профиль памяти нужно, исходя из возможностей платформы. Например, Ryzen хоть и со скрипом, но гонит память до 3800 МГц без потери производительности. Поэтому рекомендуется искать планки с готовым профилем не выше 3800 МГц, если, конечно, не говорить о ручной настройке. Intel в этом пока лидирует: даже на Coffee Lake без литеры К в названии можно увидеть 4400 МГц и выше.

Оперативная память является неотъемлемым компонентом любой вычислительной системы. Как она устроена внутри, и как работает?
Началось всё очень давно, ещё в ХIХ веке. Именно в 1834 году Чарльз Беббидж разработал конструкцию аналитической машины. В те годы самому Чарльзу не удалось воплотить свою конструкцию в реальную жизнь из-за проблем с финансированием и отсутствием необходимых для постройки технологий.

Упрощённо, данный компьютер состоял из 4-х элементов – арифметико-логического устройства (АЛУ), устройства ввода-вывода, шины передачи данных и оперативной памяти. Как же работала оперативная память в 19 веке? Работала она за счёт сложного массива валов и шестерёнок, положение которых и «записывало» то или иное значение информационной единицы. И после этого изобретения давайте сделаем скачок на более чем 100 лет вперёд, в 40-50-ые годы ХХ века, когда начинались выпускаться электронно-вычислительные машины (ЭВМ) первого поколения.
Так как технология только зарождалась, инженеры экспериментировали с конструкциями и принципами работы ОЗУ. Таким образом, на первых порах использовалась оперативная память, работающая на электромеханических реле, на электромагнитных переключателях, на электростатических трубках и на электро-лучевых трубках. Но спустя пару лет все сошлись на одном варианте, другом – магнитные диски и магнитные барабаны.

По своей структуре магнитные барабаны похожи на современные жёсткие диски. Ключевое отличие – на барабане считывающие головки неподвижны и время доступа полностью определяется скоростью их вращения, в то время как у жёсткого диска это определяется как скоростью вращения, так и скоростью перемещения головок по цилиндрам диска. Следующим этапом развития оперативной памяти стали массивы на ферромагнитных сердечниках, или, как её проще называли, ферритовая память. Такой вид памяти обеспечивал очень высокую скорость доступа по сравнению с магнитными барабанами, но и потреблял он больше электроэнергии.

А самой главной проблемой что магнитных барабанов, что ферритовой памяти были габариты. Именно над исправлением этого недостатка исследователи работали на протяжении более десяти лет. И главный толчок в развитии оперативной памяти дало создание больших интегральных схем БИС), или же микросхем, и уже на них появились всеми нами известные и используемые до сих пор DRAM и SRAM, которые стали постепенно сменять ферритовую память, начиная с 70-ых годов. Какая разница между DRAM и SRAM? Если вкратце, то DRAM хранит бит данных в виде заряда конденсатора, а SRAM хранит бит в виде состояния триггера. DRAM является более экономичным видом памяти с меньшим энергопотреблением, а SRAM может похвастаться меньшим временем доступа за большую стоимость и энергопотребление. В нынешний момент SRAM используется как кэш-память процессора, так что мы подробнее перейдём к DRAM, ведь именно такую память используют при создании оперативной памяти.

Кому будет интересно почитать и освежить память, или подчерпнуть для себя что то новое, есть замечательная статья на просторах ПИКАБУ автора BootSect "История оперативной памяти".
Но давайте вернемся и все таки рассмотрим -
Любая вычислительная система состоит из нескольких компонентов. При этом неважно, где эта система используется — в компьютере, ноутбуке, смартфоне, планшете или даже смарт-часах. Основной принцип работы везде один: данные считываются с медленного накопителя и попадают в более быструю оперативную память. Оттуда их получает очень быстрая кеш-память центрального процессора, которая передает данные на вычислительную часть ЦП.

В компьютерах с этим проще: память для них распространяется в виде модулей формата DIMM, на которых распаяны микросхемы памяти. В ноутбуках можно встретить как более компактные модули SO-DIMM, так и распаянную ОЗУ.

Внутри микросхем памяти находится несколько слоев, соединенных друг с другом. Каждый из них разделен на кластеры, в которых находятся ячейки памяти, хранящие информацию.

Ячейка памяти состоит из конденсатора и полевого транзистора. Конденсатор может хранить электрический заряд (логическая единица) или находиться в состоянии без заряда (логический ноль). Таким образом каждая ячейка хранит один бит информации.
Транзистор выступает в роли своеобразной двери. Когда «дверь» закрыта, она удерживает заряд конденсатора. При считывании и записи информации эта «дверь» открывается. Помимо конденсатора, транзистор подключен к двум линиям — линии слов («Word Line», строка) и линии битов («Bit Line», столбец).

Ячейки памяти расположены подобно клеткам шахматной доски. Те, которые находятся на одной линии слов, образуют страницу памяти. Операции чтения и записи производятся не с одной ячейкой, а с целой страницей памяти сразу, так как все транзисторы ячеек на одной линии слов открываются одновременно. Для операции чтения на одну линию слов подается управляющее напряжение, которое открывает все транзисторы ячеек на ней. На концах линий битов находятся усилители чувствительности (Sense Amplifier). Они распознают наличие или отсутствие заряда в конденсаторах ячеек памяти, таким образом считывая логическую единицу или логический ноль.
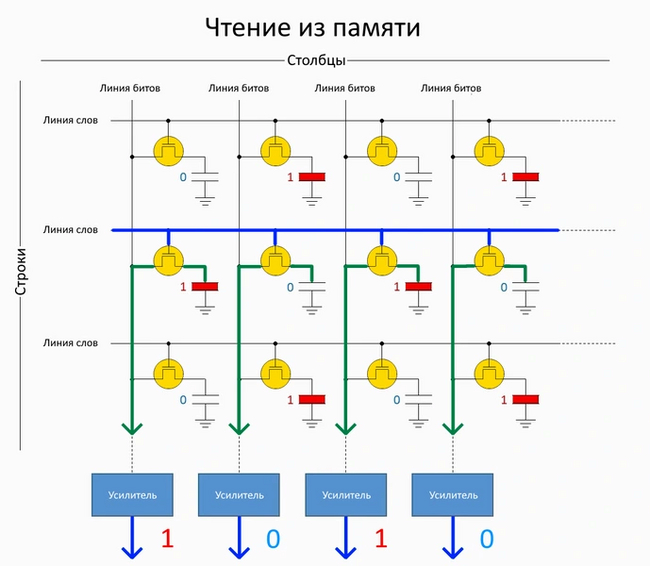
Конденсаторы ячеек имеют маленькие размеры и очень быстро теряют заряд. Поэтому независимо от того, нужно ли сохранять в памяти текущую информацию или записать новую, ячейки периодически перезаписываются.
Для этого, как и при чтении, управляющее напряжение подается на «двери» транзисторов ячеек по линии слов. А вот по линии битов вместо считывания производится процесс записи. Он осуществляется с помощью подачи напряжения для заряда конденсаторов нужных ячеек — то есть только тех, где должна быть логическая единица.
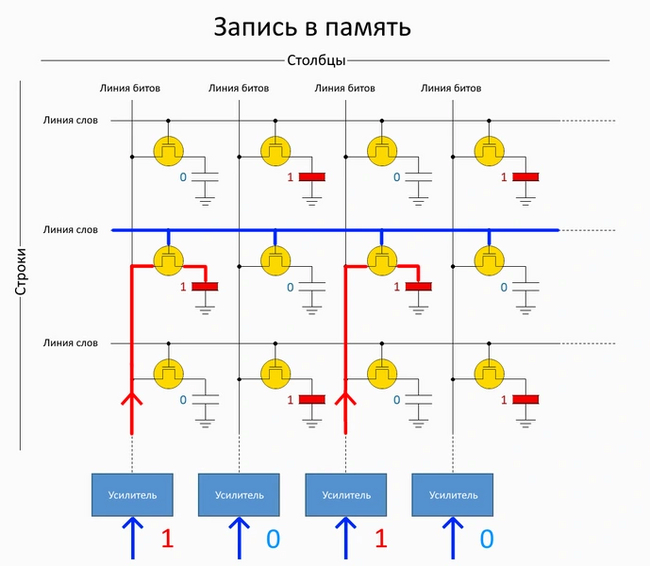
Работа линий координируется декодером адресов строк и мультиплексором столбцов. Информация для записи в ОЗУ поступает в общий буфер данных. Оттуда она попадает в мультиплексор и в его собственный буфер, а затем — в управляющую логику, которая координирует работу ячеек памяти с учетом латентности памяти.
Данные из логики поступают в буфер декодера адресов строк, а оттуда и на сам декодер, позволяя своевременно открывать страницы памяти для операций чтения и записи. При чтении данные вновь проходят через мультиплексор и общий буфер данных, который передает их системе.
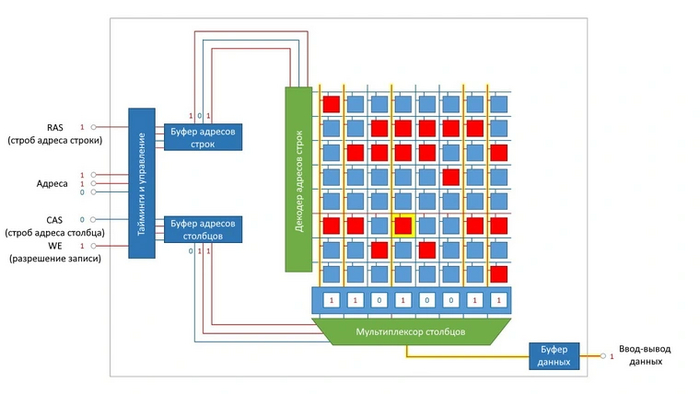
Операции декодера адреса строки и мультиплексора столбцов требуют определенных периодов времени — стробов. Строб адресов строк обозначается как RAS, адресов столбцов — как CAS. Данными характеристиками и их соотношениями определяется латентность памяти, или тайминги. Тайминги — это временные задержки между выполнением команд чтения и записи. Чем они ниже, тем быстрее работает память при прочих равных.
Тайминги выражаются не в абсолютном, а в относительном числовом значении. Оно показывает количество тактовых циклов, которое требуется памяти на выполнение операций. Или, если простым языком, во сколько раз медленнее производится та или иная операция относительно задержки передачи данных. Именно поэтому одни и те же модули ОЗУ имеют разные тайминги на разных частотах.
Для простого примера возьмем распространенную ОЗУ DDR4 с частотой 3200 МГц. Время передачи одного бита информации у нее составляет 1/3 200 000 долю секунды, или 0.3125 нс. Так как память типа DDR передает данные дважды за такт, длительность одного цикла передачи данных занимает в два раза больше времени — 0.625 нс. При тайминге, равном 16, определенная операция будет происходить за время, которое в 16 раз больше этого значения: 0.625 x 16 = 10 нс.

Основные виды таймингов — это:
СL (CAS Latency)
Количество тактов между получением команды чтения/записи и ее выполнением.
tRCD (RAS to CAS delay)
Количество тактов между открытием строки и началом выполнения операции чтения/записи по столбцу.
tRP (RAS Precharge Time)
Количество тактов между получением команды закрытия одной строки и открытием следующей.
tRAS (RAS Active Time)
Количество тактов, в течение которых строка памяти может быть доступна для чтения/записи.
CMD (Command Rate)
Количество тактов с момента активации чипа памяти до готовности принять команду.
Работа памяти, вопреки стереотипу, измеряется не только герцами. Быстроту памяти принято измерять в наносекундах. Все элементы памяти работают в наносекундах. Чем чаще они разряжаются и заряжаются, тем быстрее пользователь получает информацию. Время, за которое банки должны отрабатывать задачи назвали одним словом — тайминг (timing — расчет времени, сроки). Чем меньше тактов (секунд) в тайминге, тем быстрее работают банки.
Такты. Если нам необходимо забраться на вершину по лестнице со 100 ступеньками, мы совершим 100 шагов. Если нам нужно забраться на вершину быстрее, можно идти через ступеньку. Это уже в два раза быстрее. А можно через две ступеньки. Это будет в три раза быстрее. Для каждого человека есть свой предел скорости. Как и для чипов — какие-то позволяют снизить тайминги, какие-то нет.

Теперь, что касается частоты памяти. В работе ОЗУ частота влияет не на время, а на количество информации, которую контроллер может утащить за один подход. Например, в кафе снова приходит клиент и требует томатный сок, а еще виски со льдом и молочный коктейль. Бармен может принести сначала один напиток, потом второй, третий. Клиент ждать не хочет. Тогда бармену придется нести все сразу за один подход. Если у него нет проблем с координацией, он поставит все три напитка на поднос и выполнит требование капризного клиента.
Аналогично работает частота памяти: увеличивает ширину канала для данных и позволяет принимать или отдавать больший объем информации за один подход.
Соответственно, частота и тайминги связаны между собой и задают общую скорость работы оперативной памяти. Чтобы не путаться в сложных формулах, представим работу тандема частота/тайминги в виде графического примера:

Разберем схему. В торговом центре есть два отдела с техникой. Один продает видеокарты, другой — игровые приставки. Дефицит игровой техники довел клиентов до сумасшествия, и они готовы купить видеокарту или приставку, только чтобы поиграть в новый Assassin’s Creed. Условия торговли такие: зона ожидания в отделе первого продавца позволяет обслуживать только одного клиента за раз, а второй может разместить сразу двух. Но у первого склад с видеокартами находится в два раза ближе, чем у второго с приставками. Поэтому он приносит товар быстрее, чем второй. Однако, второй продавец будет обслуживать сразу двух клиентов, хотя ему и придется ходить за товаром в два раза дальше. В таком случае, скорость работы обоих будет одинакова. А теперь представим, что склад с приставками находится на том же расстоянии, что и у первого с видеокартами. Теперь продавец консолей начнет работать в два раза быстрее первого и заберет себе большую часть прибыли. И, чем ближе склад и больше клиентов в отделе, тем быстрее он зарабатывает деньги.
Так, мы понимаем, как взаимодействует частота с таймингами в скорости работы памяти.
Очередь — это пользователь, который запрашивает информацию из оперативной памяти.
Продавец — это контроллер памяти (который доставляет информацию).
Техника со склада — это информация для пользователя. Прилавок — это пропускная способность памяти в герцах (частота).
Расстояние до склада — тайминги (время, за которое контроллер найдет информацию по запросу).
Соответственно, чем меньше метров проходит контроллер до банок с электрическим зарядом, тем быстрее пользователь получает информацию. Если частота памяти позволяет доставить больше информации при том же расстоянии, то скорость памяти возрастает. Если частота памяти тянет за собой увеличение расстояния до банок (высокие тайминги), то общая скорость работы памяти упадет.
Сравнить скорость разных модулей ОЗУ в наносекундах можно с помощью формулы: тайминг*2000/частоту памяти. Так, ОЗУ с частотой 3600 и таймингами CL14 будет работать со скоростью 14*2000/3600 = 7,8 нс. А 4000 на CL16 покажет ровно 8 нс. Выходит, что оба варианта примерно одинаковы по скорости, но второй предпочтительнее из-за большей пропускной способности. В то же время, если взять память с частотой 4000 при CL14, то это будет уже 7 нс. При этом пропускная способность станет еще выше, а время доставки информации снизится на 1 нс.
Вот, как выглядят тайминги на самом деле:
В теории, оперативная память имеет скорость в наносекундах и мегабайтах в секунду. Однако, на практике существует не один десяток таймингов, и каждый задает время на определенную работу в микросхеме.
Они делятся на первичные, вторичные и третичные. В основном, для маркетинговых целей используется группа первичных таймингов. Их можно встретить в характеристиках модулей. Их намного больше и каждый за что-то отвечает. Здесь бармен с томатным соком не поможет, но попробуем разобраться в таймингах максимально просто.
Микросхемы памяти можно представить в виде поля для игры в морской бой или так:
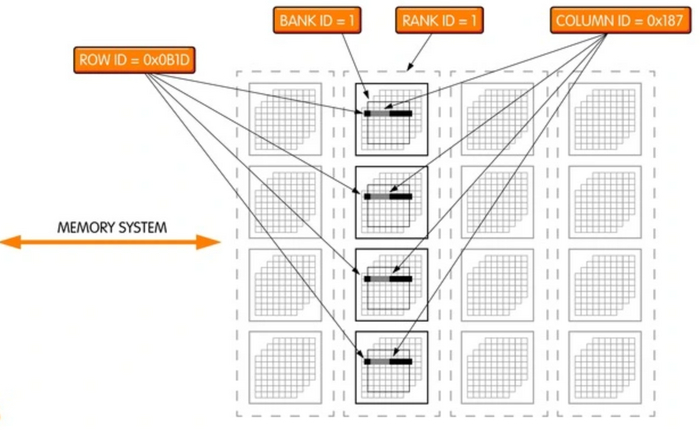
В самом упрощенном виде иерархия чипа это: Rank — Bank — Row — Column. В ранках (рангах) хранятся банки. Банки состоят из строк (row) и столбцов (column). Чтобы найти информацию, контроллеру необходимо иметь координаты точки на пересечении строк и столбцов. По запросу, он активирует нужные строки и находит информацию. Скорость такой работы зависит от таймингов.
CAS Latency (tCL) — главный тайминг в работе памяти. Указывает время между командой на чтение/запись информации и началом ее выполнения.
RAS to CAS Delay (tRCD) — время активации строки.
Row Precharge Time (tRP) — прежде чем перейти к следующей строке в этом же банке, предыдущую необходимо зарядить и закрыть. Тайминг обозначает время, за которое контроллер должен это сделать.
Row Active Time (tRAS) — минимальное время, которое дается контроллеру для работы со строкой (время, в течение которого она может быть открыта для чтения или записи), после чего она закроется.
Command Rate (CR) — время до активации новой строки.
Второстепенные тайминги не так сильно влияют на производительность, за исключением пары штук. Однако, их неправильная настройка может влиять на стабильность памяти.
Write Recovery (tWR) — время, необходимое для окончания записи данных и подачи команды на перезарядку строки.
Refresh Cycle (tRFC) — период времени, когда банки памяти активно перезаряжаются после работы. Чем ниже тайминг, тем быстрее память перезарядится.
Row Activation to Row Activation delay (tRRD) — время между активацией разных строк банков в пределах одного чипа памяти.
Write to Read delay (tWTR) — минимальное время для перехода от чтения к записи.
Read to Precharge (tRTP) — минимальное время между чтением данных и перезарядкой.
Four bank Activation Window (tFAW) — минимальное время между первой и пятой командой на активацию строки, выполненных подряд.
Write Latency (tCWL) — время между командой на запись и самой записью.
Refresh Interval (tREFI) — чтобы банки памяти работали без ошибок, их необходимо перезаряжать после каждого обращения. Но, можно заставить их работать дольше без отдыха, а перезарядку отложить на потом. Этот тайминг определяет количество времени, которое банки памяти могут работать без перезарядки. За ним следует tRFC — время, которое необходимо памяти, чтобы зарядиться.
Эти тайминги отвечают за пропускную способность памяти в МБ/с, как это делает частота в герцах.
Отвечают за скорость чтения:
tRDRD_sg
tRDRD_dg
tRDRD_dr — используется на модулях с двусторонней компоновкой чипов
tRDRD_dd — для систем, где все 4 разъема заняты модулями ОЗУ
Отвечают за скорость копирования в памяти (tWTR):
tRDWR_sg
tRDWR_dg
tRDWR_dr — используется на модулях с двусторонней компоновкой чипов
tRDWR_dd — для систем, где все 4 разъема заняты модулями ОЗУ
Влияют на скорость чтения после записи (tRTP):
tWRRD_sg
tWRRD_dg
tWRRD_dr — используется на модулях с двусторонней компоновкой чипов
tWRRD_dd — для систем, где все 4 разъема заняты модулями ОЗУ
А эти влияют на скорость записи:
tWRWR_sg
tWRWR_dg
tWRWR_dr — используется на модулях с двусторонней компоновкой чипов
tWRWR_dd — для систем, где все 4 разъема заняты модулями ОЗУ
Итак, мы разобрались, что задача хорошей подсистемы памяти не только в хранении и копировании данных, но и в быстрой доставке этих данных процессору (пользователю). Будь у компьютера хоть тысяча гигабайт оперативной памяти, но с очень высокими таймингами и низкой частотой работы, по скорости получится уровень неплохого SSD-накопителя. Но это в теории. На самом деле, любая доступная память на рынке как минимум соответствует требованиям JEDEC. А это организация, которая знает, как должна работать память, и делает это стандартом для всех. Аналогично ГОСТу для колбасы или сгущенки.

Стандарты JEDEC демократичны и современные игровые системы редко работают на таких низких настройках. Производители оставляют запас прочности для чипов памяти, чтобы компании, которые выпускают готовые планки оперативной памяти могли немного «раздушить» железо с помощью разгона. Так, появились заводские профили разгона XMP для Intel и DOHCP для AMD. Это «официальный» разгон, который даже покрывается гарантией производителя.

Профили разгона включают в себя информацию о максимальной частоте и минимальных для нее таймингах. Так, в характеристиках часто пишут именно возможности работы памяти в XMP режимах. Например, частоте 3600 МГц и CL16. Чаще всего указывают самый первый тайминг как главный.

Чем выше частота и ниже тайминги, тем круче память и выше производительность всей системы.
Модули ОЗУ имеют на борту несколько микросхем памяти. Внешняя ширина шины модуля определенного вида ОЗУ — величина постоянная, но внутреннее устройство зависит от поколения памяти и рангов.
Чипы памяти на обычном одноранговом модуле образуют один блок данных. Доступ к нему осуществляется по каналу определенной ширины. Если у модуля два ранга, то доступ к чипам памяти осуществляется через два таких канала. При четырех рангах — через четыре, при восьми рангах — через восемь. В модулях памяти для обычных компьютеров встречается одно- или двухранговая организация. Количество рангов более двух характерно для серверной ОЗУ.

Внешняя ширина шины модуля во всех случаях остается равной ширине канала доступа к одному рангу. Поэтому центральный процессор системы может обращаться только к одному рангу единовременно. Но пока один ранг модуля передает данные, другие могут подготавливать данные для следующей передачи. Поэтому многоранговая память при прочих равных быстрее, хоть и ненамного.
Ширина внешней шины модуля и одного ранга зависит от поколения и типа оперативной памяти.
Обычная ОЗУ DDR4 (и более старых поколений DDR) имеет ширину в 64 бита. Все биты используются для передачи данных.
Серверная ОЗУ DDR4 (и более старых поколений DDR) имеет ширину в 72 бита. 64 бита используются для передачи данных, 8 бит — для коррекции ошибок.
ОЗУ DDR5 имеет ширину в 80 бит, поделенных на два канала по 40 бит. В каждом канале 32 бита используются для передачи данных, а 8 бит — для коррекции ошибок.
В виду ограничения фотоматериалов
ПРОДОЛЖЕНИЕ СЛЕДУЕТ...
